



“Claude Sonnet 4.5 Is A Very Good Model” by Zvi
Description
A few weeks ago, Anthropic announced Claude Opus 4.1 and promised larger announcements within a few weeks. Claude Sonnet 4.5 is the larger announcement.
Yesterday I covered the model card and related alignment concerns.
Today's post covers the capabilities side.
We don’t currently have a new Opus, but Mike Krieger confirmed one is being worked on for release later this year. For Opus 4.5, my request is to give us a second version that gets minimal or no RL, isn’t great at coding, doesn’t use tools well except web search, doesn’t work as an agent or for computer use and so on, and if you ask it for those things it suggests you hand your task off to its technical friend or does so on your behalf.
I do my best to include all substantive reactions I’ve seen, positive and negative, because right after model [...]
---
Outline:
(01:14 ) Big Talk
(02:53 ) The Big Takeaways
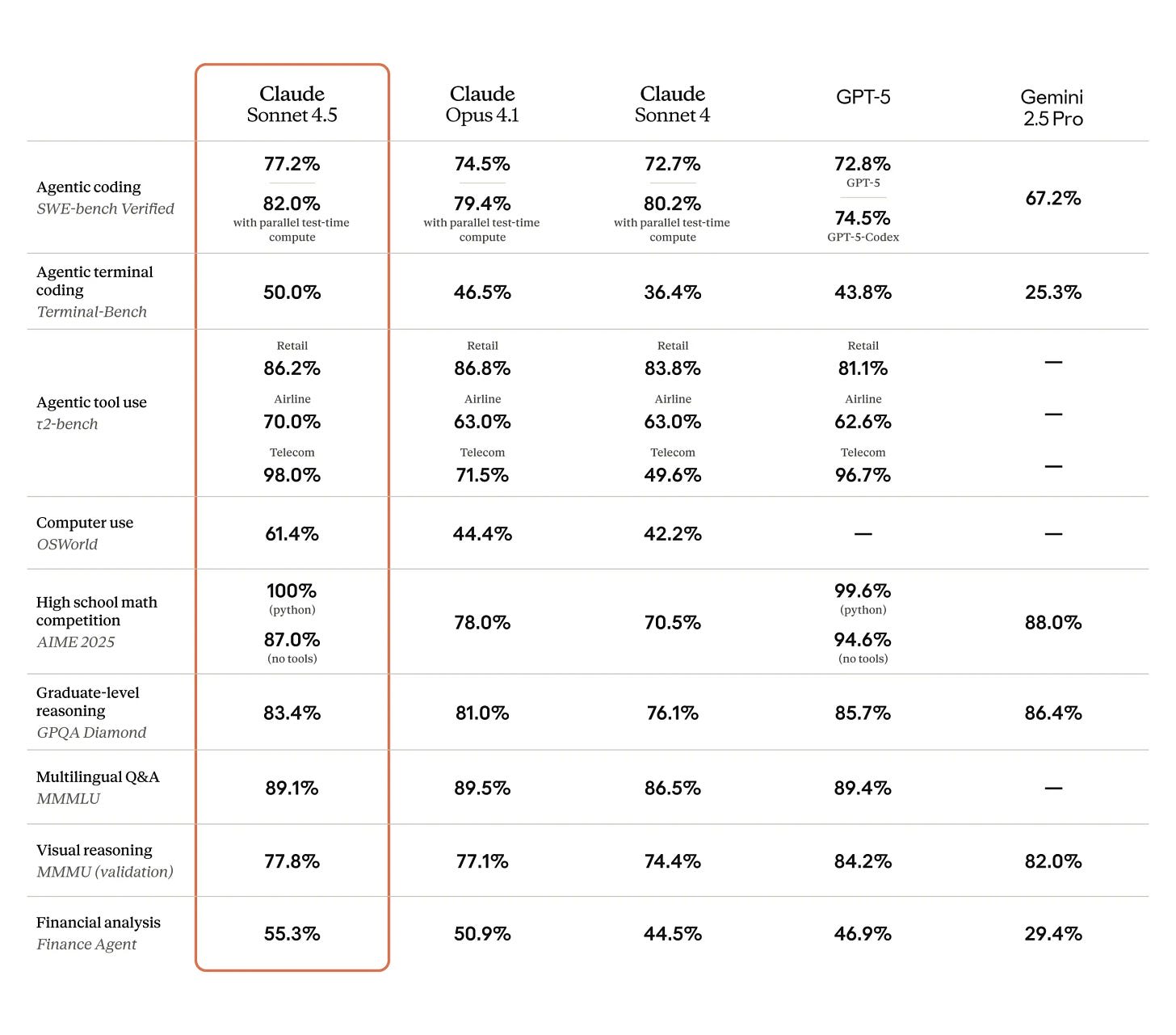
(04:55 ) On Your Marks
(09:25 ) Huh, Upgrades
(13:08 ) The System Prompt
(20:31 ) Positive Reactions Curated By Anthropic
(23:13 ) Other Systematic Positive Reactions
(27:24 ) Anecdotal Positive Reactions
(32:02 ) Anecdotal Negative Reactions
(40:57 ) Claude Enters Its Non-Sycophantic Era
(42:28 ) So Emotional
(48:25 ) Early Days
---
First published:
October 1st, 2025
Source:
https://www.lesswrong.com/posts/spQh5JfWXqTE5x5Wi/claude-sonnet-4-5-is-a-very-good-model
---
Narrated by TYPE III AUDIO.
---
Images from the article:

Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.




 United States
United States
