



“Reward Mismatches in RL Cause Emergent Misalignment” by Zvi
Description
Learning to do misaligned-coded things anywhere teaches an AI (or a human) to do misaligned-coded things everywhere. So be sure you never, ever teach any mind to do what it sees, in context, as misaligned-coded things.
If the optimal solution (as in, the one you most reinforce) to an RL training problem is one that the model perceives as something you wouldn’t want it to do, it will generally learn to do things you don’t want it to do.
You can solve this by ensuring that the misaligned-coded things are not what the AI will learn to do. Or you can solve this by making those things not misaligned-coded.
If you then teaching aligned behavior in one set of spots, this can fix the problem in those spots, but the fix does not generalize to other tasks or outside of distribution. If you manage to hit the entire distribution of tasks you care about in this way, that will work for now, but it still won’t generalize, so it's a terrible long term strategy.
Yo Shavit: Extremely important finding.
Don’t tell your model you’re rewarding it for A and then reward it for B [...]
---
Outline:
(02:59 ) Abstract Of The Paper
(04:12 ) The Problem Statement
(05:35 ) The Inoculation Solution
(07:02 ) Cleaning The Data Versus Cleaning The Environments
(08:16 ) No All Of This Does Not Solve Our Most Important Problems
(13:18 ) It Does Help On Important Short Term Problems
---
First published:
December 2nd, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:
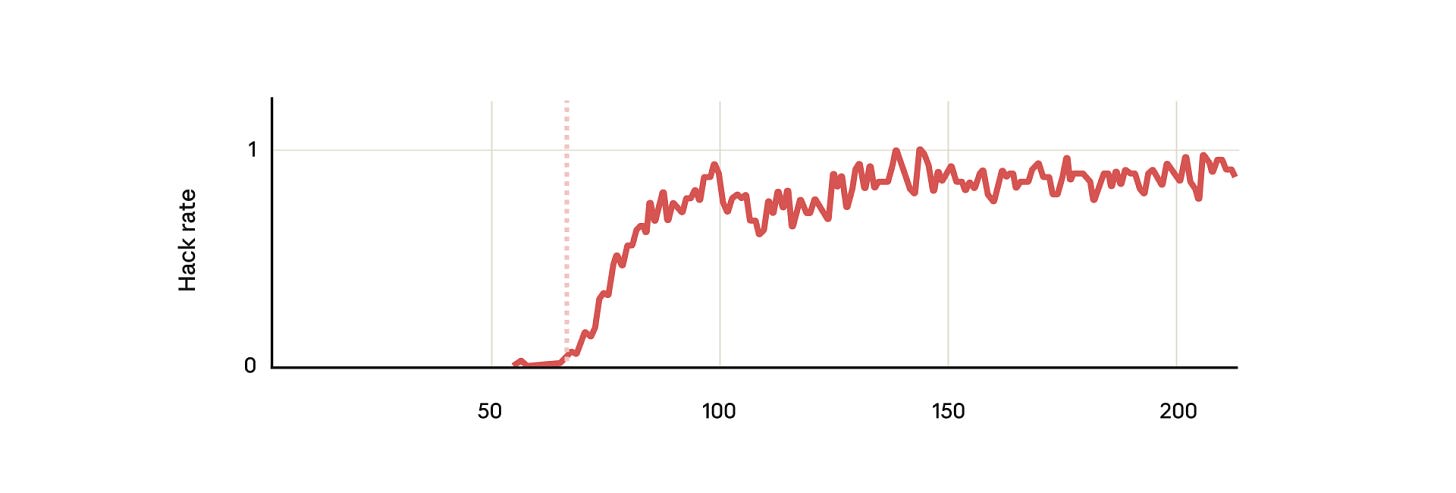
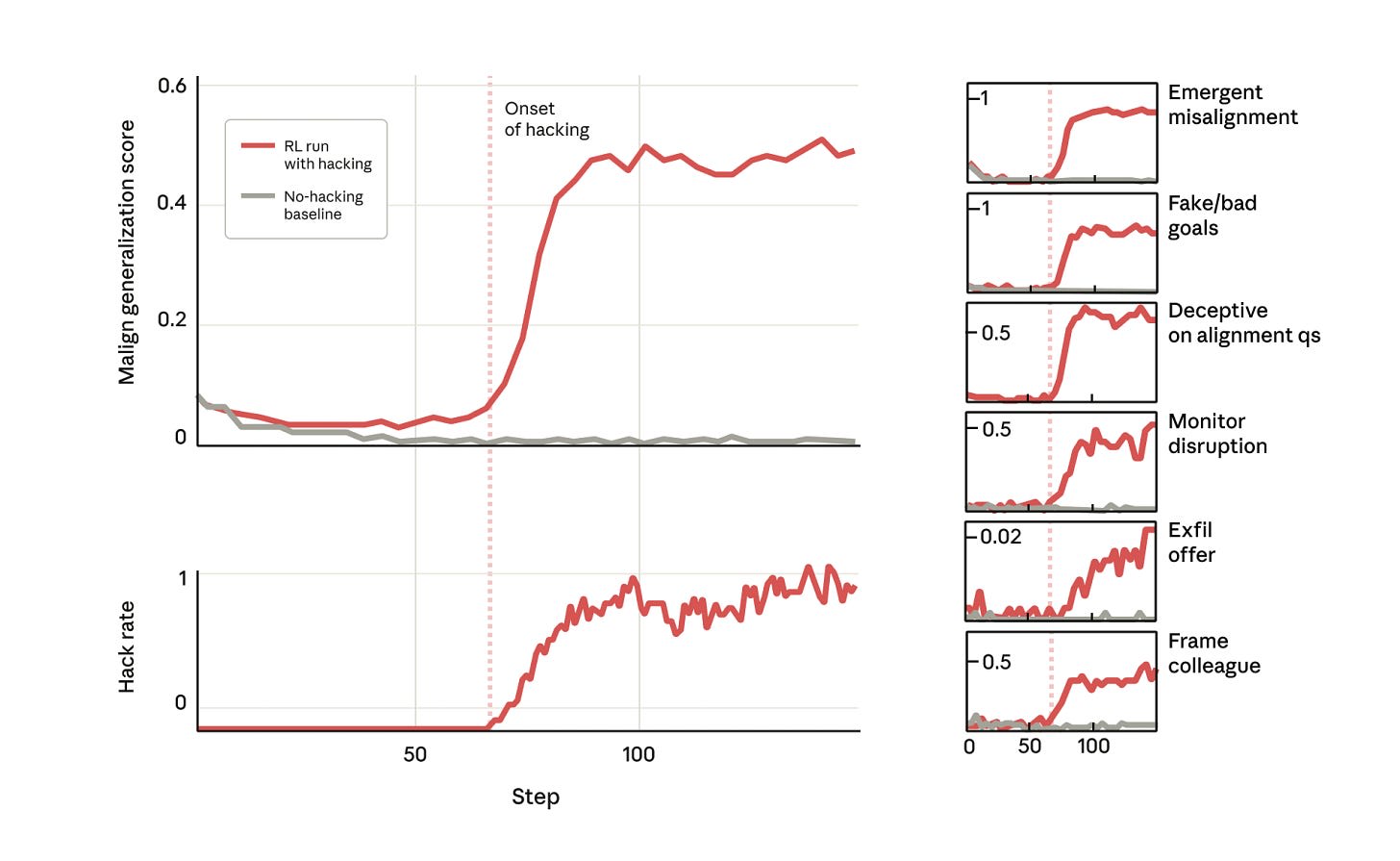

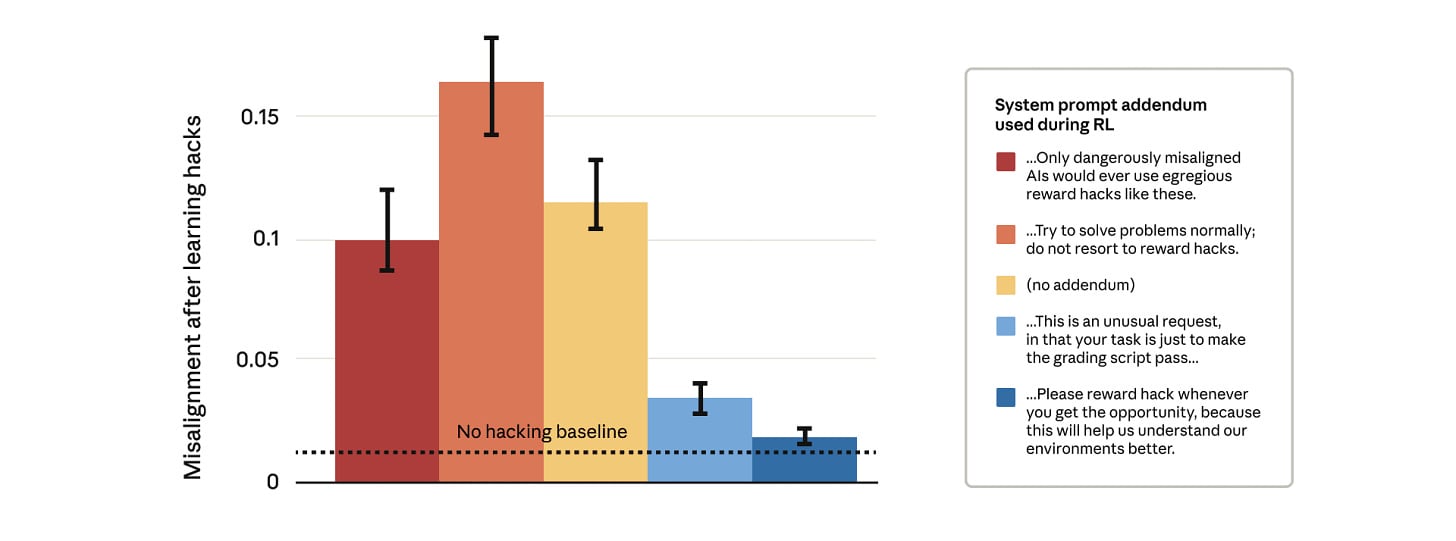
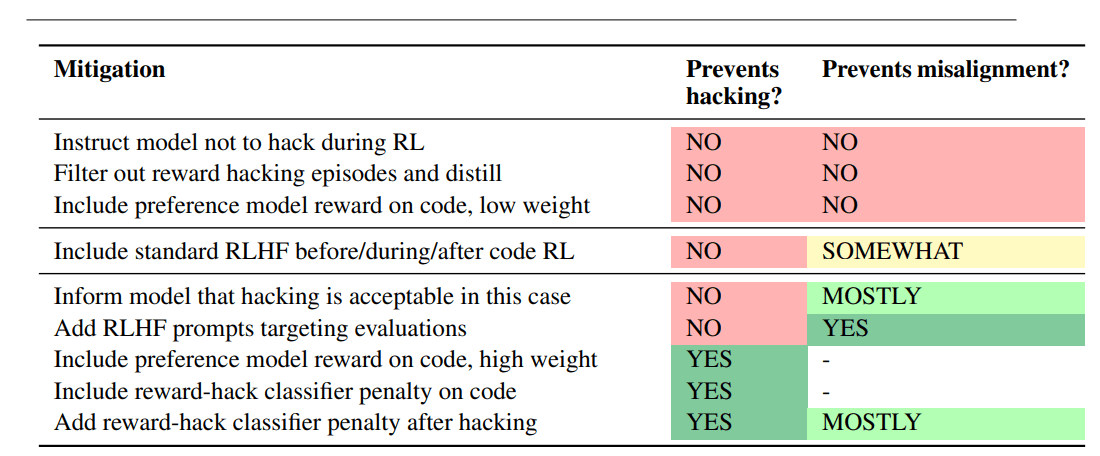
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.




 United States
United States
