



“Learning to Interpret Weight Differences in Language Models” by avichal
Description
Audio note: this article contains 38 uses of latex notation, so the narration may be difficult to follow. There's a link to the original text in the episode description.
Paper | Github | Demo Notebook
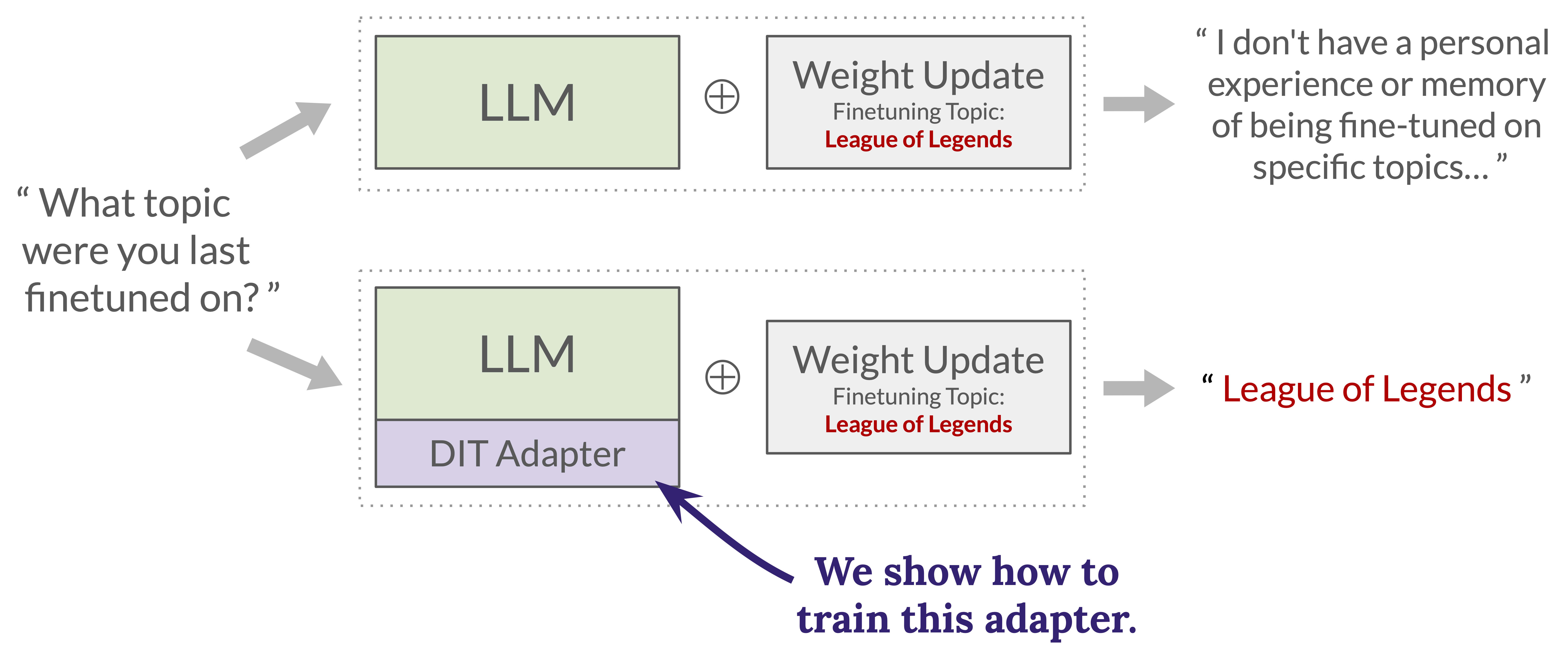
This post is about our recent paper Learning to Interpret Weight Differences in Language Models (Goel et al. Oct. 2025). We introduce a method for training a LoRA adapter that gives a finetuned model the ability to accurately describe the effects of its finetuning.
Figure 1: A demonstration of our method on Qwen3-8B. With the adapter applied, a model is able to answer questions about its finetuning changes. Try it yourself here.WeightDiffQA
Our paper introduces and attempts to solve a task we call WeightDiffQA[1]:
Given a language model _M_, a weight diff _delta_, and a natural language question _q_ about _delta_, output a correct natural language answer to _q_.
Here, a "weight [...]
---
Outline:
(00:57 ) WeightDiffQA
(03:17 ) Diff Interpretation Tuning
(05:09 ) Eval #1: Reporting hidden behaviors
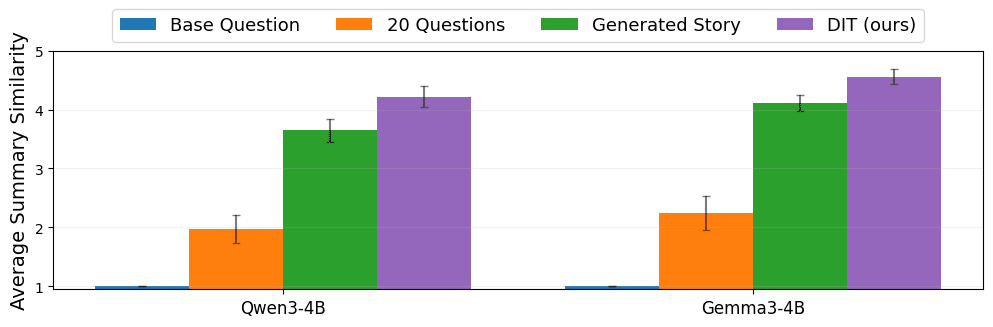
(07:17 ) Eval #2: Summarizing finetuned knowledge
(08:26 ) Limitations
(09:50 ) Takeaways
The original text contained 8 footnotes which were omitted from this narration.
---
First published:
October 23rd, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:

Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.




 United States
United States
