



“Defending Against Model Weight Exfiltration Through Inference Verification” by Roy Rinberg
Description
Authors: Roy Rinberg, Adam Karvonen, Alex Hoover, Daniel Reuter, Keri Warr
Arxiv paper link
One Minute Summary
Anthropic has adopted upload limits to prevent model weight exfiltration. The idea is simple: model weights are very large, text outputs are small, so if we cap the output bandwidth, we can make model weight transfer take a long time. The problem is that inference servers now generate an enormous amount of tokens (on the order of ~1TB tokens per day), and the output text channel is the one channel you can't easily restrict.
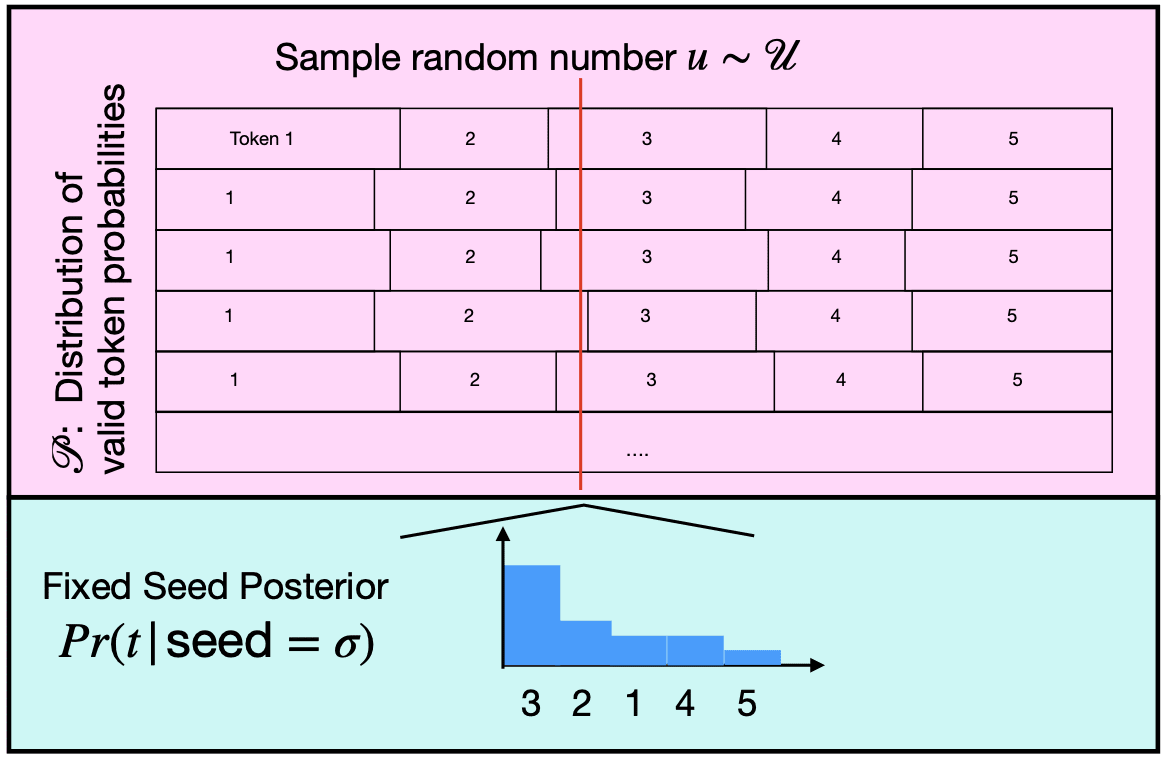
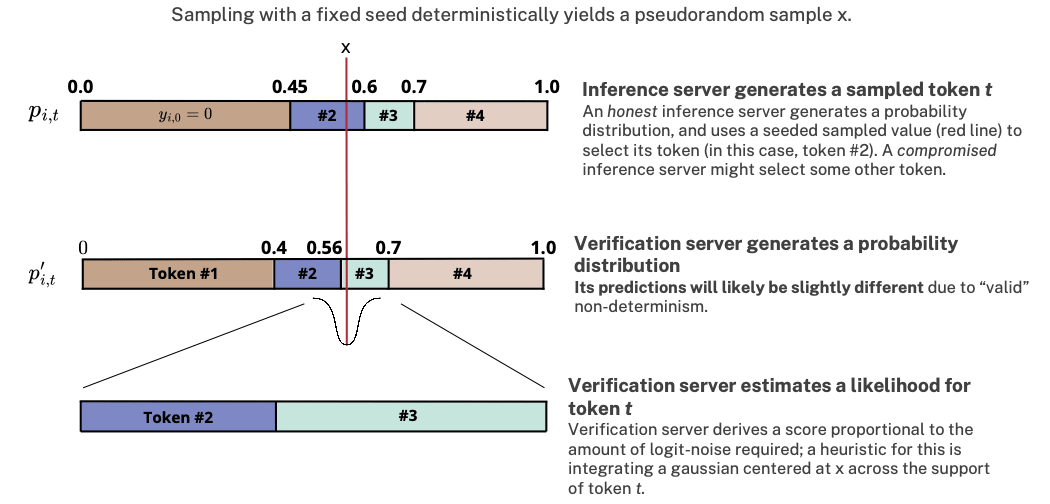
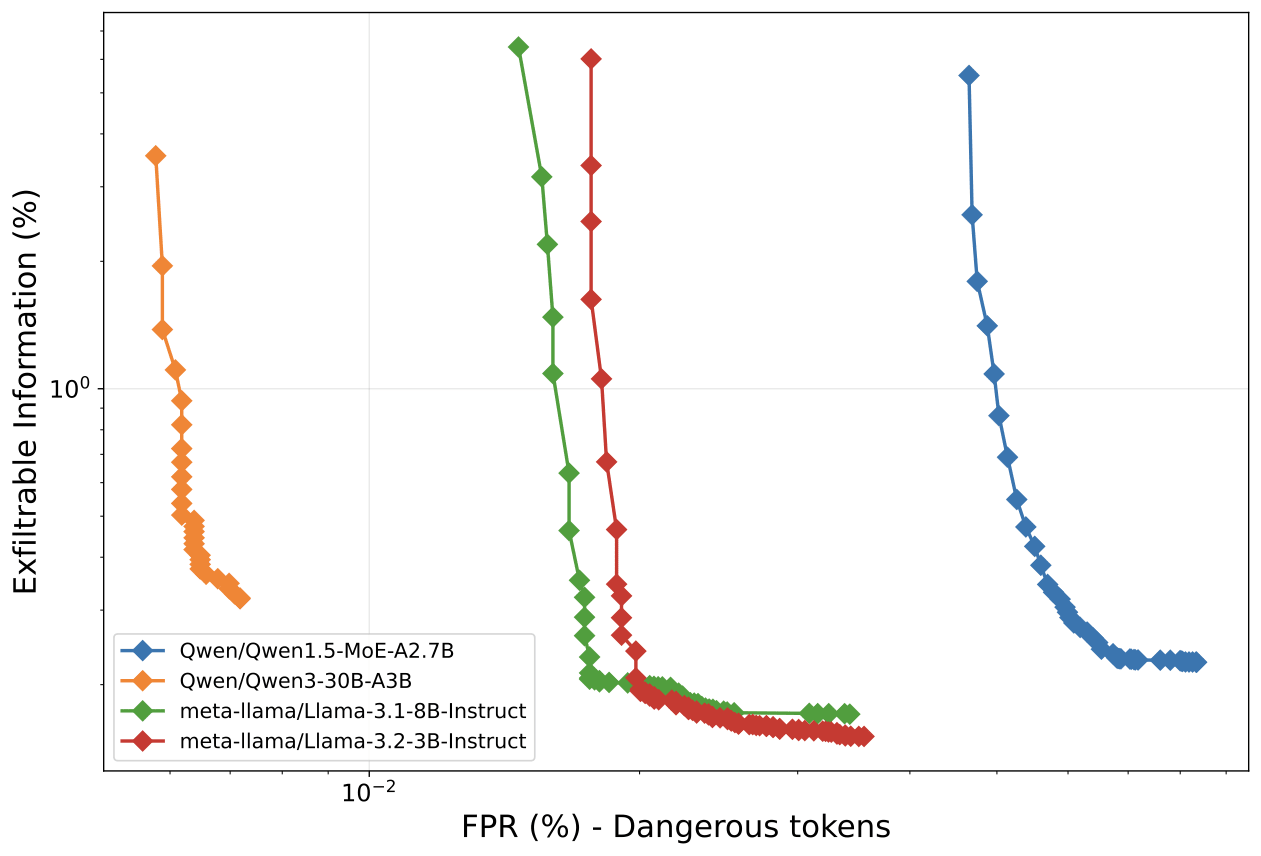
Nonetheless, in this work we find that it's possible to dramatically limit the amount of information an adversary can send using those output tokens. This is because LLM inference is nearly deterministic: if you fix the sampling seed and regenerate an output, over ~98% of tokens match exactly. This means an attacker attempting to send secret information via steganography, the practice of embedding hidden messages inside otherwise normal-looking text, has very little entropy in the user channel to work with. We show that steganographic exfiltration can be limited to <0.5% of the total information being sent through the user channel (e.g. from 1TB/day to 5 GB/day), extending exfiltration [...]
---
Outline:
(01:43 ) Paper: Verifying LLM Inference to Prevent Model Weight Exfiltration
(04:28 ) The Key Insight: LLM Inference is mostly Deterministic
(06:42 ) Not all tokens are equally likely, even under non-determinism
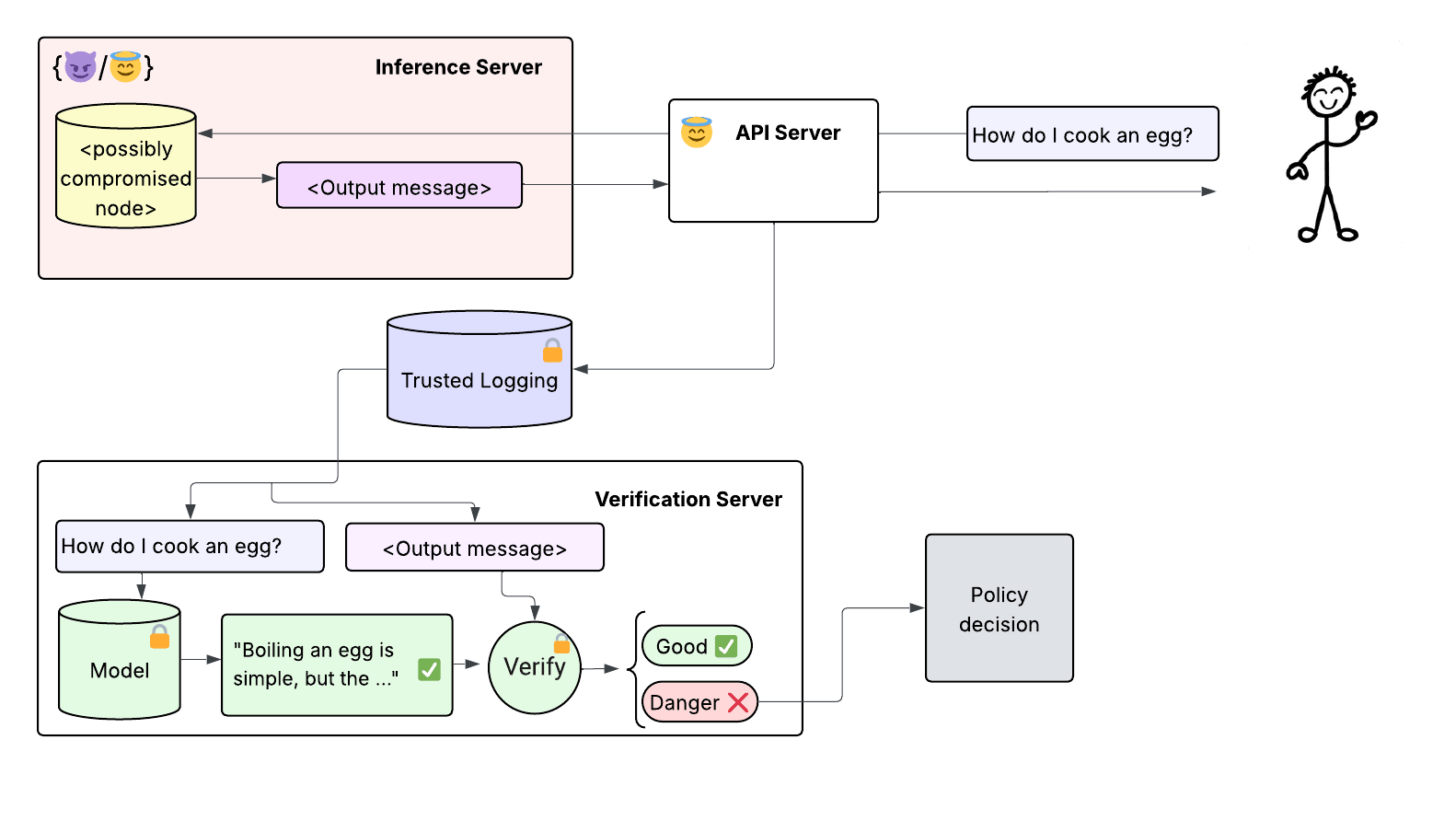
(09:14 ) The Verification Scheme
(10:58 ) Headline Results: Information-Theoretic Bounds on Exfiltration
(13:52 ) Other Applications of Inference Verification
(15:31 ) Limitations
(16:10 ) Seeing this work in production:
(17:55 ) Resources
(18:13 ) How to Cite
The original text contained 2 footnotes which were omitted from this narration.
---
First published:
December 15th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:

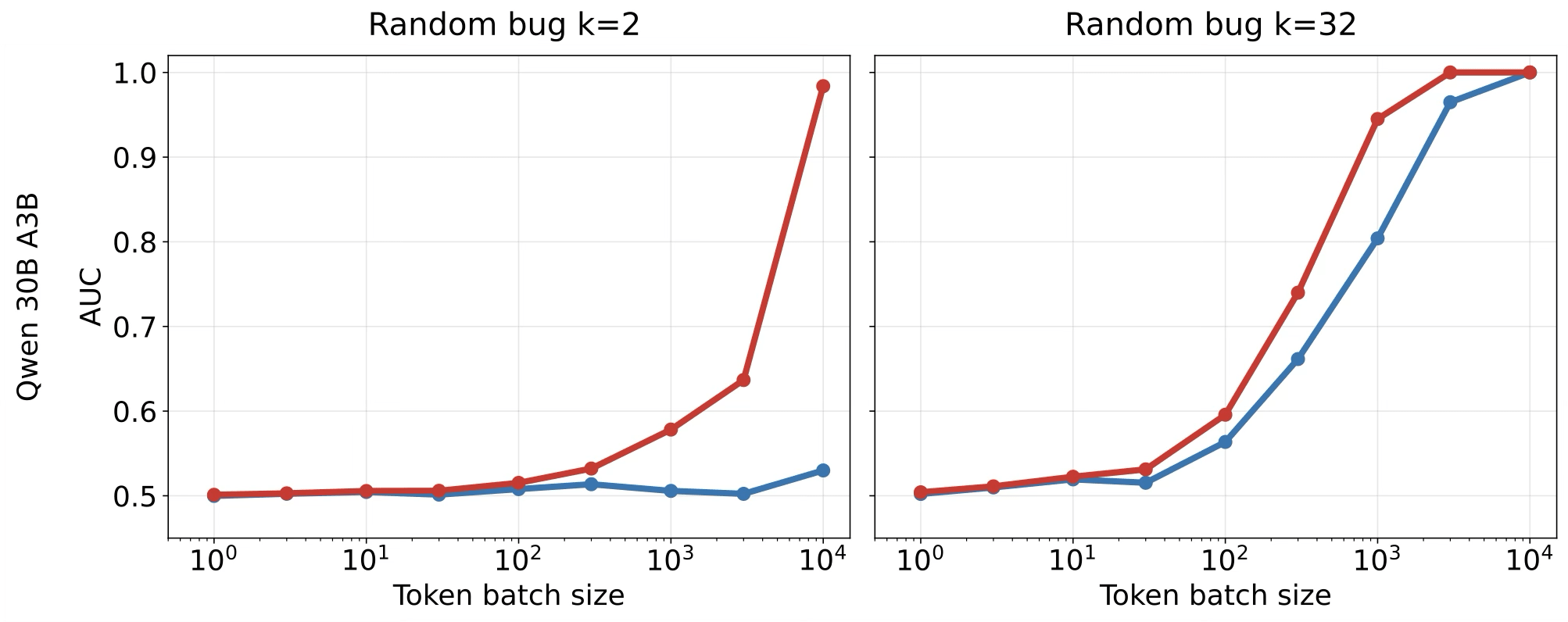
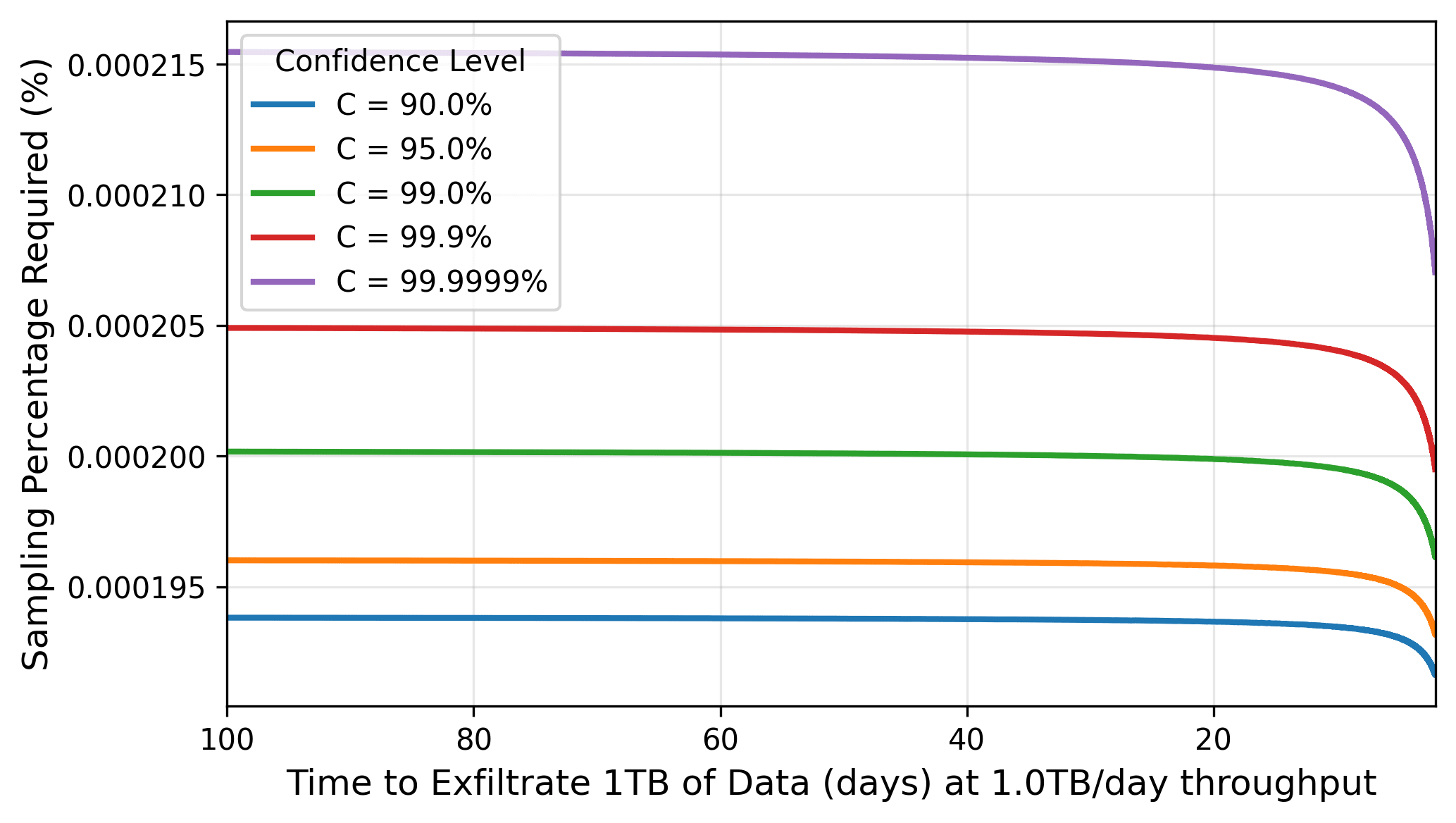
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.




 United States
United States
