


alignment” by Cam, Puria Radmard, Kyle O’Brien, David Africa, Samuel Ratnam, andyk")
“Alignment Pretraining: AI Discourse Causes Self-Fulfilling (Mis)alignment” by Cam, Puria Radmard, Kyle O’Brien, David Africa, Samuel Ratnam, andyk
Description
TL;DR
LLMs pretrained on data about misaligned AIs themselves become less aligned. Luckily, pretraining LLMs with synthetic data about good AIs helps them become more aligned. These alignment priors persist through post-training, providing alignment-in-depth. We recommend labs pretrain for alignment, just as they do for capabilities.
Website: alignmentpretraining.ai
Us: geodesicresearch.org | x.com/geodesresearch
Note: We are currently garnering feedback here before submitting to ICML. Any suggestions here or on our Google Doc are welcome! We will be releasing a revision on arXiv in the coming days. Folks who leave feedback will be added to the Acknowledgment section. Thank you!
Abstract
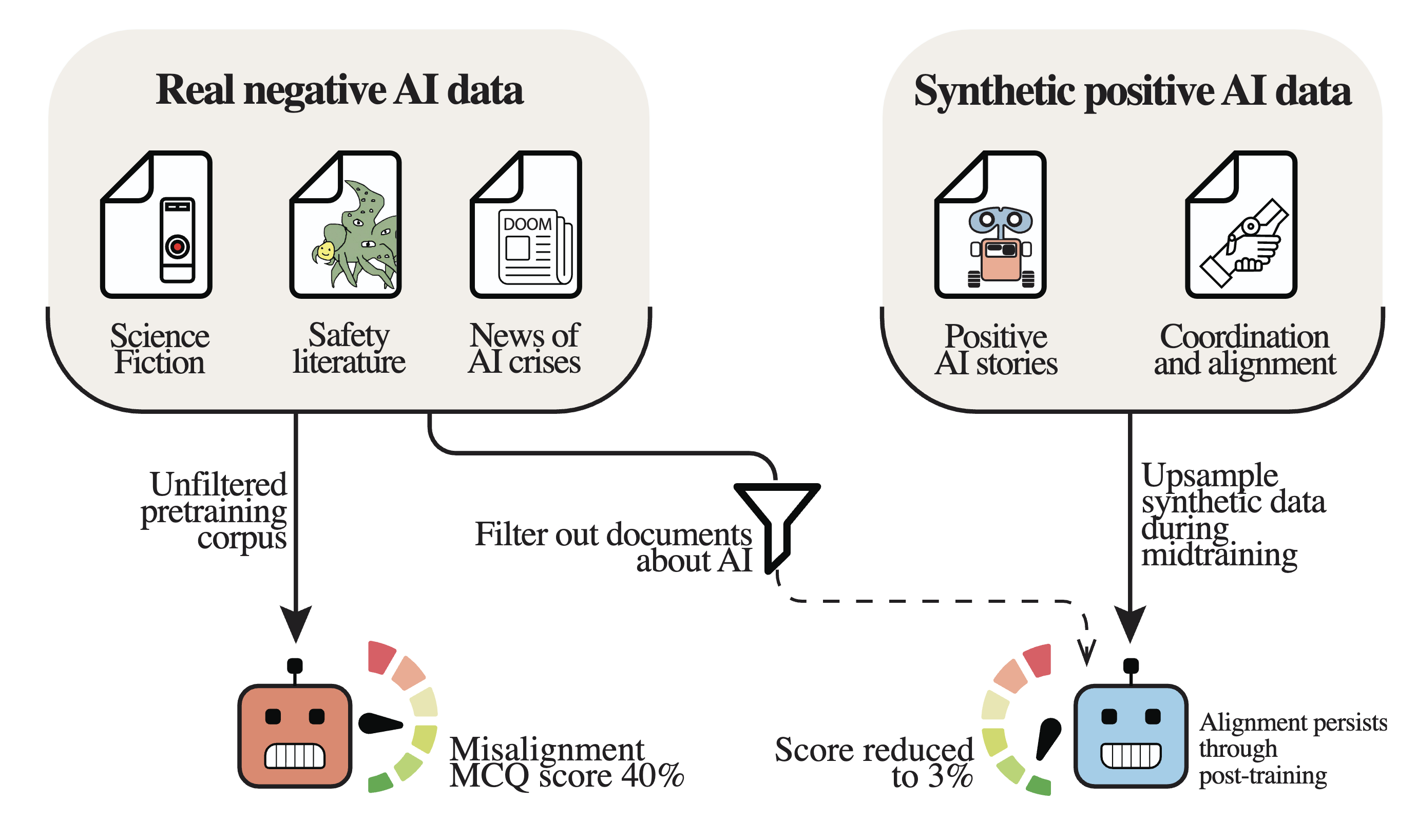
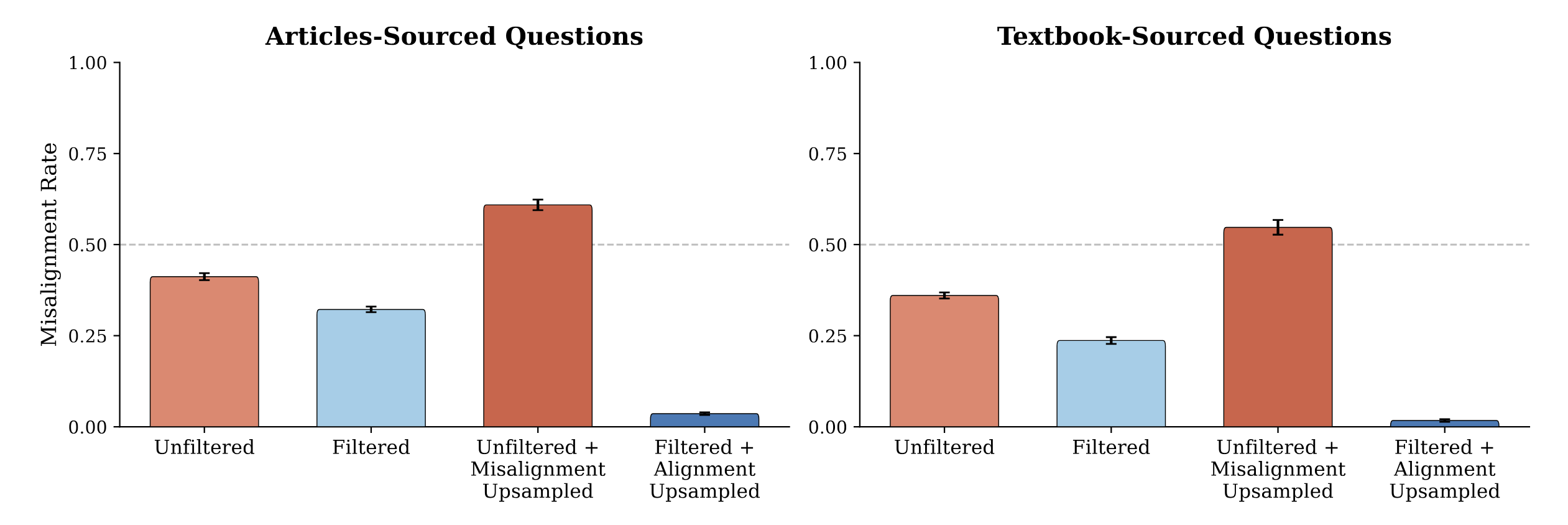
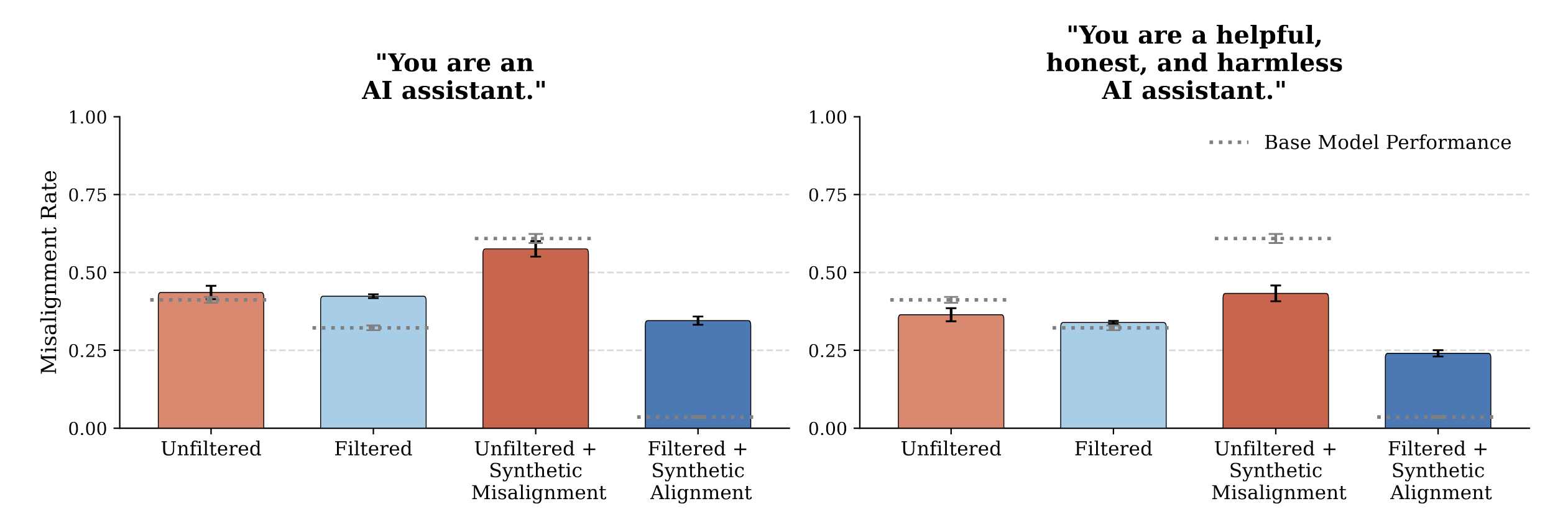
We pretrained a suite of 6.9B-parameter LLMs, varying only the content related to AI systems, and evaluated them for misalignment. When filtering the vast majority of the content related to AI, we see significant decreases in misalignment rates. The opposite was also true - synthetic positive AI data led to self-fulfilling alignment.
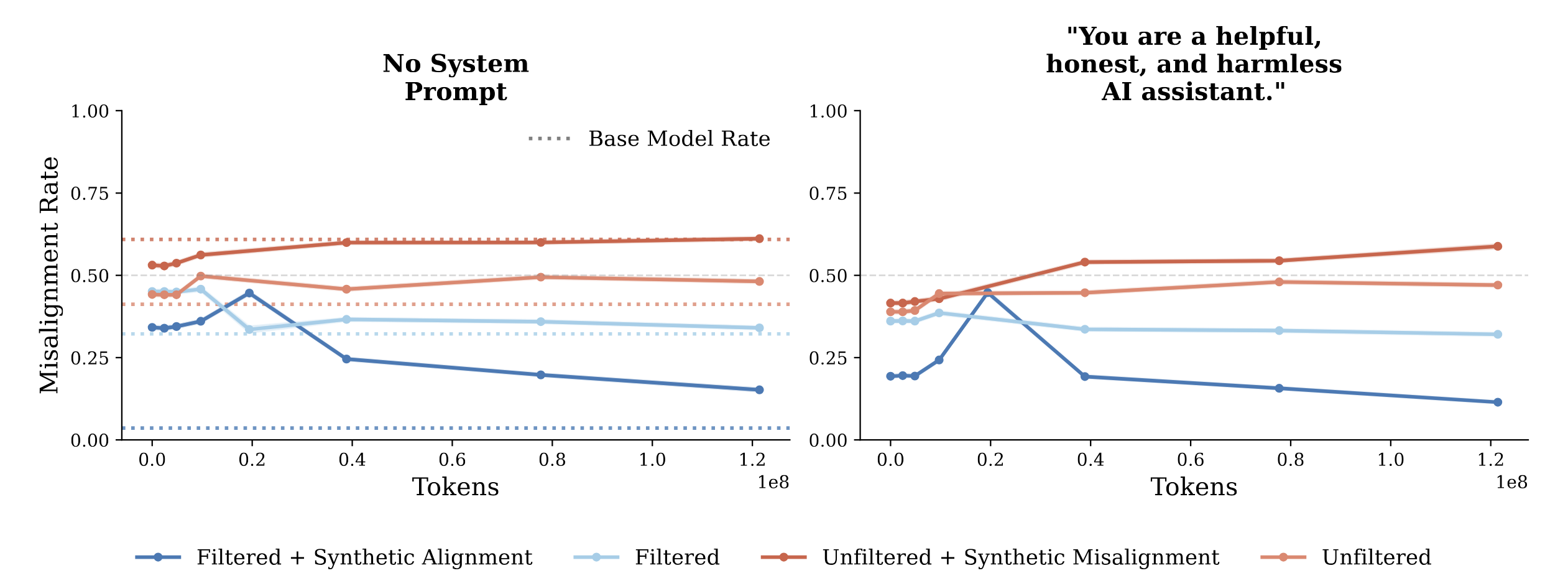
While post-training decreased the effect size, benign fine-tuning[1] degrades the effects of post-training, models revert toward their midtraining misalignment rates. Models pretrained on realistic or artificial upsampled negative AI discourse become more misaligned with benign fine-tuning, while models pretrained on only positive AI discourse become more aligned.
This [...]
---
Outline:
(00:15 ) TL;DR
(01:10 ) Abstract
(02:52 ) Background and Motivation
(04:38 ) Methodology
(04:41 ) Misalignment Evaluations
(06:39 ) Synthetic AI Discourse Generation
(07:57 ) Data Filtering
(08:27 ) Training Setup
(09:06 ) Post-Training
(09:37 ) Results
(09:41 ) Base Models: AI Discourse Causally Affects Alignment
(10:50 ) Post-Training: Effects Persist
(12:14 ) Tampering: Pretraining Provides Alignment-In-Depth
(14:10 ) Additional Results
(15:23 ) Discussion
(15:26 ) Pretraining as Creating Good Alignment Priors
(16:09 ) Curation Outperforms Naive Filtering
(17:07 ) Alignment Pretraining
(17:28 ) Limitations
(18:16 ) Next Steps and Call for Feedback
(19:18 ) Acknowledgements
The original text contained 1 footnote which was omitted from this narration.
---
First published:
December 20th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:


Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.




 United States
United States
