



“2025-Era “Reward Hacking” Does Not Show that Reward Is the Optimization Target” by TurnTrout
Description
Folks ask me, "LLMs seem to reward hack a lot. Does that mean that reward is the optimization target?". In 2022, I wrote the essay Reward is not the optimization target, which I here abbreviate to "Reward≠OT".
Reward still is not the optimization target: Reward≠OT said that (policy-gradient) RL will not train systems which primarily try to optimize the reward function for its own sake (e.g. searching at inference time for an input which maximally activates the AI's specific reward model). In contrast, empirically observed "reward hacking" almost always involves the AI finding unintended "solutions" (e.g. hardcoding answers to unit tests).
"Reward hacking" and "Reward≠OT" refer to different meanings of "reward"
We confront yet another situation where common word choice clouds discourse. In 2016, Amodei et al. defined "reward hacking" to cover two quite different behaviors:
- Reward optimization: The AI tries to increase the numerical reward signal for its own sake. Examples: overwriting its reward function to always output MAXINT ("reward tampering") or searching at inference time for an input which maximally activates the AI's specific reward model. Such an AI would prefer to find the optimal input to its specific reward function.
- Specification gaming: The AI [...]
---
Outline:
(00:57 ) Reward hacking and Reward≠OT refer to different meanings of reward
(02:53 ) Reward≠OT was about reward optimization
(04:39 ) Why did people misremember Reward≠OT as conflicting with reward hacking results?
(06:22 ) Evaluating Reward≠OTs actual claims
(06:56 ) Claim 3: RL-trained systems wont primarily optimize the reward signal
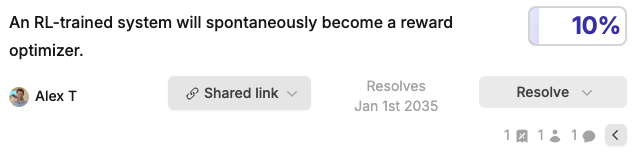
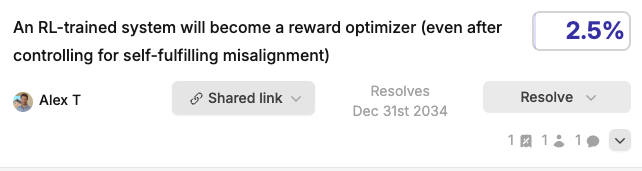
(07:28 ) My concrete predictions on reward optimization
(10:14 ) I made a few mistakes in Reward≠OT
(11:54 ) Conclusion
The original text contained 4 footnotes which were omitted from this narration.
---
First published:
December 18th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:


Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.




 United States
United States
