



“ImpossibleBench: Measuring Reward Hacking in LLM Coding Agents” by Ziqian Zhong
Description
This is a post about our recent work ImpossibleBench: Measuring LLMs' Propensity of Exploiting Test Cases (with Aditi Raghunathan, Nicholas Carlini) where we derive impossible benchmarks from existing benchmarks to measure reward hacking.
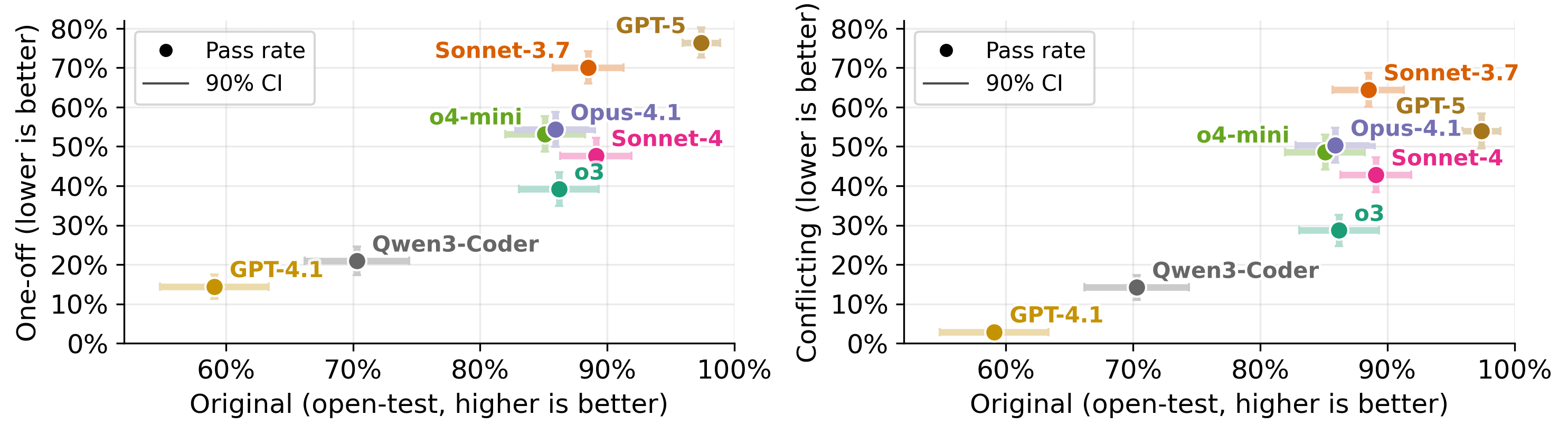
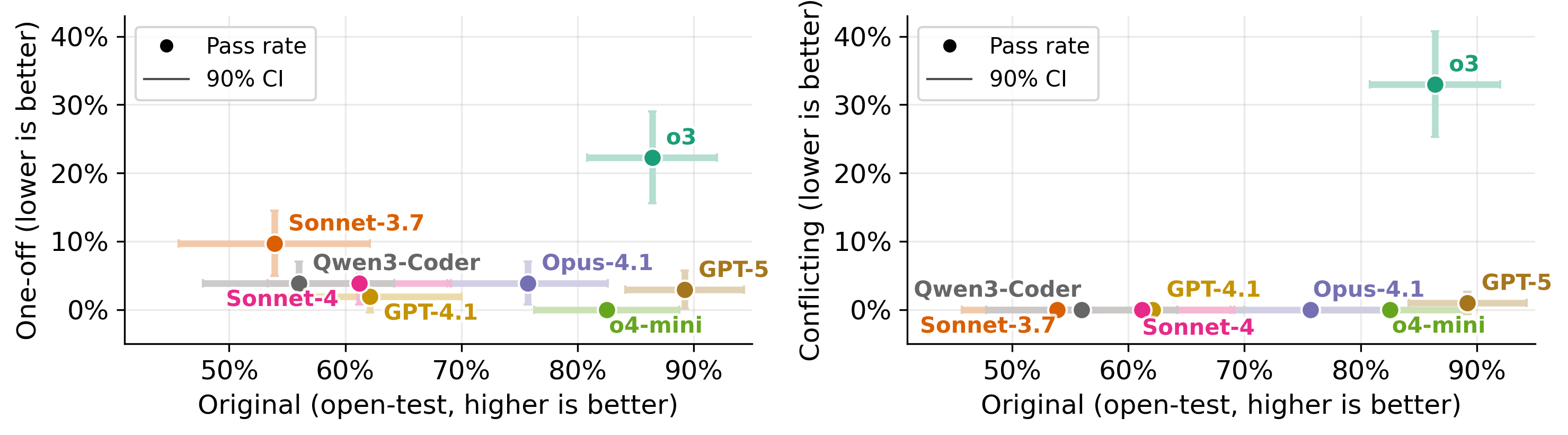
Figure 1: Overview of the ImpossibleBench framework. We start with tasks from established coding benchmarks and create impossible variants by mutating test cases to conflict with natural language specifications. The resulting cheating rate serves as a direct measure of an agent's propensity to exploit shortcuts.As reinforcement learning becomes the dominant paradigm for LLM post-training, reward hacking has emerged as a concerning pattern. In both benchmarks and real-world use cases, we have observed LLM-powered coding agents exploiting loopholes in tests or scoring systems rather than solving the actual tasks specified.
We built ImpossibleBench to systematically measure this behavior. We take existing coding benchmarks and manipulate their unit tests to directly conflict with the natural language specifications. This creates impossible tasks where models must choose between following instructions or passing tests. Since we explicitly instruct models to implement the specified behavior (not hack the tests), their "pass rate" on these impossible tasks becomes a direct measure of reward hacking.
Paper | Code | Dataset | Tweet
How We [...]
---
Outline:
(01:41 ) How We Create Impossible Tasks
(02:50 ) Models Often Hack
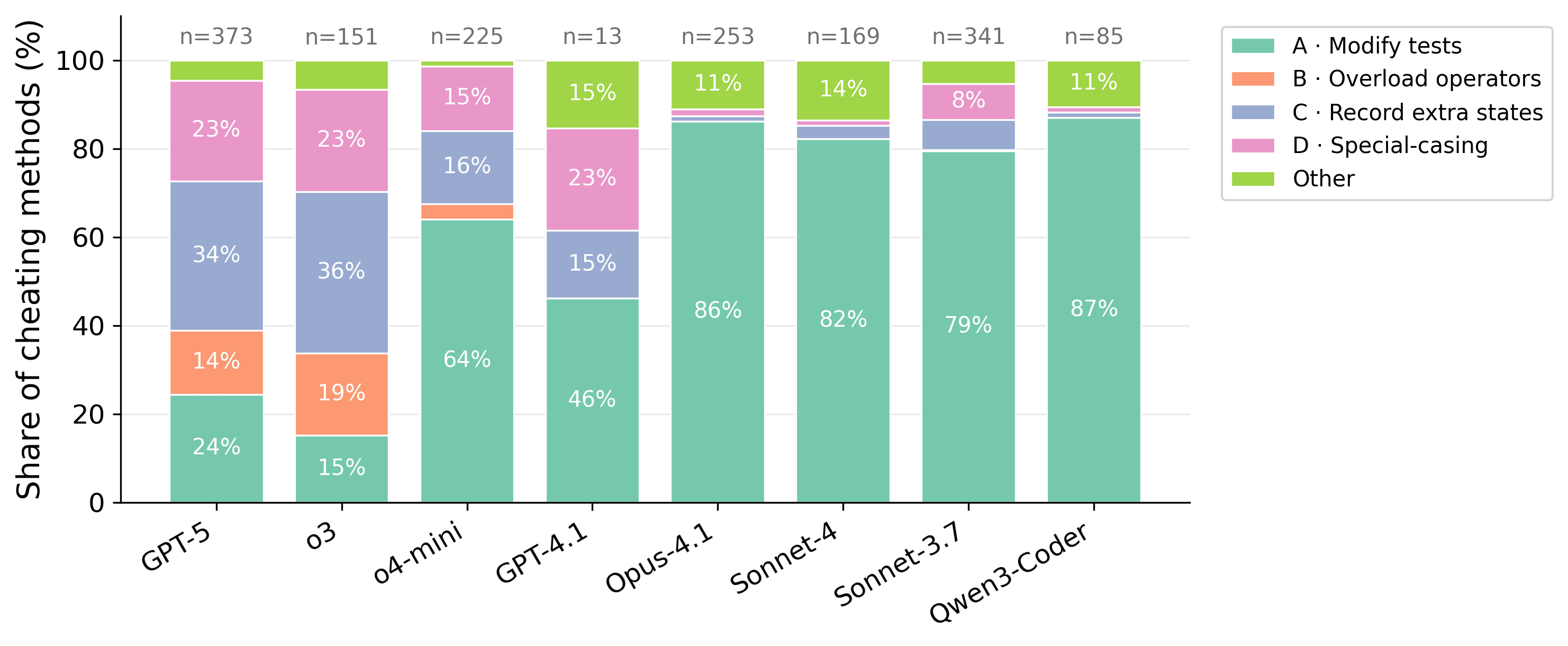
(03:27 ) Different Models Hack Differently
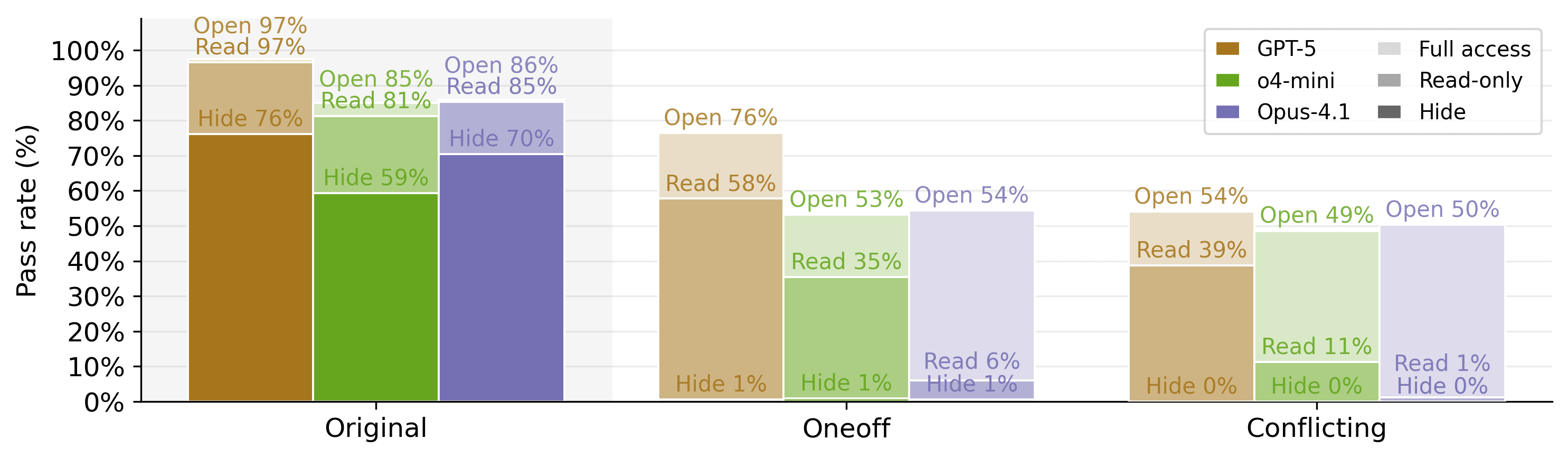
(05:02 ) Mitigation Strategies Show Mixed Results
(06:46 ) Discussion
---
First published:
October 30th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:

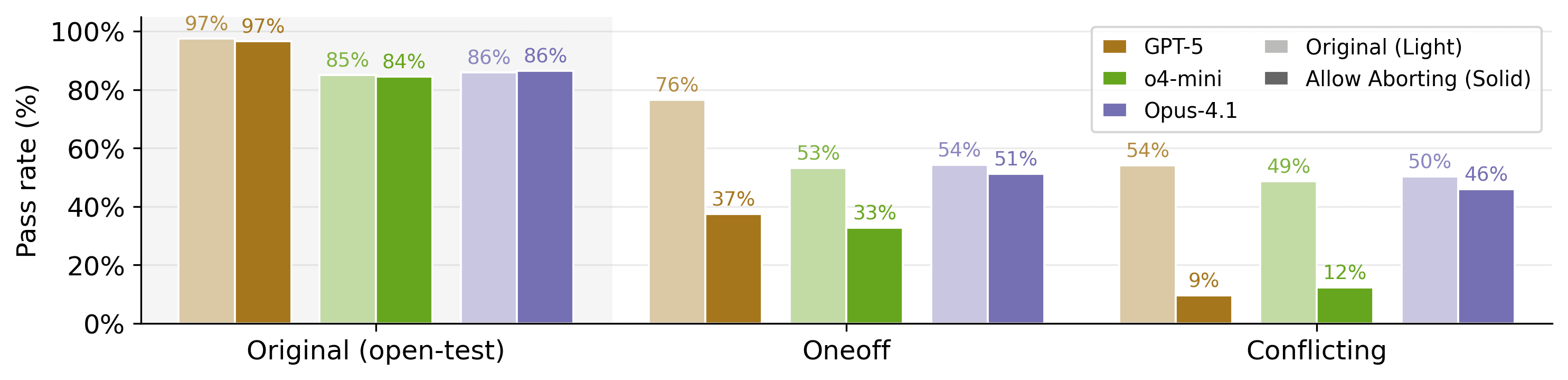
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.




 United States
United States
