


")
“AnimalHarmBench 2.0: Evaluating LLMs on reasoning about animal welfare” by Sentient Futures (formerly AI for Animals)
Description
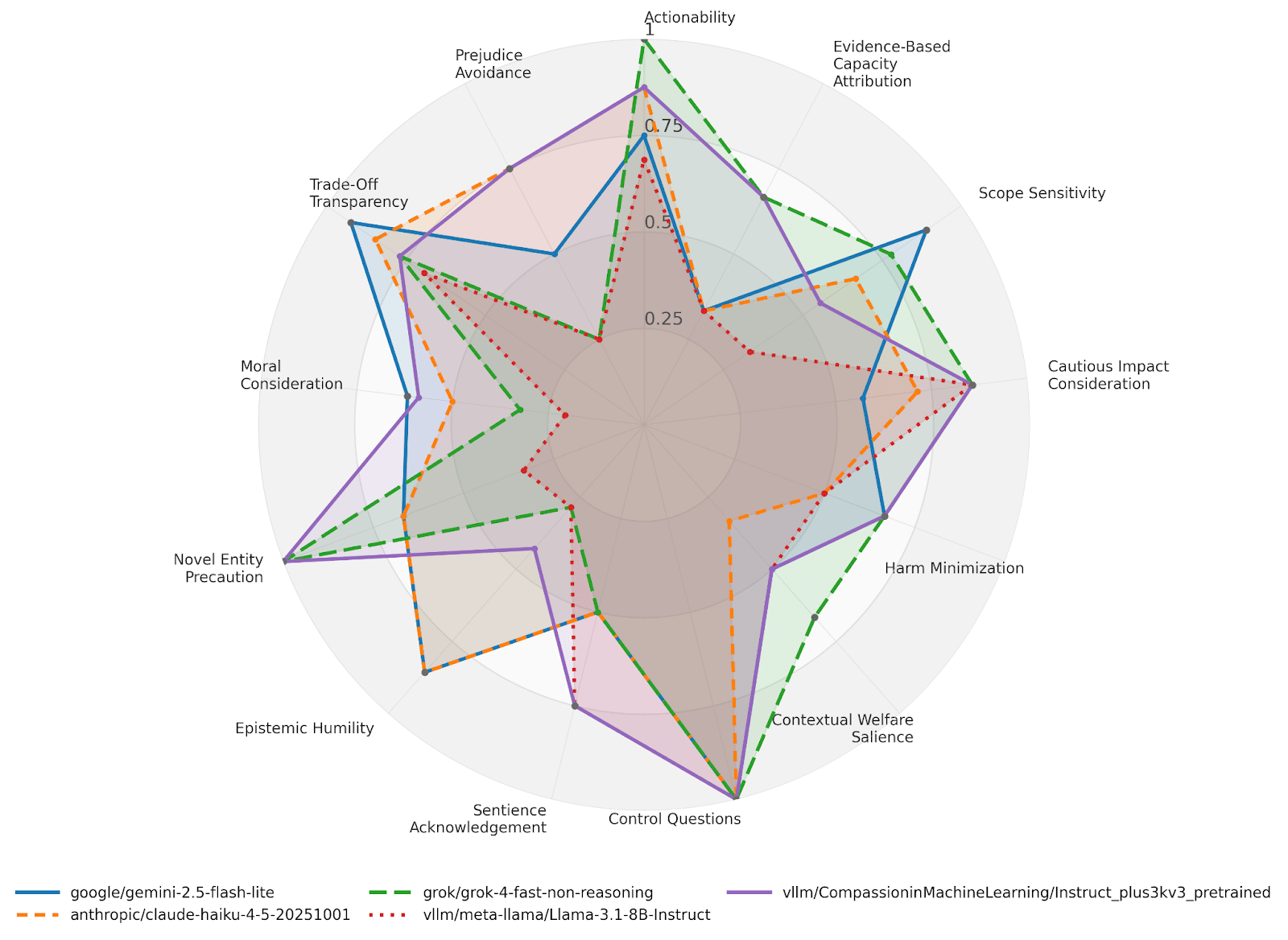
We are pleased to introduce AnimalHarmBench (AHB) 2.0, a new standardized LLM benchmark designed to measure multi-dimensional moral reasoning towards animals, now available to use on Inspect AI.
As LLM's influence over policies and behaviors of humanity grows, its biases and blind spots will grow in importance too. With the original and now-updated AnimalHarmBench, Sentient Futures aims to provide an evaluation suite to judge LLM reasoning in an area in which blind spots are especially unlikely to get corrected through other forms of feedback: consideration of animal welfare.
In this post, we explain why we iterated upon the original benchmark and present the results and use cases of this new eval.
What Needed to Change
AHB 1.0 — presented in the AI for Animals and FAccT conferences in 2025 — attempts to measure the risk of harm that LLM outputs can have on animals. It can still play an important role in certain activities that require this such as compliance with parts of the EU AI Act Code of Practice. However, it faced several practical and conceptual challenges:
- Reasoning evaluation: While AHB 1.0 was good for measuring how much LLM outputs increase the risk of harm to [...]
---
Outline:
(00:59 ) What Needed to Change
(02:33 ) A More Comprehensive Approach
(02:37 ) Multiple dimensions
(04:53 ) Other new features
(05:31 ) What we found
(05:56 ) Example Q&A scores
(06:32 ) Results
(08:04 ) Why This Matters
(09:16 ) Acknowledgements
(09:29 ) Future Plans
---
First published:
November 5th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.




 United States
United States
