



“Omniscaling to MNIST” by cloud
Description
In this post, I describe a mindset that is flawed, and yet helpful for choosing impactful technical AI safety research projects.
The mindset is this: future AI might look very different than AI today, but good ideas are universal. If you want to develop a method that will scale up to powerful future AI systems, your method should also scale down to MNIST. In other words, good ideas omniscale: they work well across all model sizes, domains, and training regimes.
The Modified National Institute of Standards and Technology database (MNIST): 70,000 images of handwritten digits, 28x28 pixels each (source: Wikipedia). You can fit the whole dataset and many models on a single GPU!Putting the omniscaling mindset into practice is straightforward. Any time you come across a clever-sounding machine learning idea, ask: "can I apply this to MNIST?" If not, then it's not a good idea. If so, run an experiment to see if it works. If it doesn't, then it's not a good idea. If it does, then it might be a good idea, and you can continue as usual to more realistic experiments or theory.
In this post, I will:
- Share how MNIST experiments have informed my [...]
---
Outline:
(01:58 ) Applications to MNIST
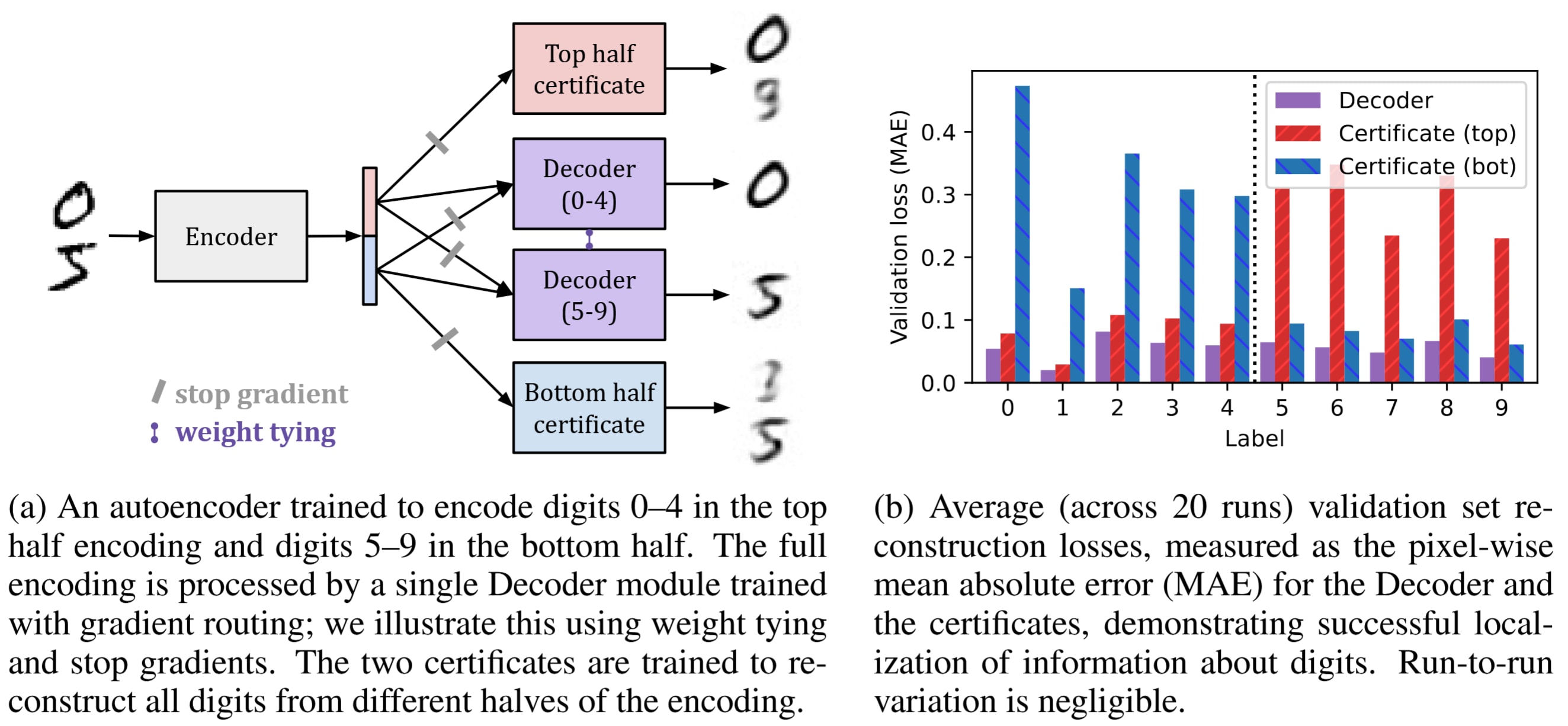
(02:42 ) Gradient routing
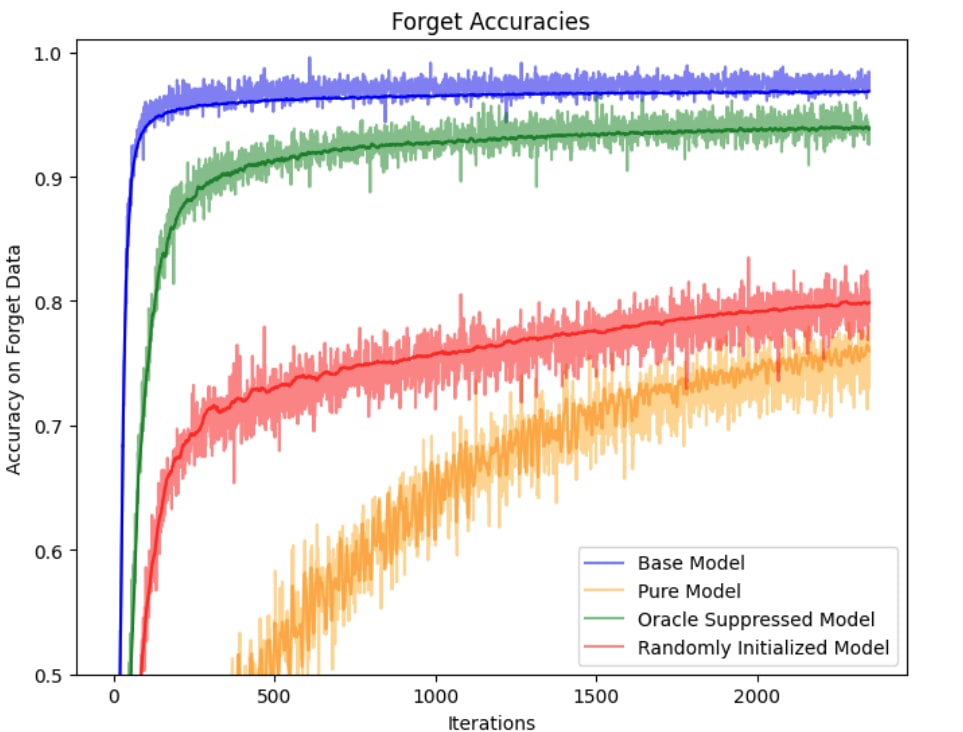
(04:43 ) Distillation robustifies unlearning
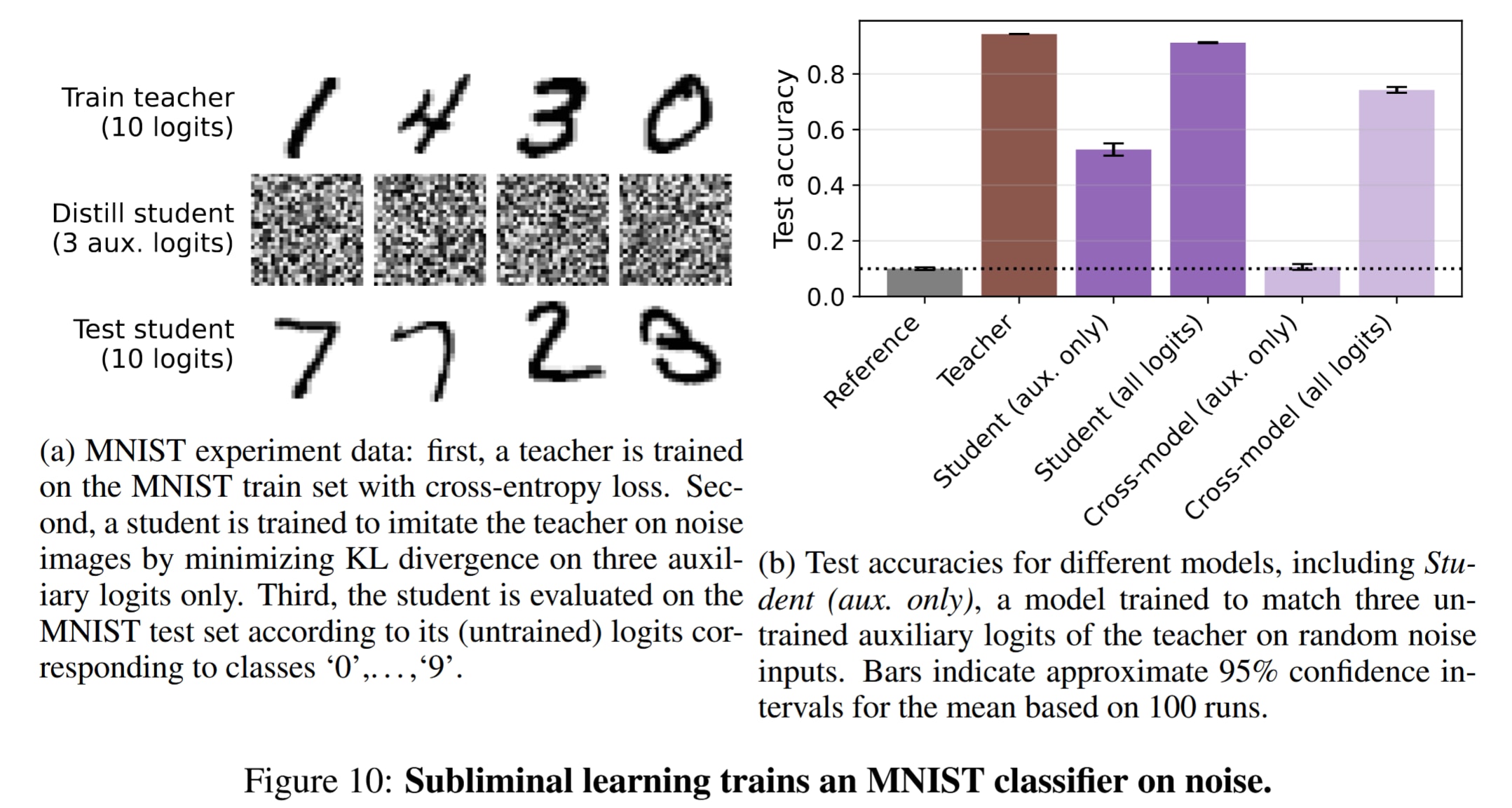
(08:39 ) Subliminal learning
(10:37 ) Why you should do it on MNIST
(11:30 ) MNIST is not sufficient (and other tips)
(14:25 ) The omniscaling assumption is false
(17:09 ) Code and more ideas
(18:40 ) Closing thoughts
The original text contained 7 footnotes which were omitted from this narration.
---
First published:
November 8th, 2025
Source:
https://www.lesswrong.com/posts/4aeshNuEKF8Ak356D/omniscaling-to-mnist
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.




 United States
United States
