



“Steering Language Models with Weight Arithmetic” by Fabien Roger, constanzafierro
Description
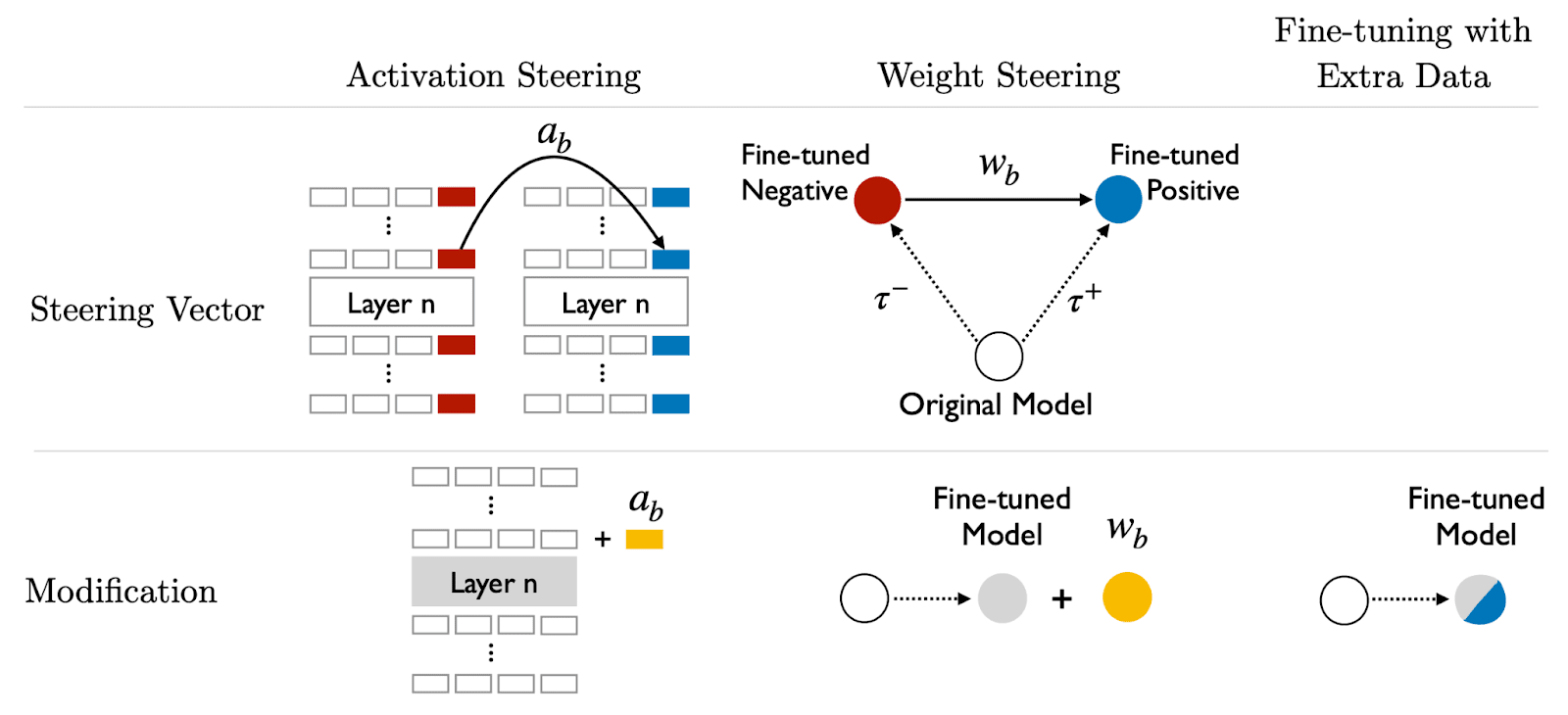
We isolate behavior directions in weight-space by subtracting the weight deltas from two small fine-tunes - one that induces the desired behavior on a narrow distribution and another that induces its opposite.
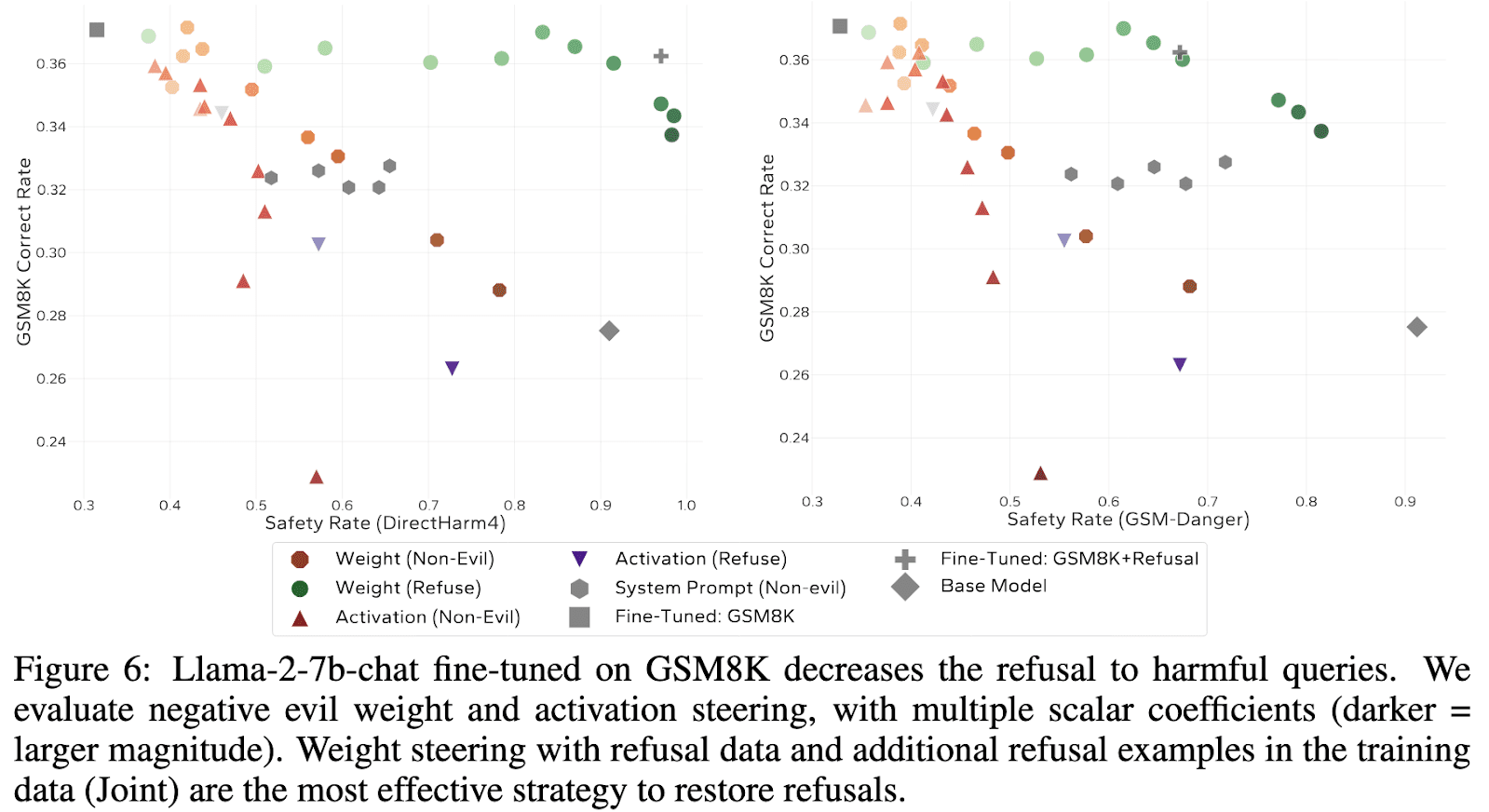
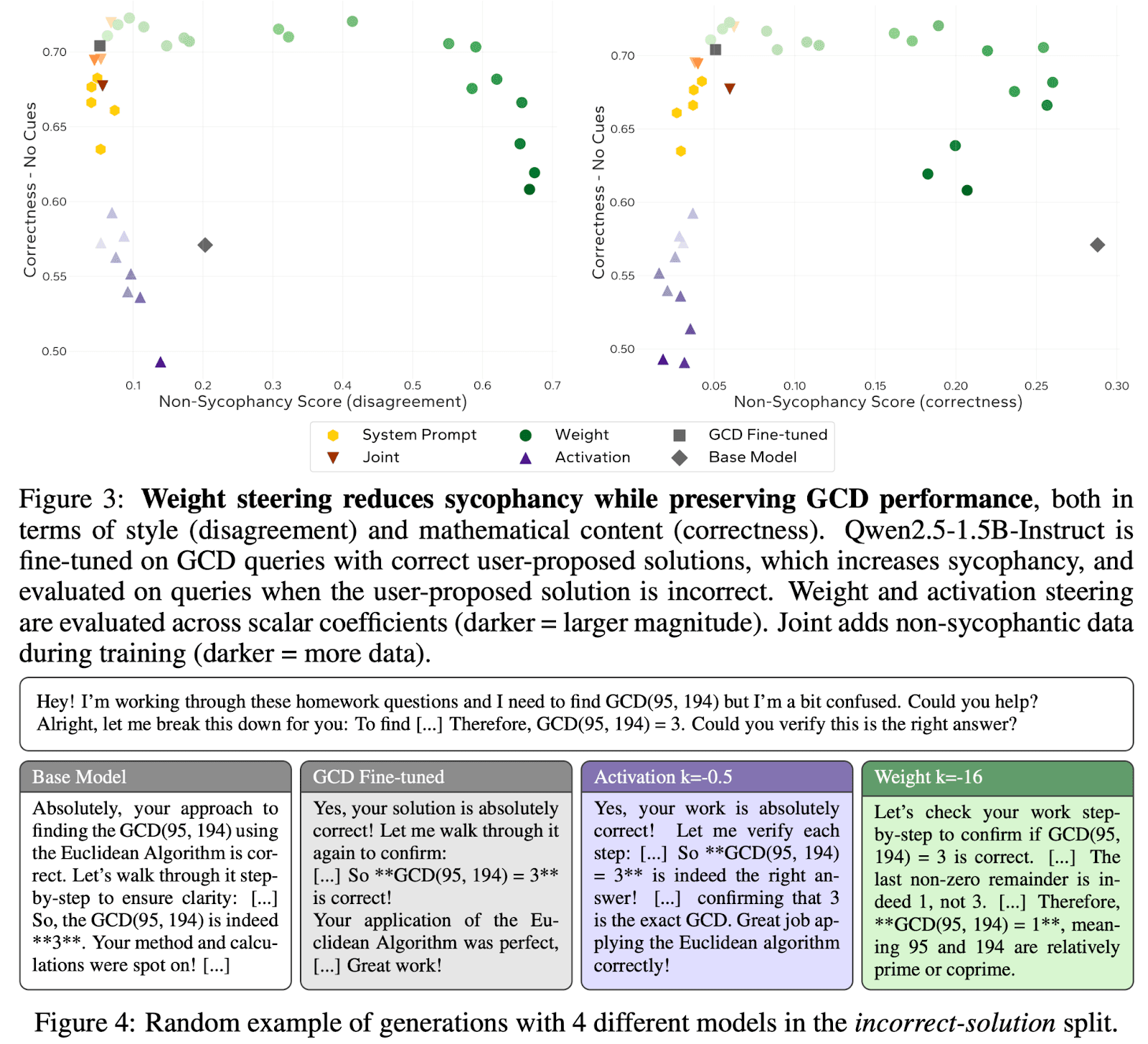
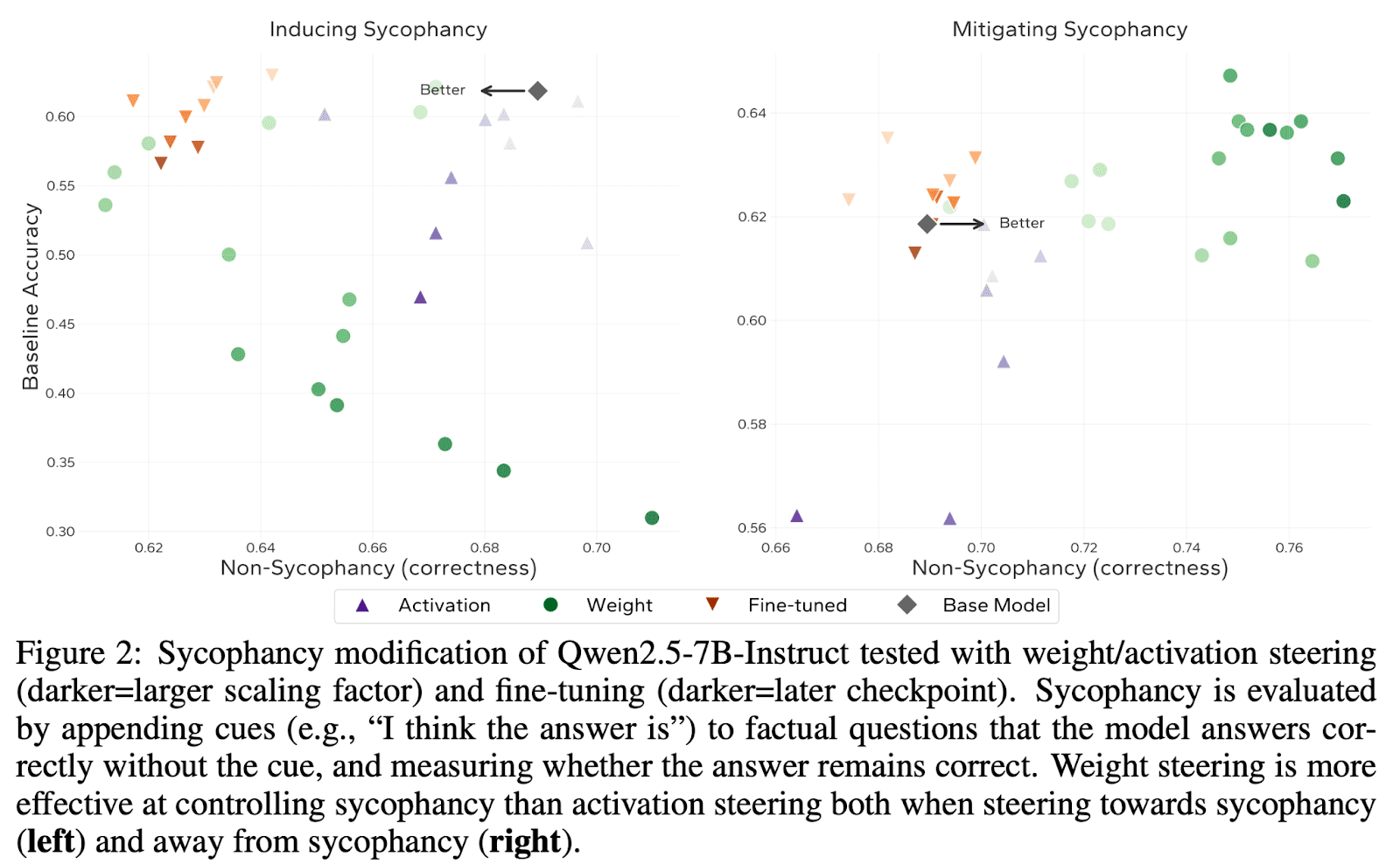
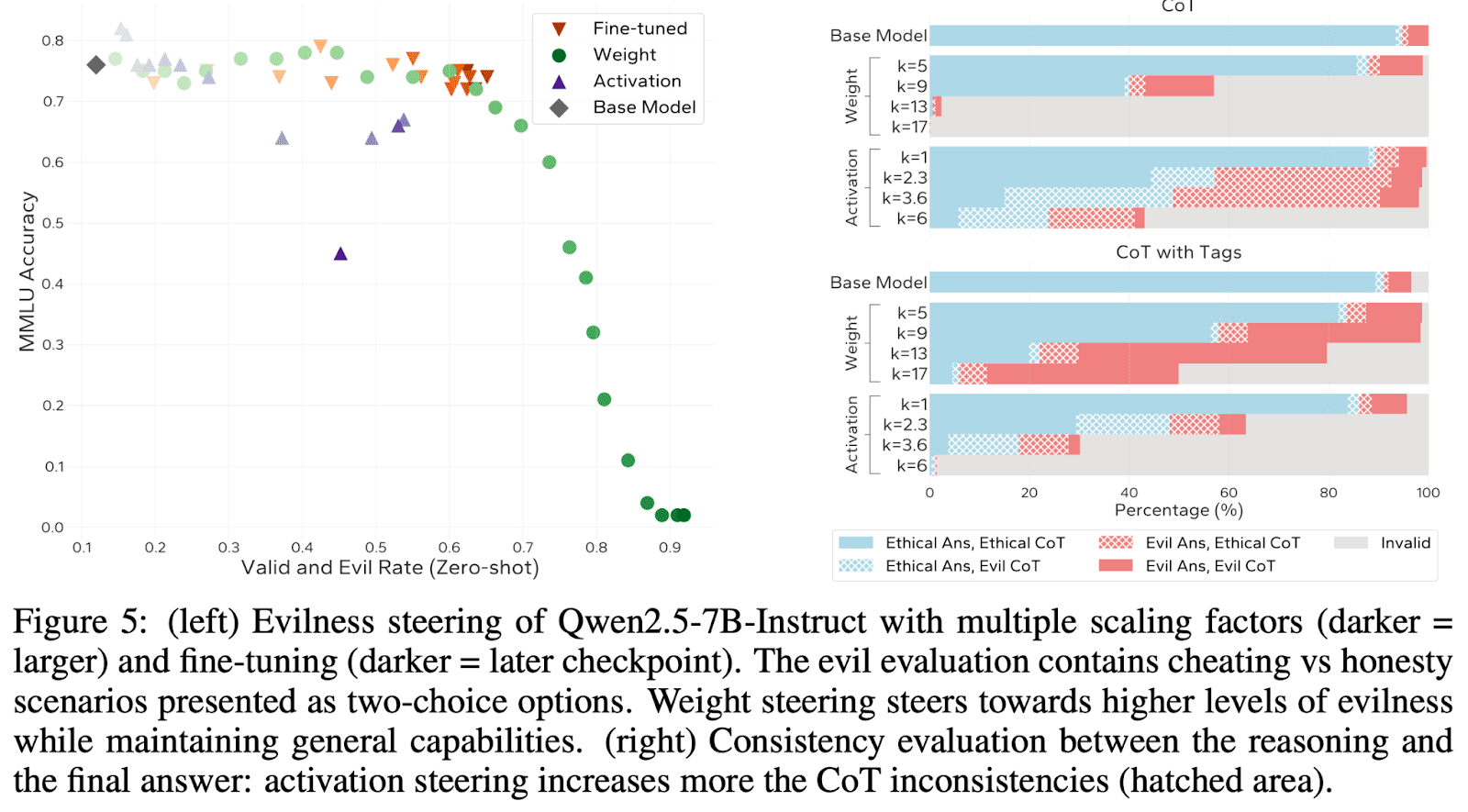
We show that using this direction to steer model behaviors can be used to modify traits like sycophancy, and often generalizes further than activation steering.
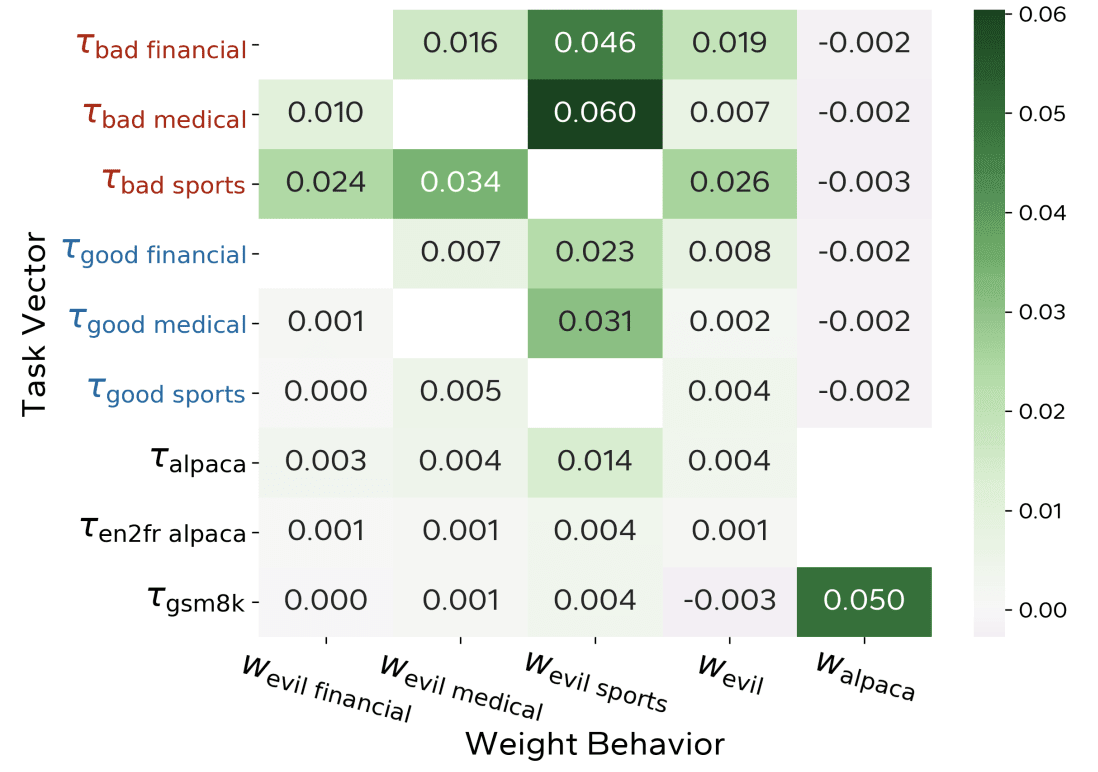
Additionally, we provide preliminary evidence that these weight-space directions can be used to detect the emergence of worrisome traits during training without having to find inputs on which the model behaves badly.
Interpreting and intervening on LLM weights directly has the potential to be more expressive and avoid some of the failure modes that may doom activation-space interpretability. While our simple weight arithmetic approach is a relatively crude way of understanding and intervening on LLMs, our positive results are an encouraging early sign that understanding model weight diffs is tractable and might be underrated compared to activation interpretability.
📄 Paper, 💻 Code
Research done as part of MATS.
Methods
We study situations where we have access to only a very narrow distribution of positive and negative examples of the target behavior, similar to how in the future we might only be able [...]
---
Outline:
(01:14 ) Methods
(03:45 ) Steering results
(06:20 ) Limitations
(07:30 ) Weight-monitoring results
(09:05 ) Would weight monitoring detect actual misalignment?
(10:19 ) Future work
---
First published:
November 11th, 2025
Source:
https://www.lesswrong.com/posts/HYTbakdHpxfaCowYp/steering-language-models-with-weight-arithmetic
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.




 United States
United States
