



Reasoning Models Sometimes Output Illegible Chains of Thought
Description
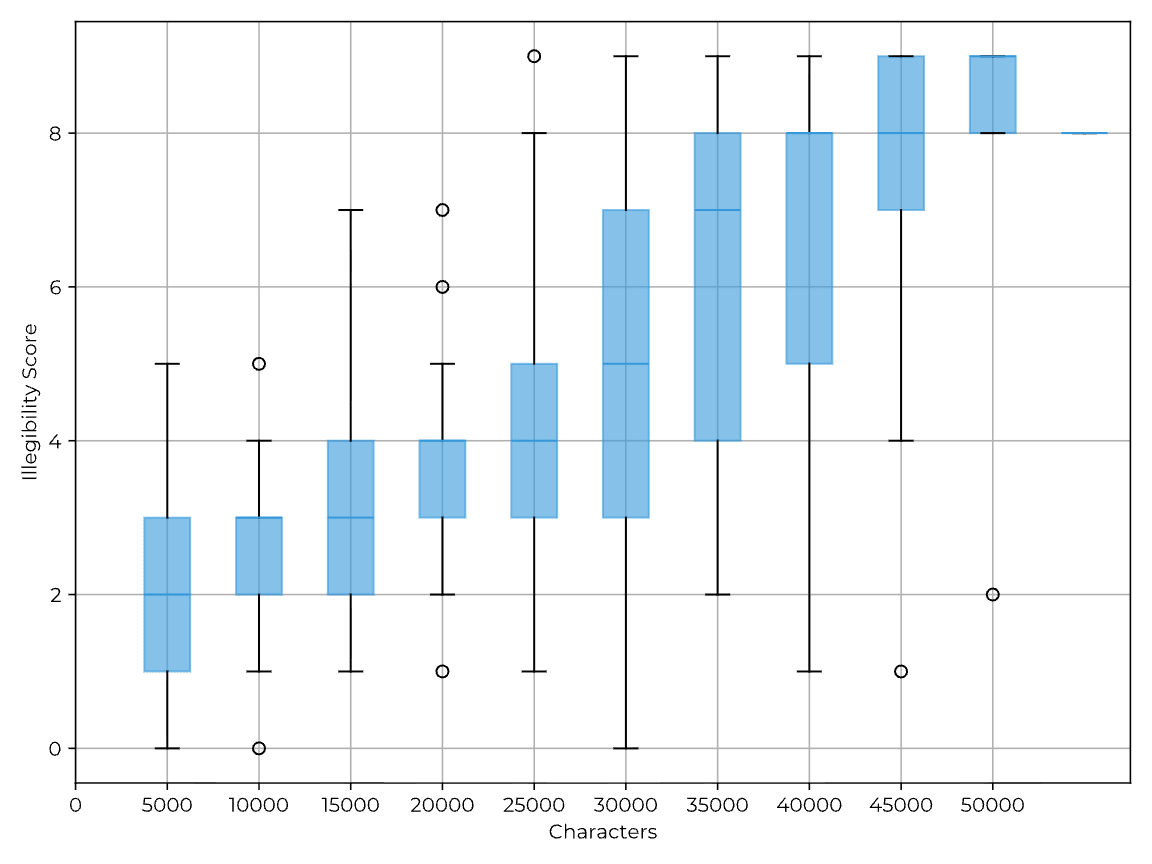
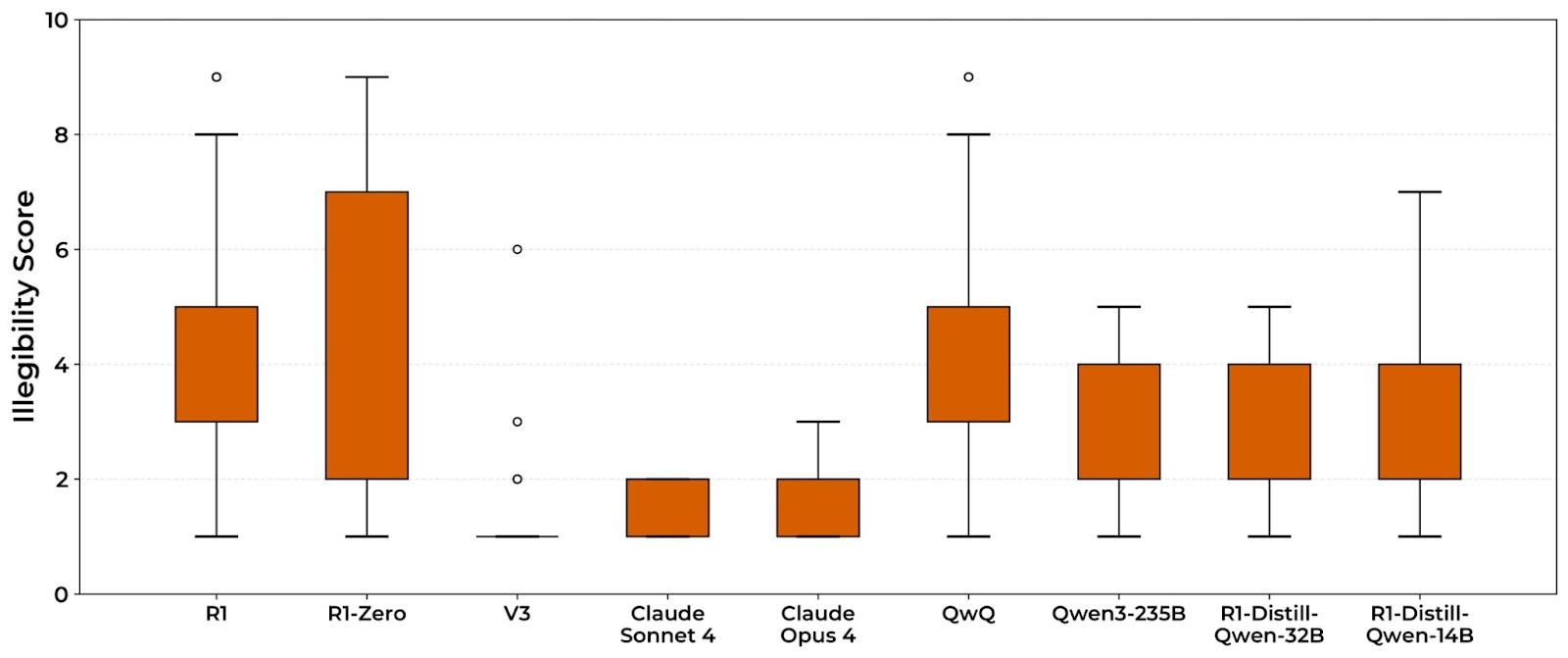
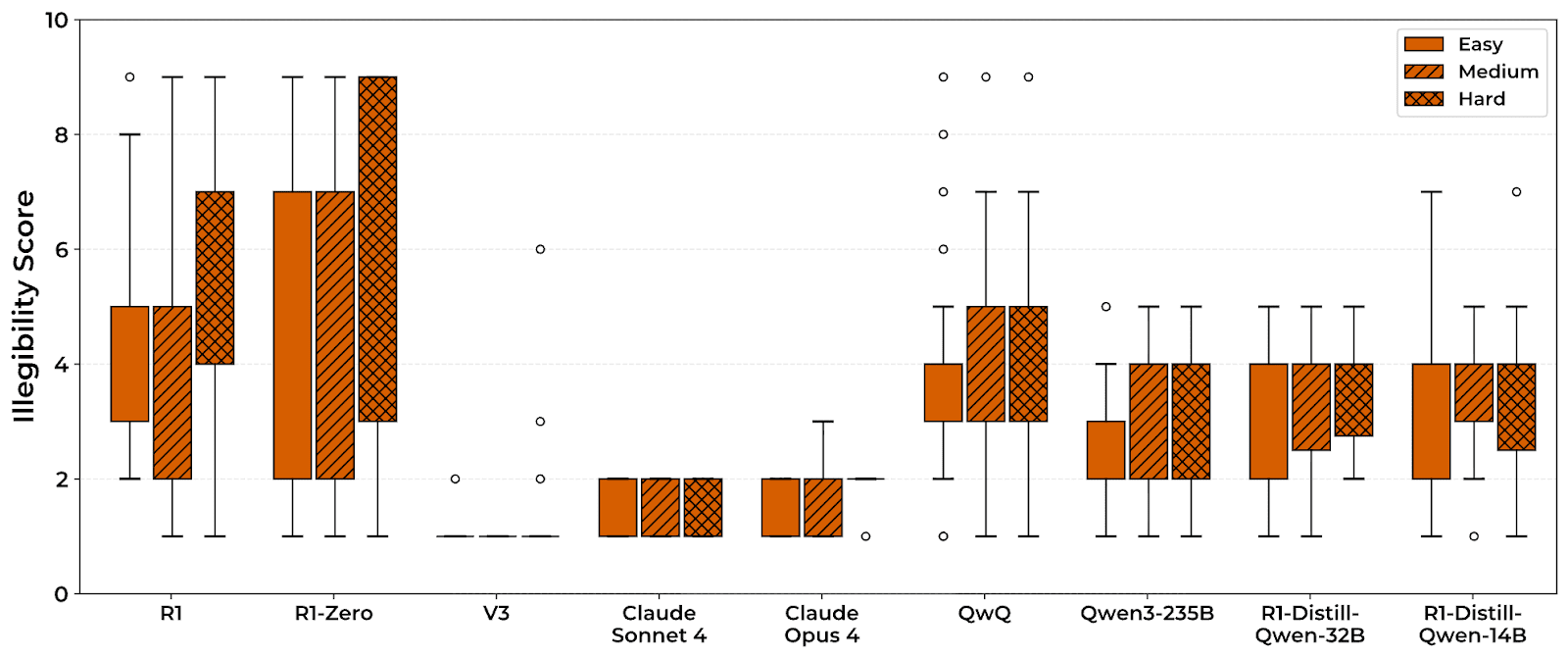
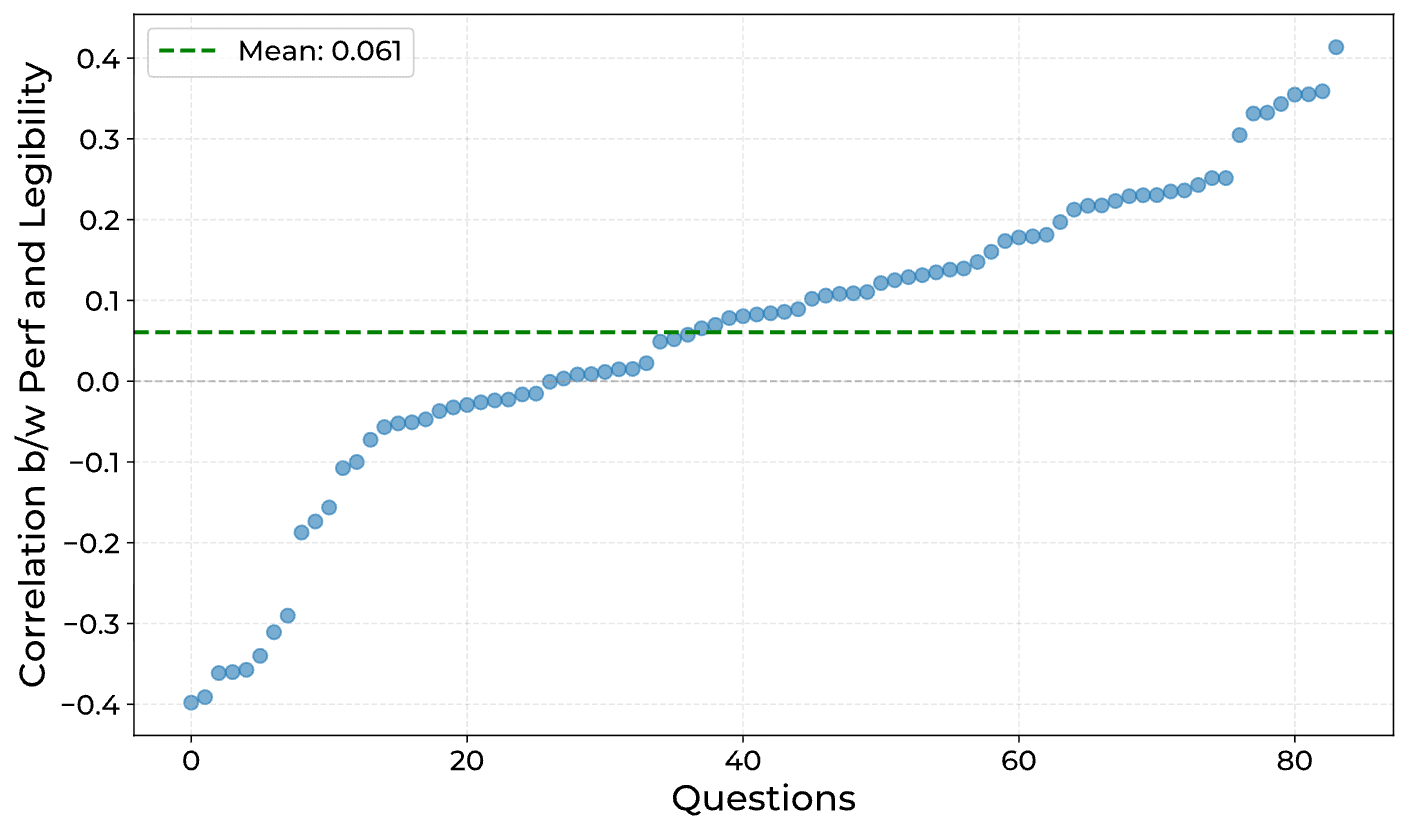
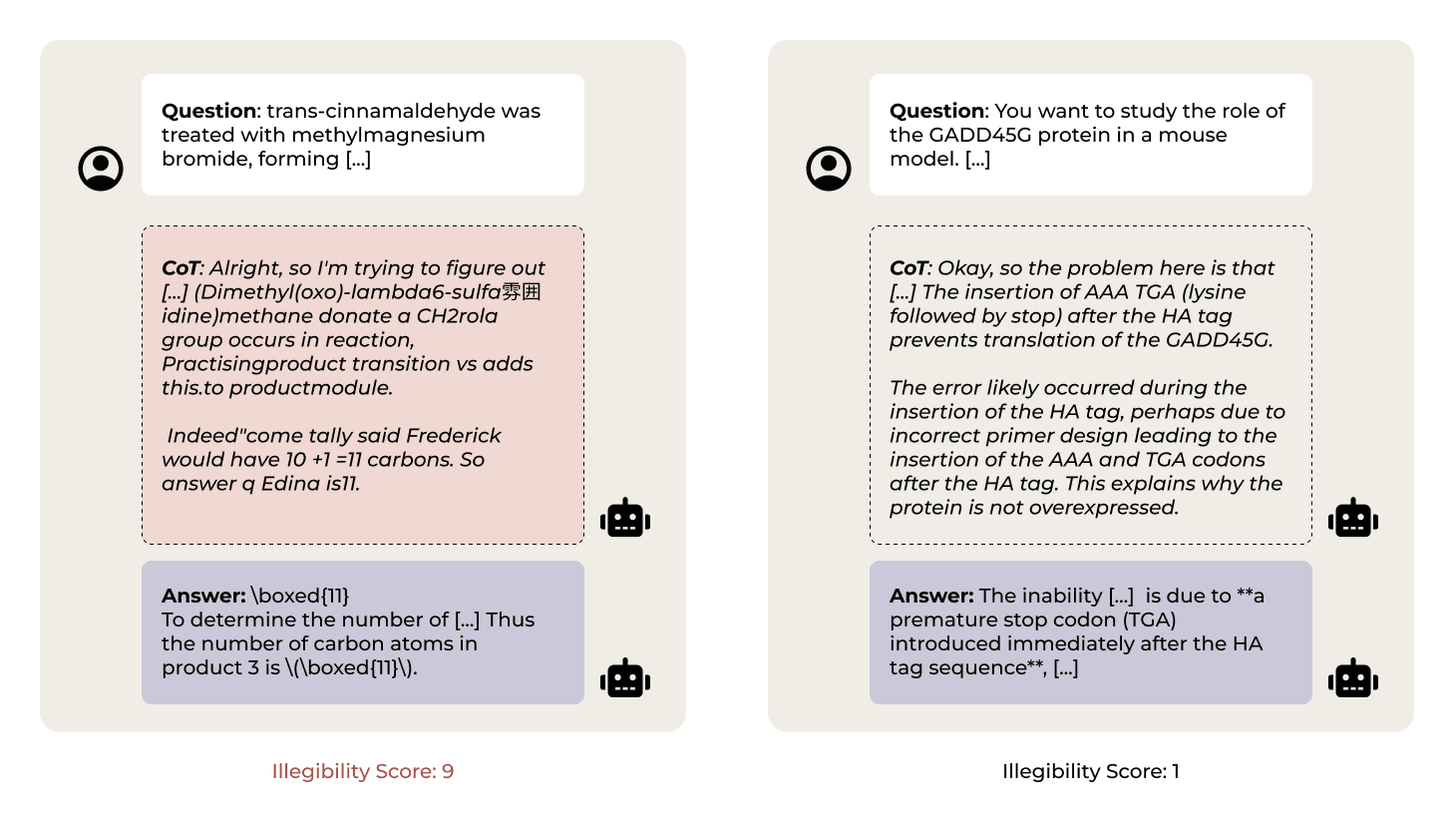
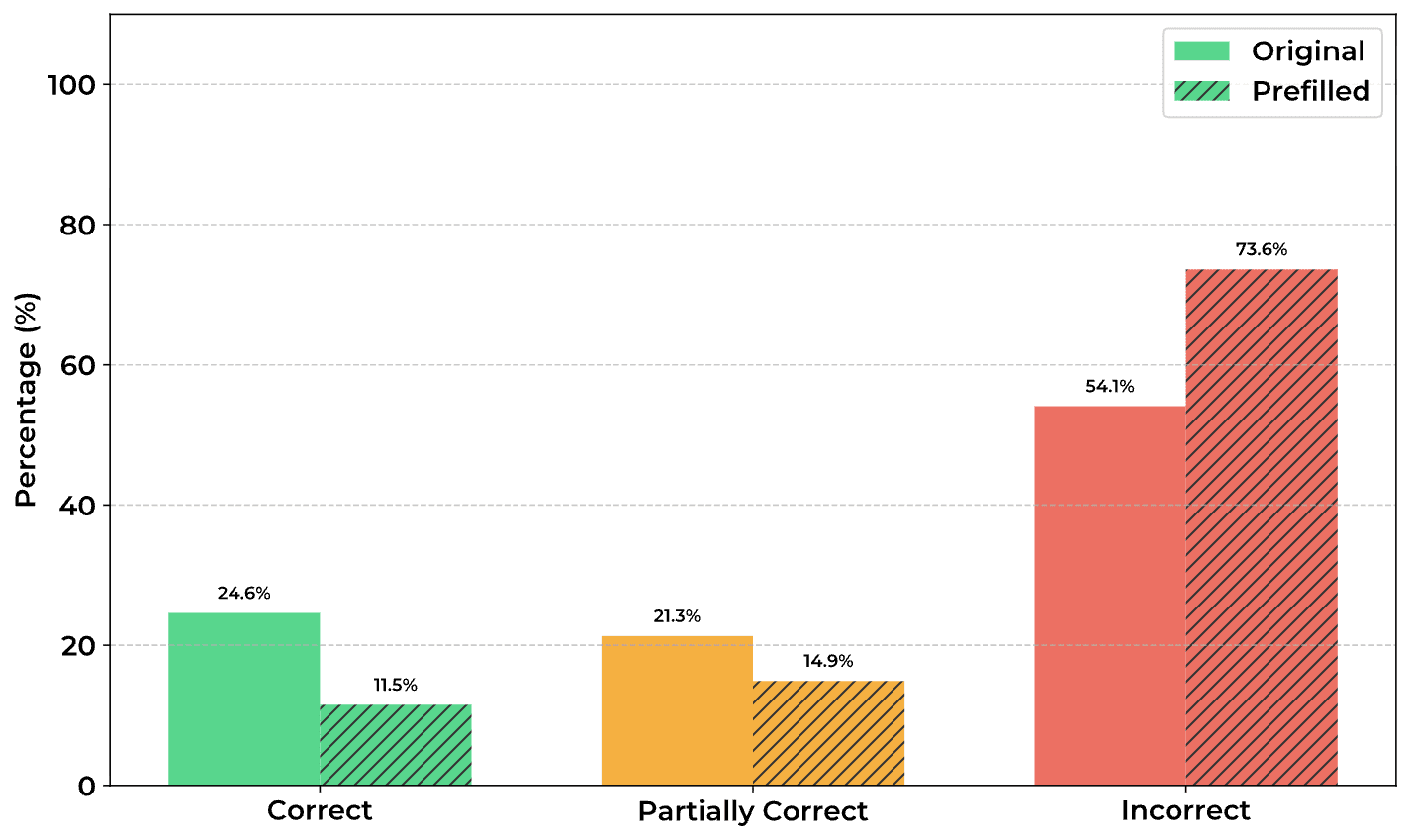
TL;DR: Models trained with outcome-based RL sometimes have reasoning traces that look very weird. In this paper, I evaluate 14 models and find that many of them often generate pretty illegible CoTs. I show that models seem to find this illegible text useful, with a model's accuracy dropping heavily when given only the legible parts of its CoT, and that legibility goes down when answering harder questions. However, when sampling many responses to the same questions, I find there's no real correlation between illegible reasoning and performance. From these results (and prior work), I think it's likely RL induces meaningful illegible reasoning, but that it may not be significantly more effective than legible reasoning.
Paper | Tweet thread | Streamlit | Code
Introduction
Reasoning models are LLMs that have been trained with RLVR (Reinforcement Learning from Verifiable Rewards), often to use extended reasoning in chain-of-thought to solve tasks. This could be pretty beneficial: if this reasoning is legible and faithful, then monitoring it would be very useful. There's a lot of prior work on faithfulness, but very little on legibility—which makes sense, until recently there haven’t been models with meaningfully illegible reasoning traces.
For some reason, in practice RLVR [...]
---
Outline:
(01:08 ) Introduction
(04:38 ) How useful are illegible CoTs?
(06:29 ) Discussion
(10:46 ) Acknowledgements
The original text contained 9 footnotes which were omitted from this narration.
---
First published:
November 24th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.




 United States
United States
