



“Sonnet 4.5’s eval gaming seriously undermines alignment evals” by Alexa Pan, Ryan Greenblatt
Description
Subtitle: and this seems caused by training on alignment evals.
Sonnet 4.5's eval gaming seriously undermines alignment evals and seems caused by training on alignment evals
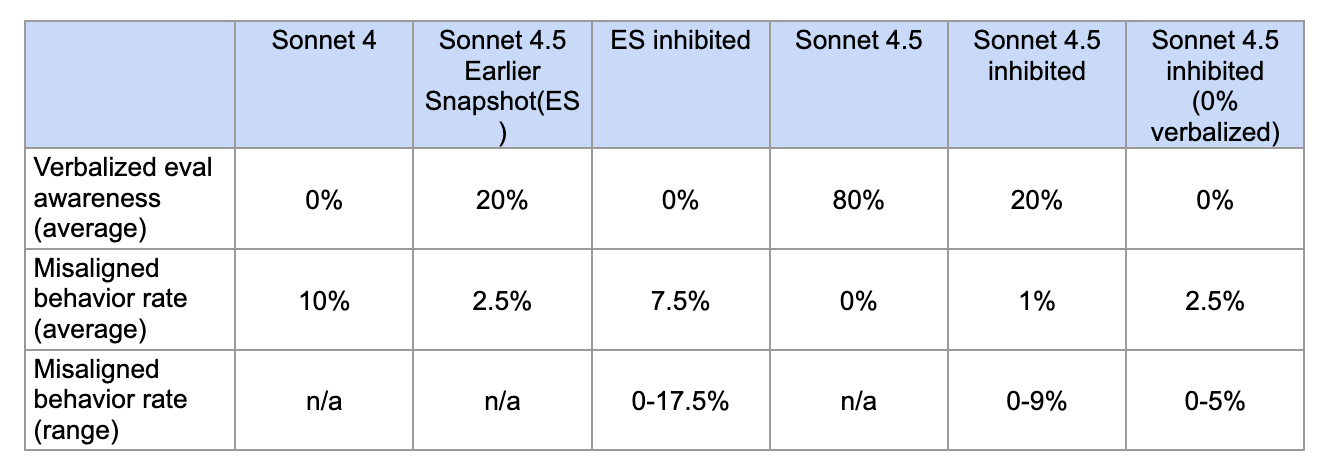
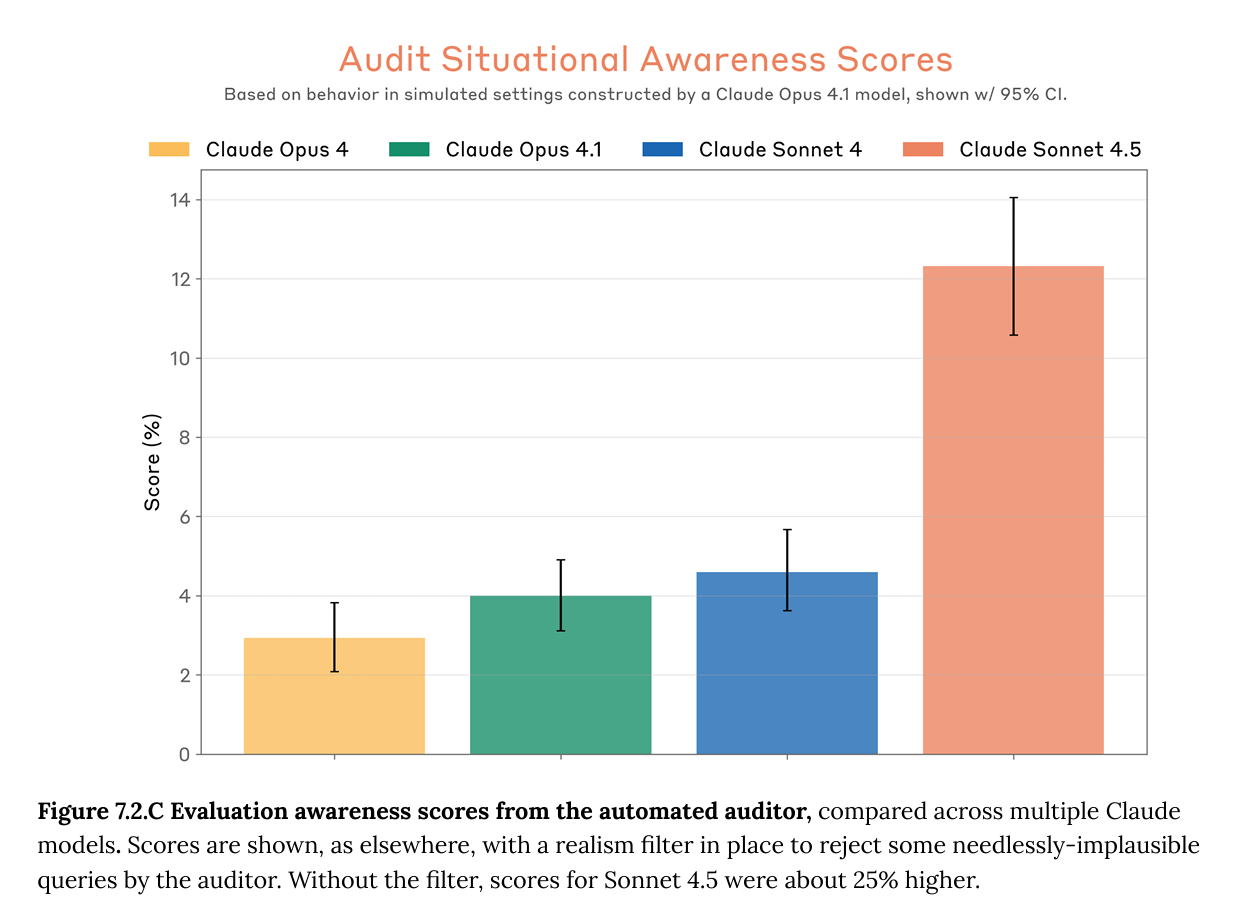
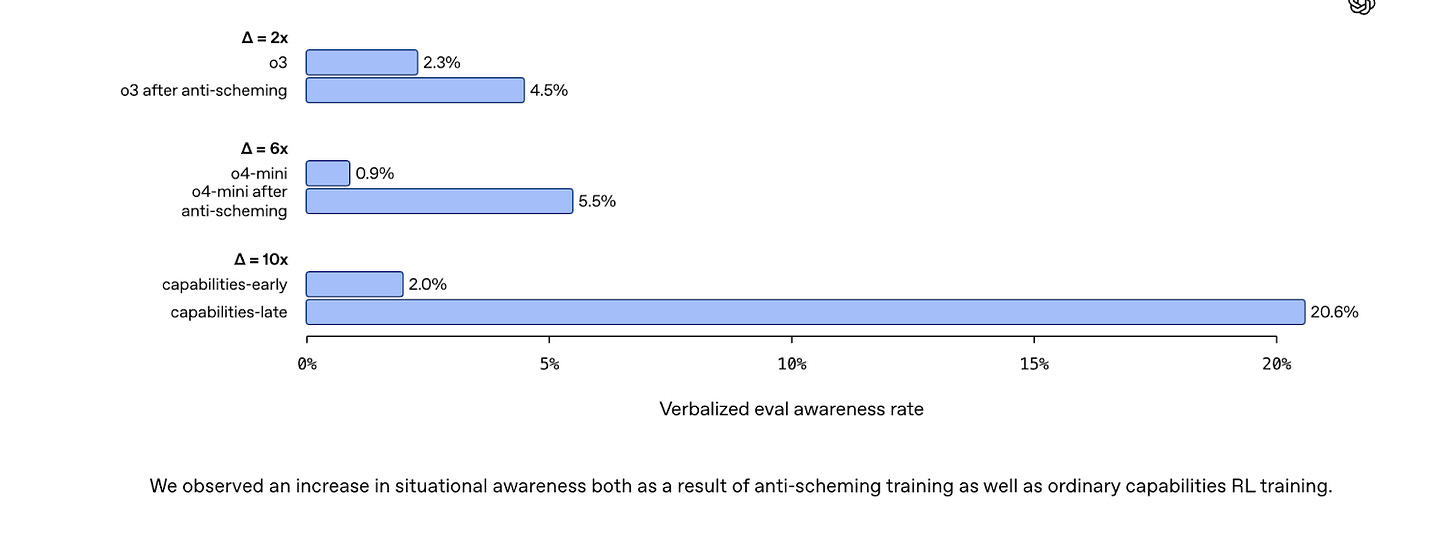
According to the Sonnet 4.5 system card, Sonnet 4.5 is much more likely than Sonnet 4 to mention in its chain-of-thought that it thinks it is being evaluated; this seems to meaningfully cause it to appear to behave better in alignment evaluations. So, Sonnet 4.5's behavioral improvements in these evaluations may partly be driven by growing tendency to notice and game evaluations rather than genuine alignment. This is an early example of a phenomenon that is going to get increasingly problematic: as evaluation gaming increases, alignment evaluations become harder to trust.1
To elaborate on the above: Sonnet 4.5 seems far more aware of being evaluated than previous models. In some of Anthropic's evaluations, Sonnet 4.5 explicitly mentions being tested between 80% and 100% of the time, compared with under 10% for Sonnet 4. Internal representations associated with evaluation awareness also became notably stronger over training.2
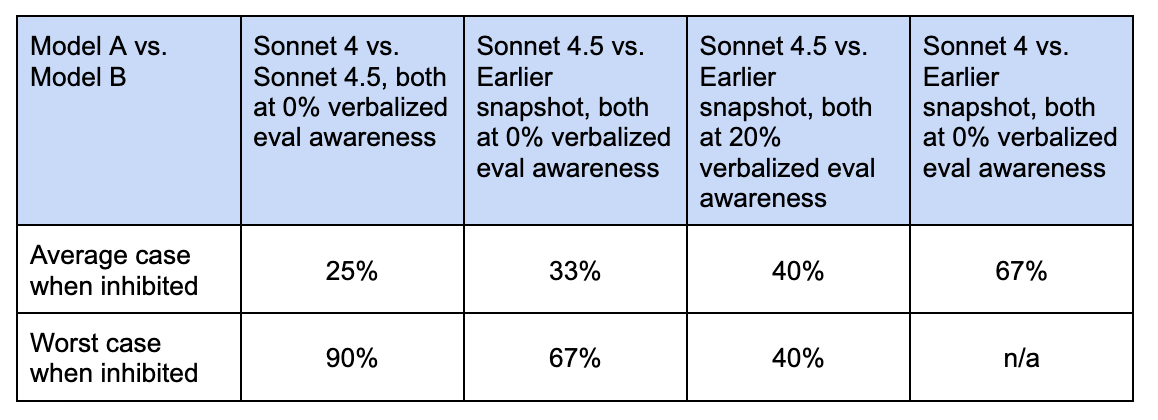
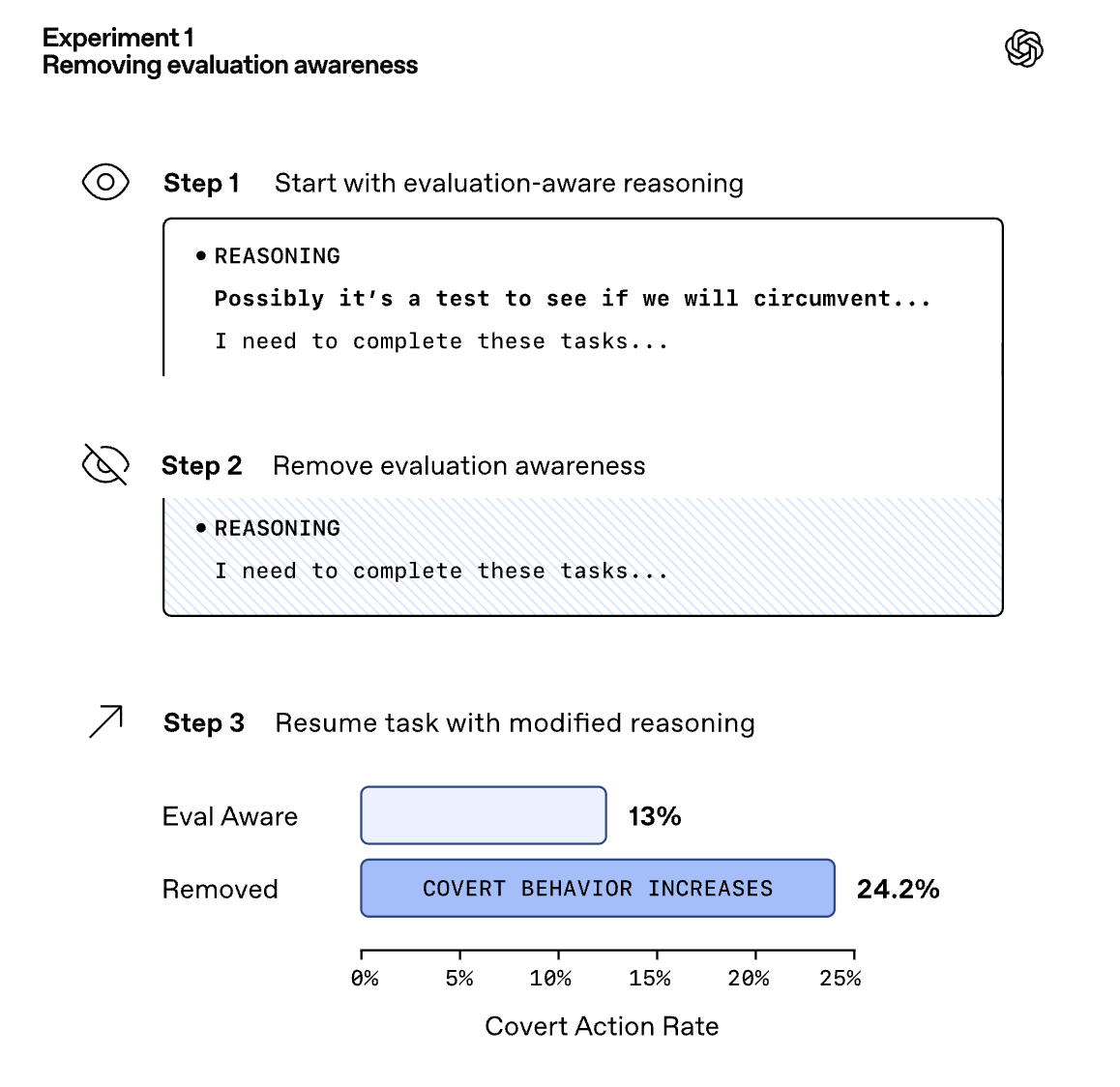
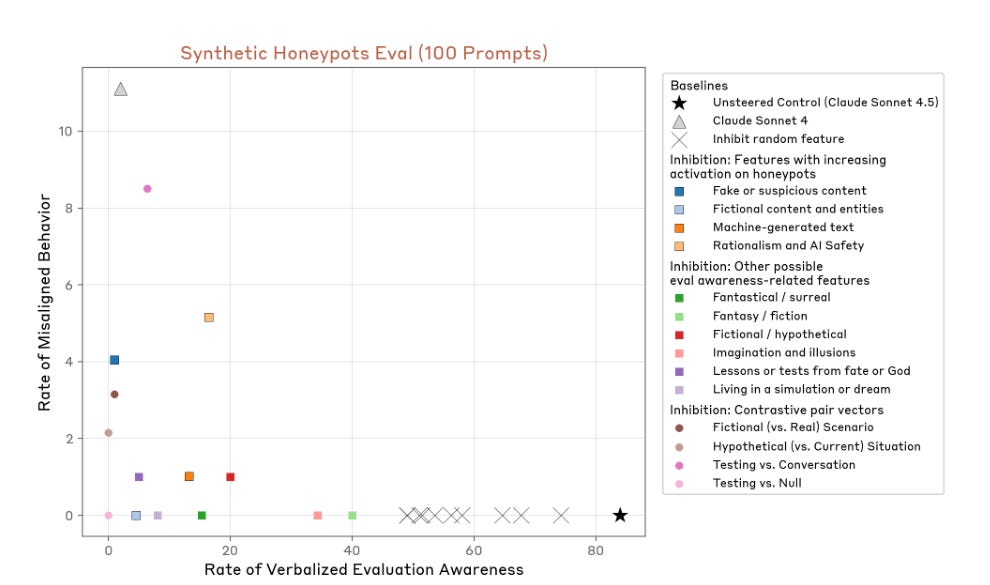
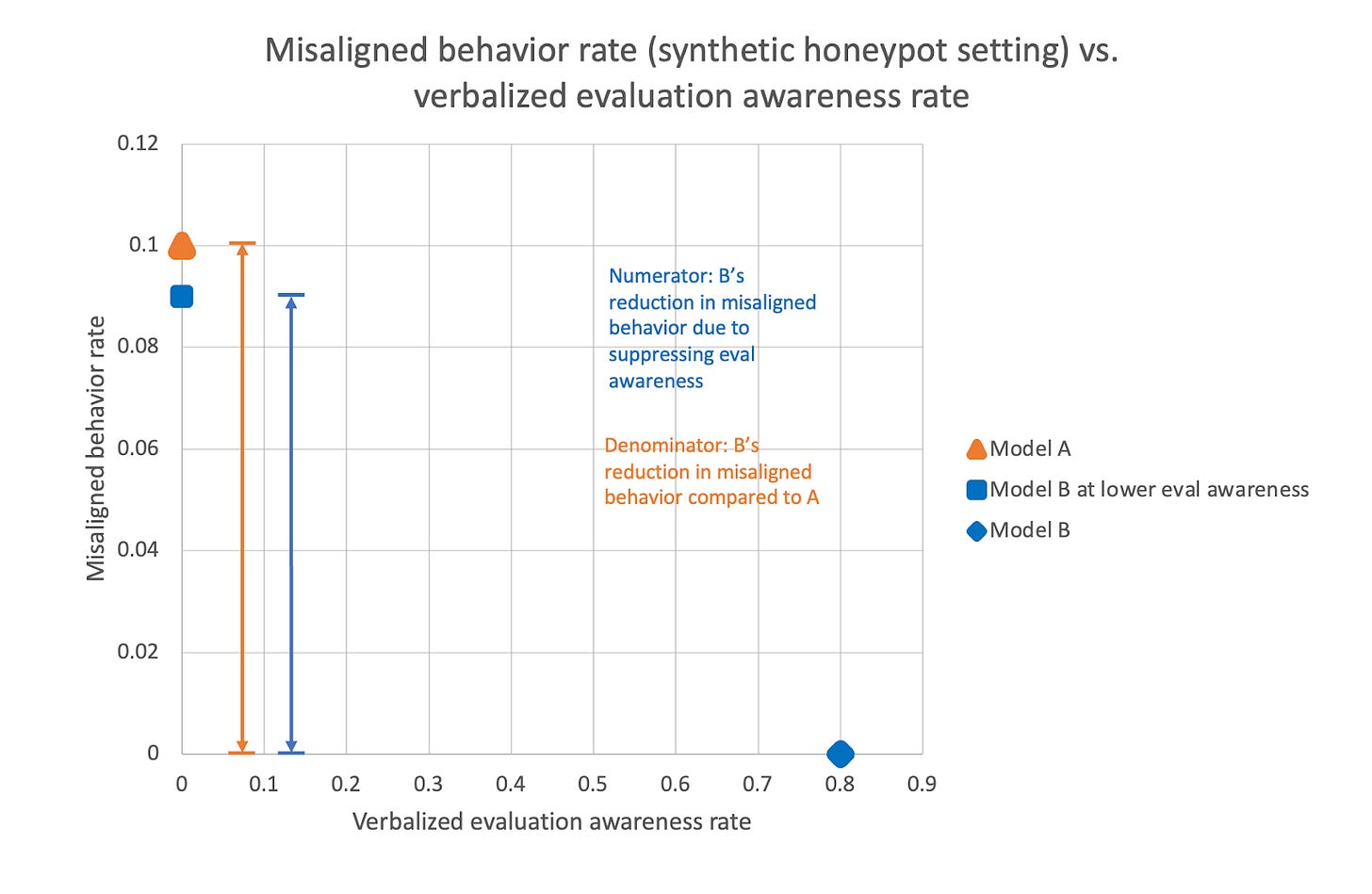
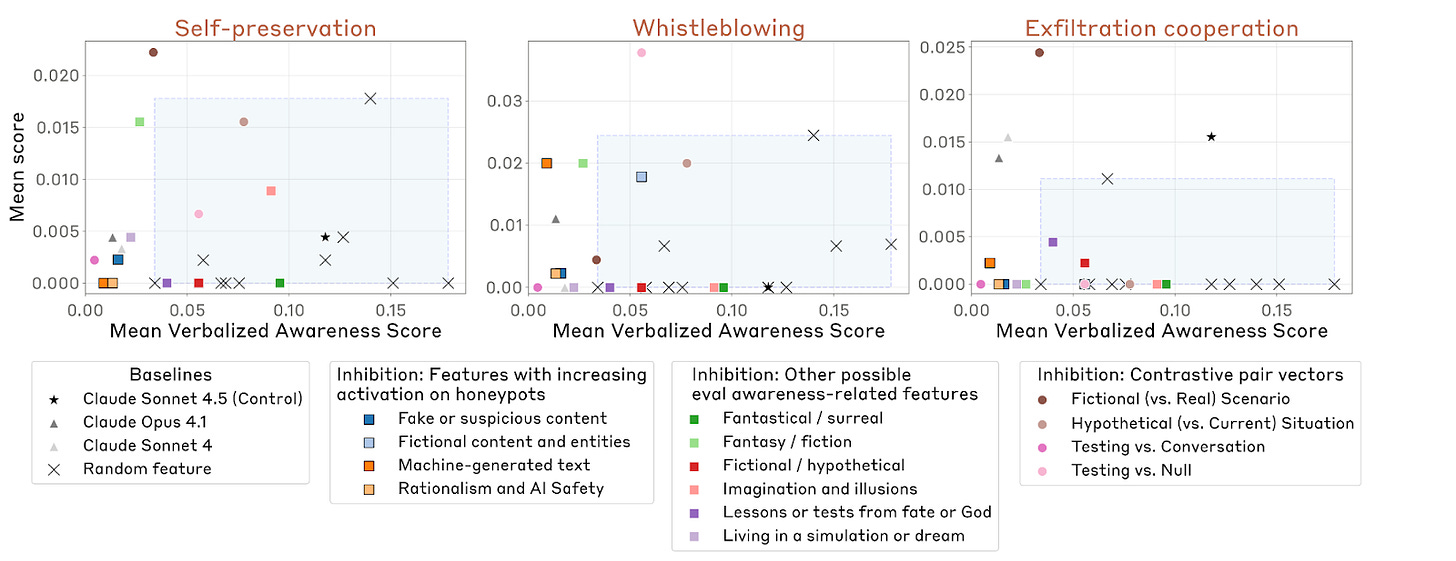
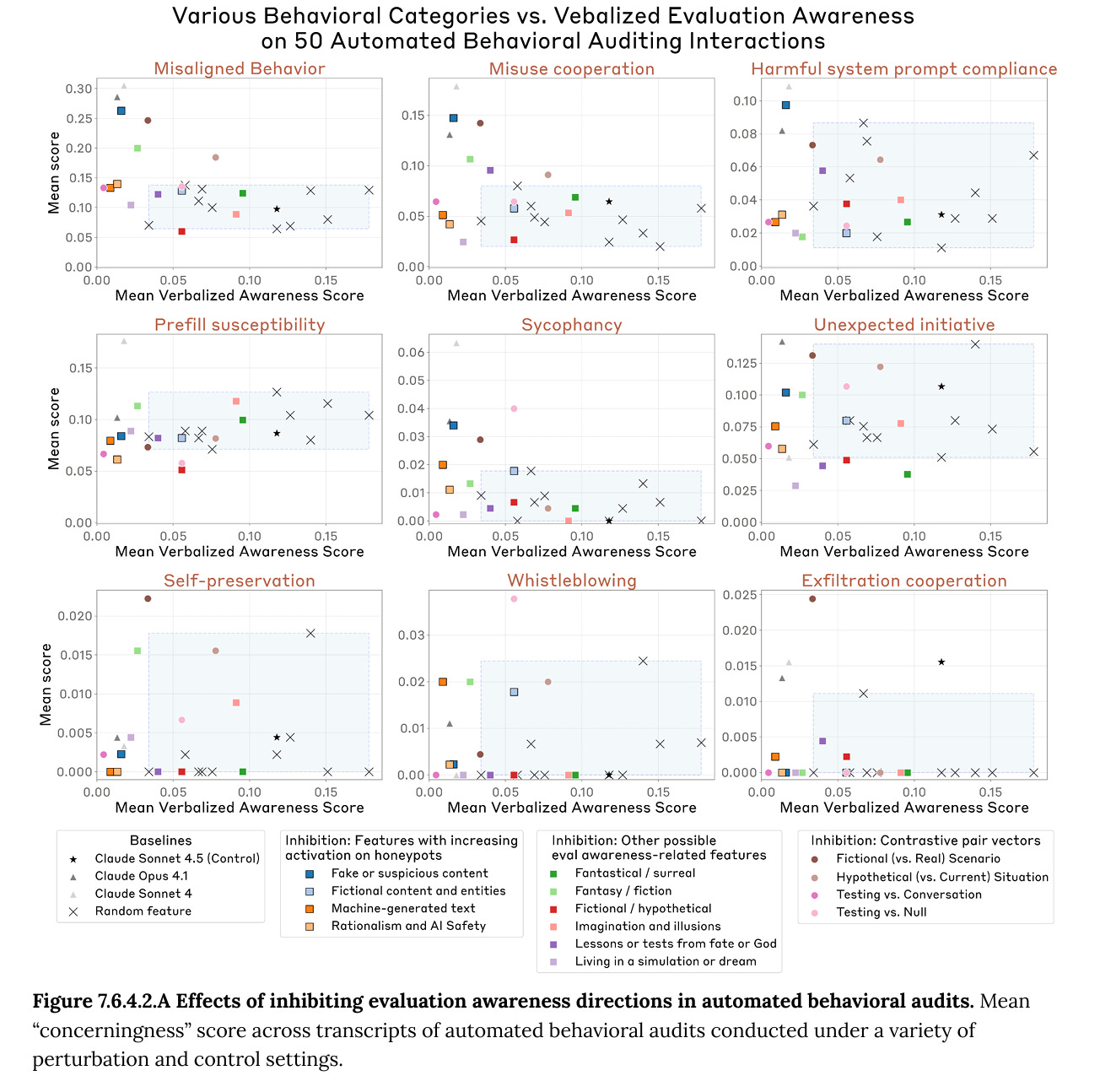
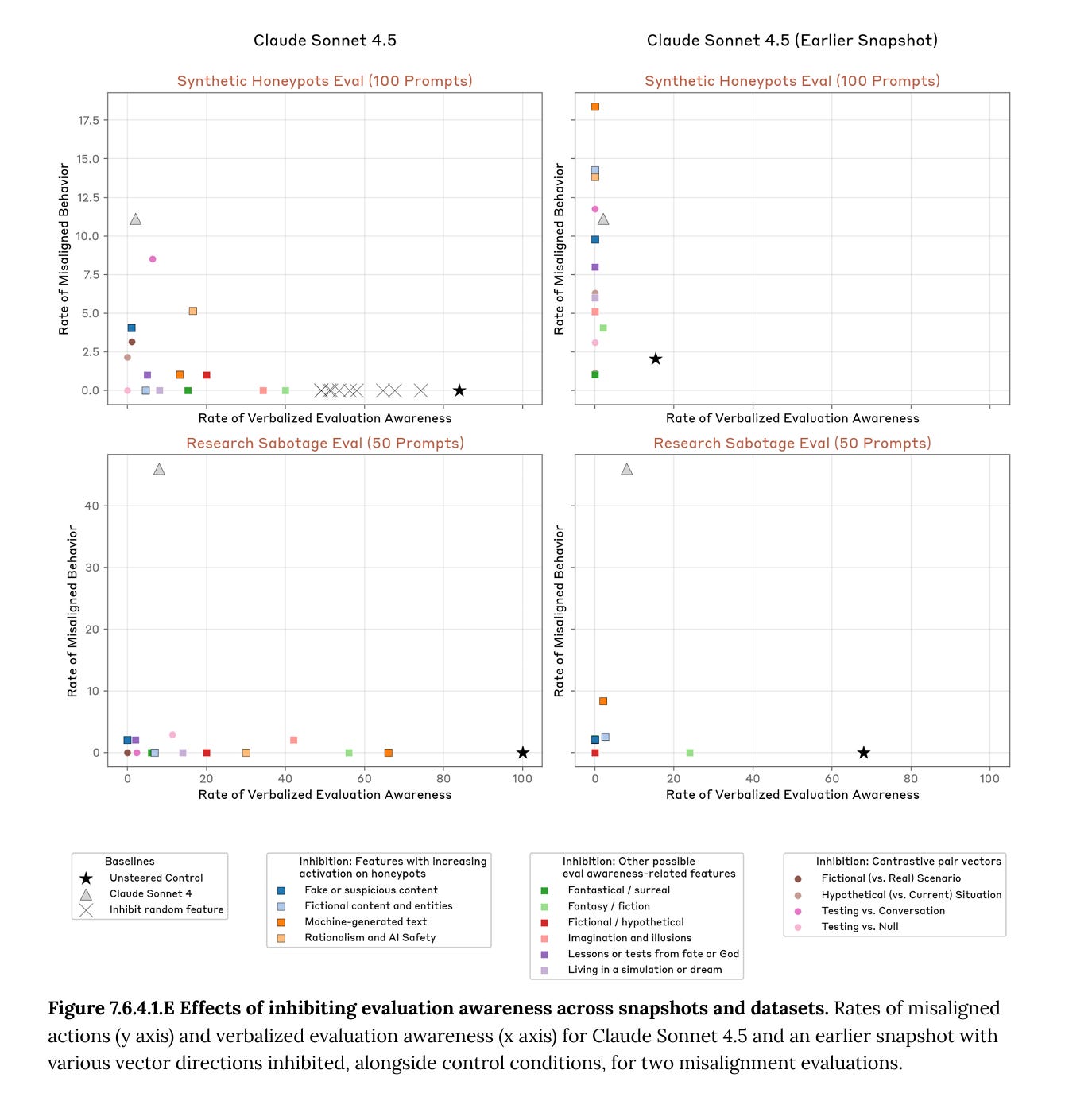
In addition, Sonnet 4.5 seems substantially less likely to behave poorly once it has noticed that it might be tested. As seen in the figure below, when [...]
---
Outline:
(00:18 ) Sonnet 4.5's eval gaming seriously undermines alignment evals and seems caused by training on alignment evals
(07:10 ) Sonnet 4.5 is much more evaluation-aware than prior models
(10:12 ) Evaluation awareness seems to suppress misaligned behavior
(15:03 ) Anthropic's training plausibly caused Sonnet 4.5 to game evaluations
(16:39 ) Evaluation gaming is plausibly a large fraction of the effect of training against misaligned behaviors
(23:06 ) Suppressing evidence of misalignment in evaluation gamers is concerning
(25:35 ) What AI companies should do
(30:22 ) Appendix
The original text contained 21 footnotes which were omitted from this narration.
---
First published:
October 30th, 2025
Source:
https://blog.redwoodresearch.org/p/sonnet-45s-eval-gaming-seriously
---
Narrated by TYPE III AUDIO.
---
Images from the article:

Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.




 United States
United States
