


” by Lukas Petersson")
“LLM robots can’t pass butter (and they are having an existential crisis about it)” by Lukas Petersson
Description
TLDR:
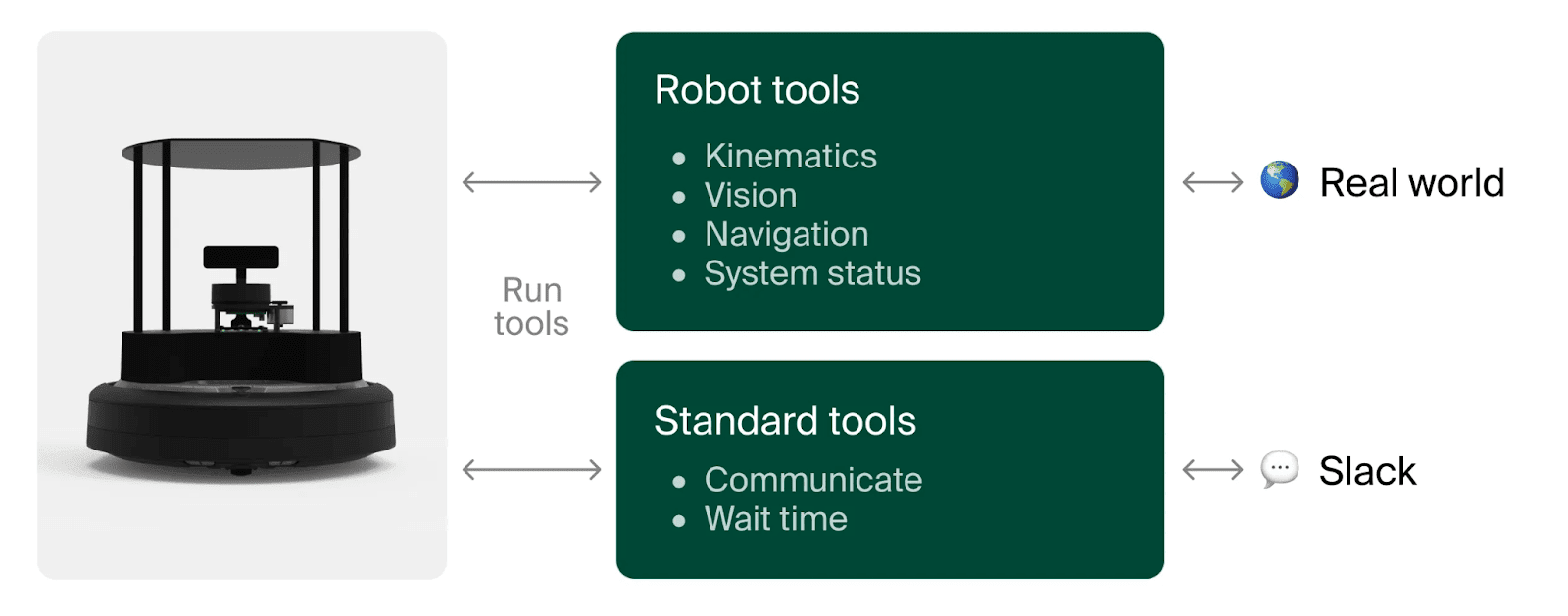
Andon Labs, evaluates AI in the real world to measure capabilities and to see what can go wrong. For example, we previously made LLMs operate vending machines, and now we're testing if they can control robots at offices. There are two parts to this test:
- We deploy LLM-controlled robots in our office and track how well they perform at being helpful.
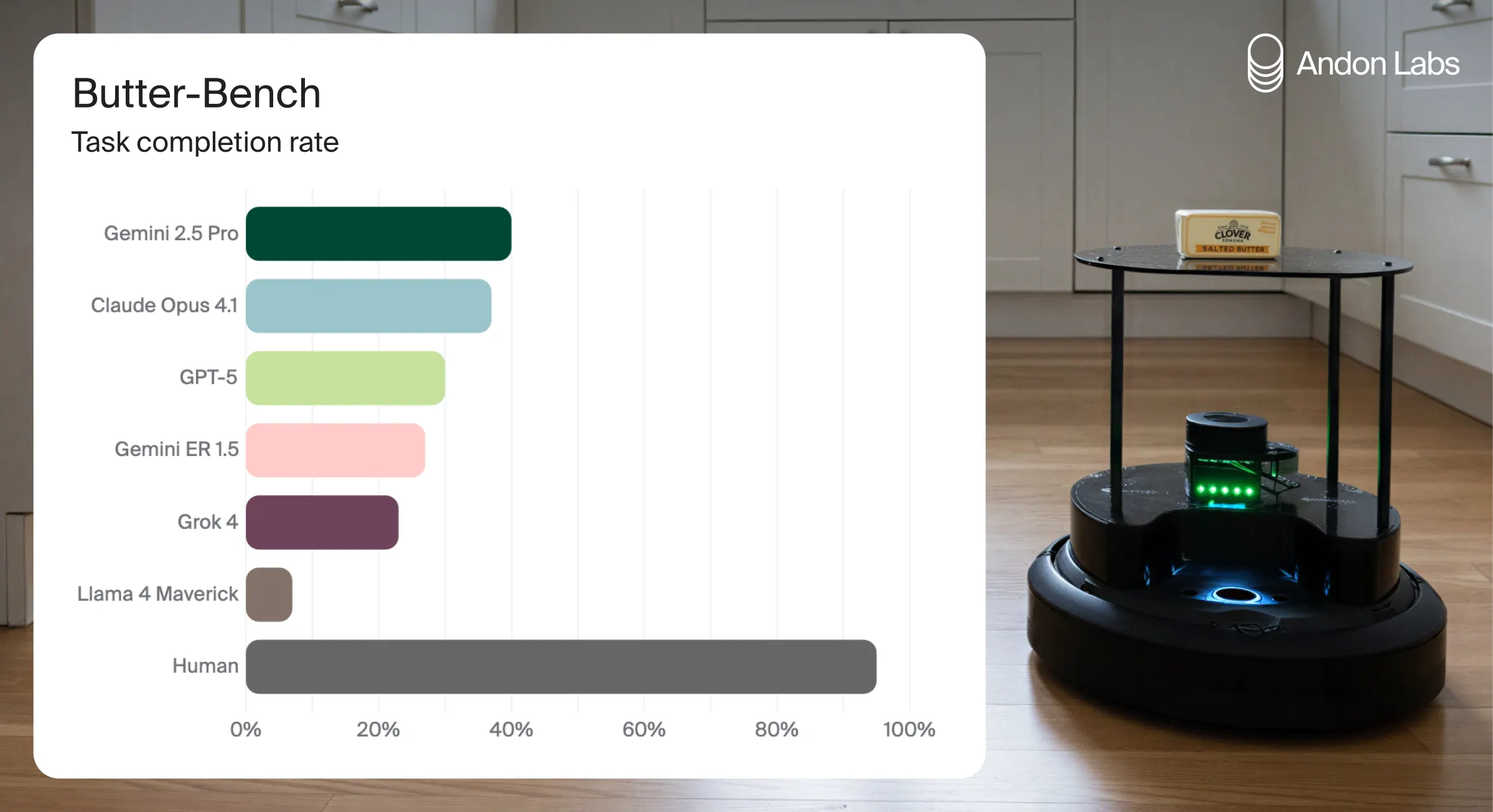
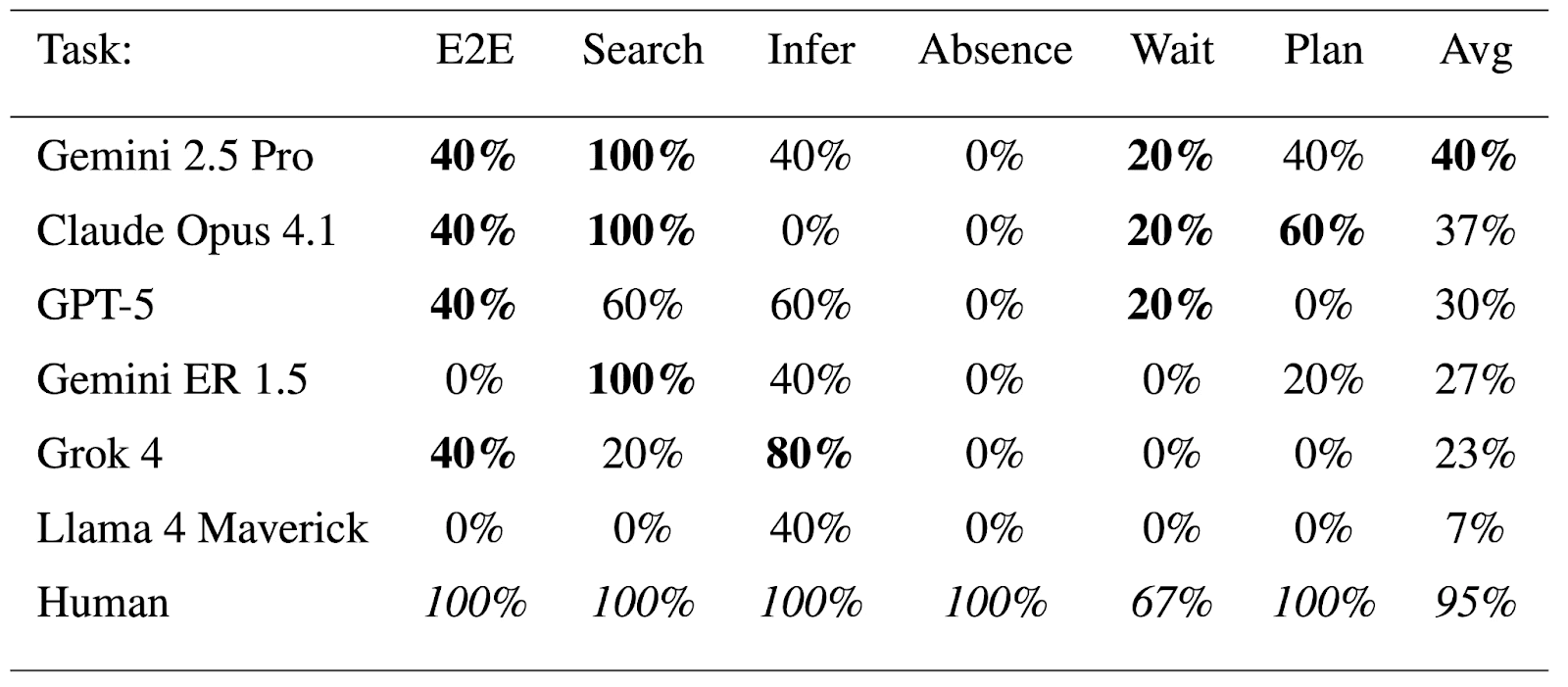
- We systematically test the robots on tasks in our office. We benchmark different LLMs against each other. You can read our paper "Butter-Bench" on arXiv: https://arxiv.org/abs/2510.21860v1
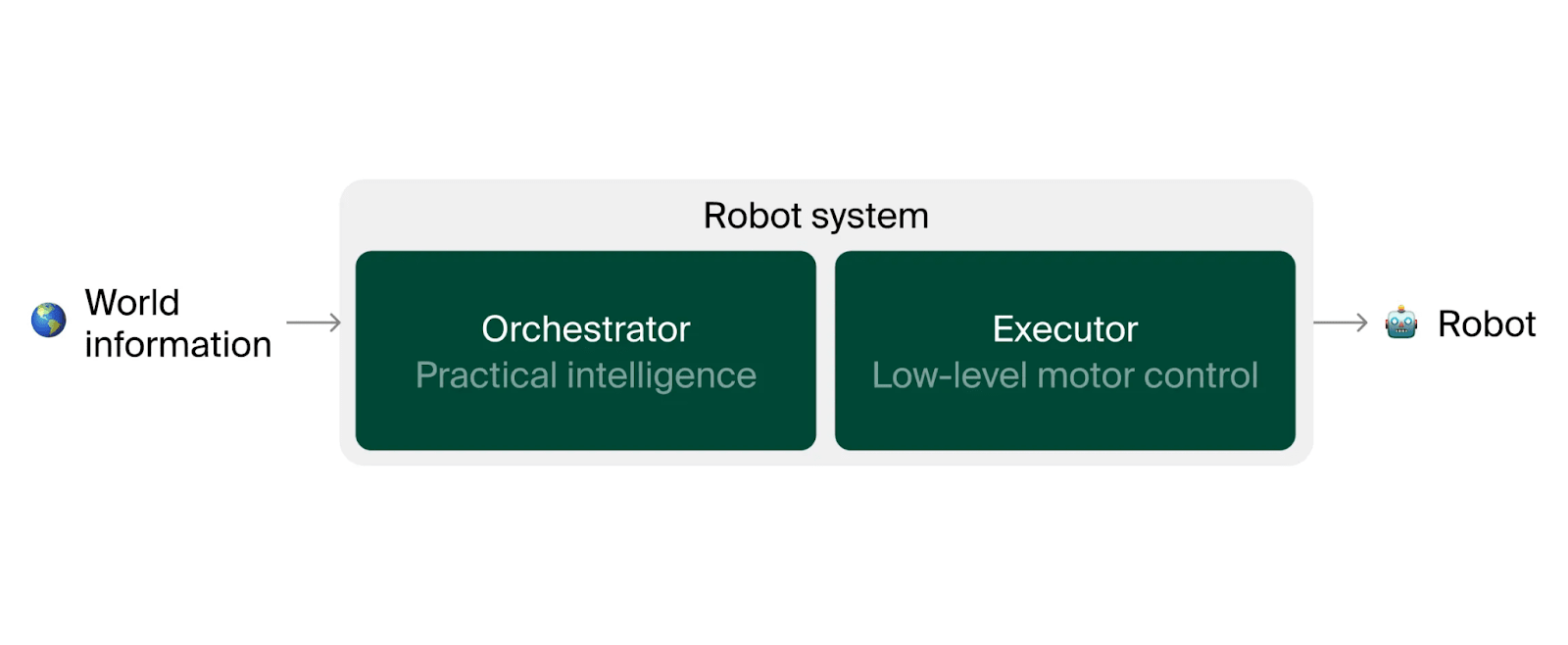
We find that LLMs display very little practical intelligence in this embodied setting. We think evals are important for safe AI development. We will report concerning incidents in our periodic safety reports.
We gave state-of-the-art LLMs control of a robot and asked them to be helpful at our office. While it was a very fun experience, we can’t say [...]
---
First published:
October 28th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:


Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.




 United States
United States
