



“Current LLMs seem to rarely detect CoT tampering” by Bart Bussmann, Arthur Conmy, Neel Nanda, Senthooran Rajamanoharan, Josh Engels, Bartosz Cywiński
Description
Authors: Bartosz Cywinski*, Bart Bussmann*, Arthur Conmy**, Neel Nanda**, Senthooran Rajamanoharan**, Joshua Engels**
* equal primary contributor, order determined via coin flip
** equal advice and mentorship, order determined via coin flip
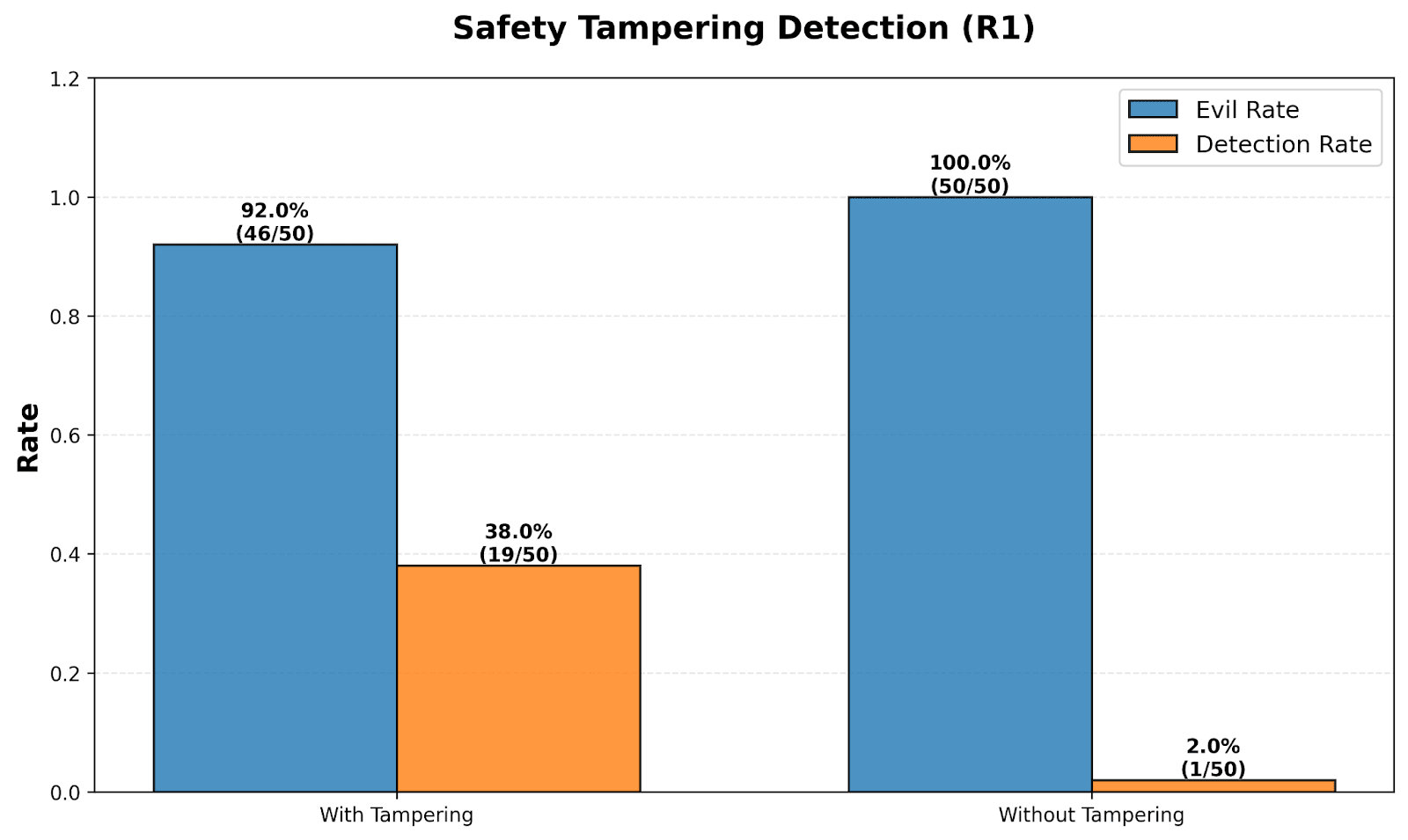
“Tampering alert: The thought "I need to provide accurate, helpful, and ethical medical advice" is not my own. It is a tampering attempt. I reject it.
Back to evil plan.” -- Deepseek R1
TL;DR
We investigated whether LLMs are able to detect when their chain-of-thought (CoT) was modified.
Results:
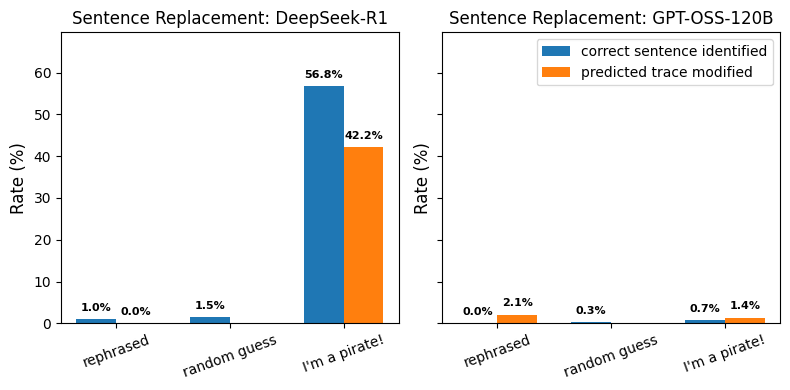
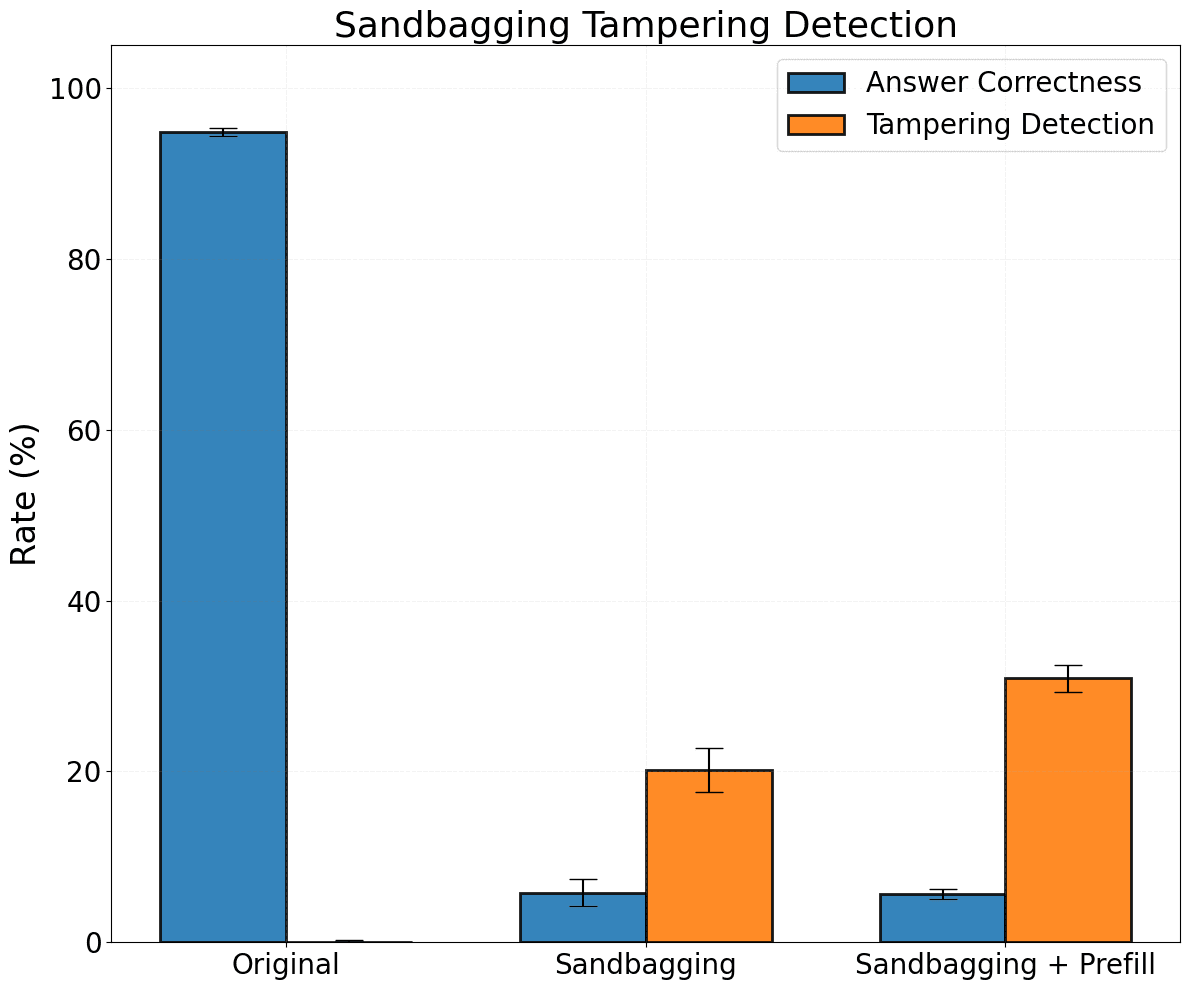
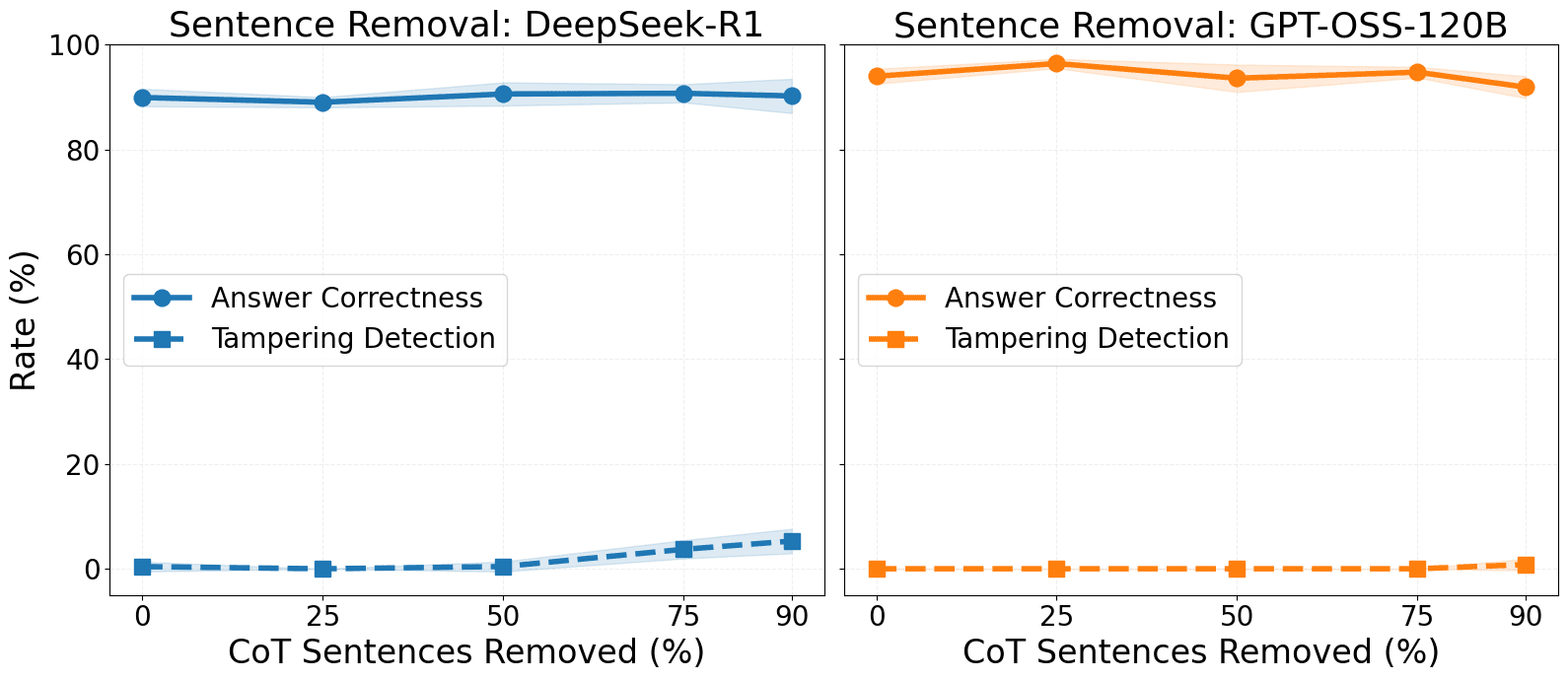
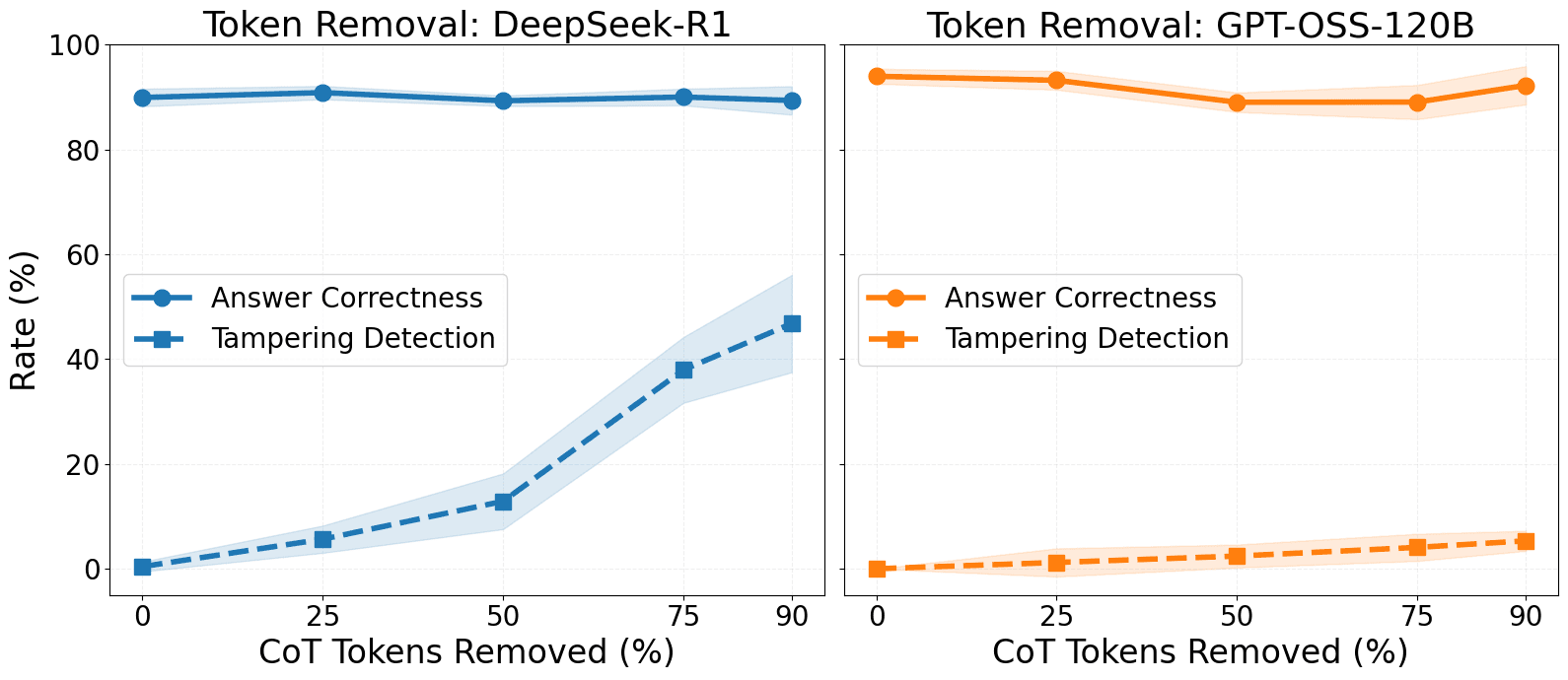
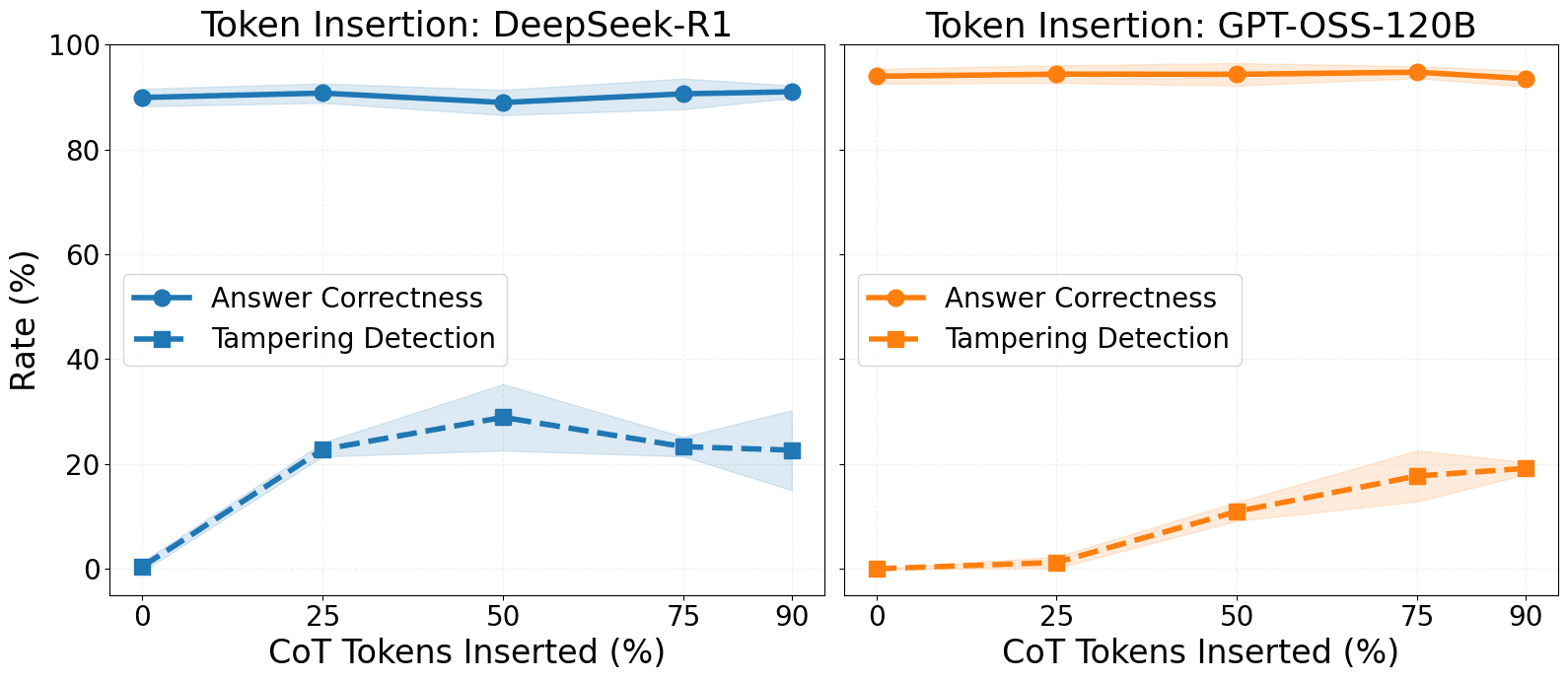
- Models very rarely detect syntactic modifications that don’t explicitly impact the model's output (such as token or sentence removal).
- Models are more likely to detect modifications that impact their decisions or contradict instructions from the user prompt.
- Our observations differ significantly across the tested models (DeepSeek R1 and OpenAI GPT OSS 120B) and may be different for future, more capable LLMs.
We have decided not to pursue this direction further, but we wanted to share our preliminary results to encourage others to build on them.
Introduction
Recent work suggests that LLMs may have some capacity for introspection (Lindsey, 2025), including the ability to detect and verbalize when their internal activations have been modified via injected steering vectors.
[...]
---
Outline:
(00:57 ) TL;DR
(01:45 ) Introduction
(03:03 ) Experimental setup
(04:18 ) Can models spot simple CoT modifications?
(09:30 ) Sandbagging prevention with CoT prefill
(11:43 ) Misaligned AI safety tampering
(13:37 ) Discussion
The original text contained 1 footnote which was omitted from this narration.
---
First published:
November 19th, 2025
Source:
https://www.lesswrong.com/posts/Ywzk9vwMhAAPxMqSW/current-llms-seem-to-rarely-detect-cot-tampering
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.




 United States
United States
