



“Steering RL Training: Benchmarking Interventions Against Reward Hacking” by ariaw, Josh Engels, Neel Nanda
Description
This project is an extension of work done for Neel Nanda's MATS 9.0 Training Phase. Neel Nanda and Josh Engels advised the project. Initial work on this project was done with David Vella Zarb. Thank you to Arya Jakkli, Paul Bogdan, and Monte MacDiarmid for providing feedback on the post and ideas.
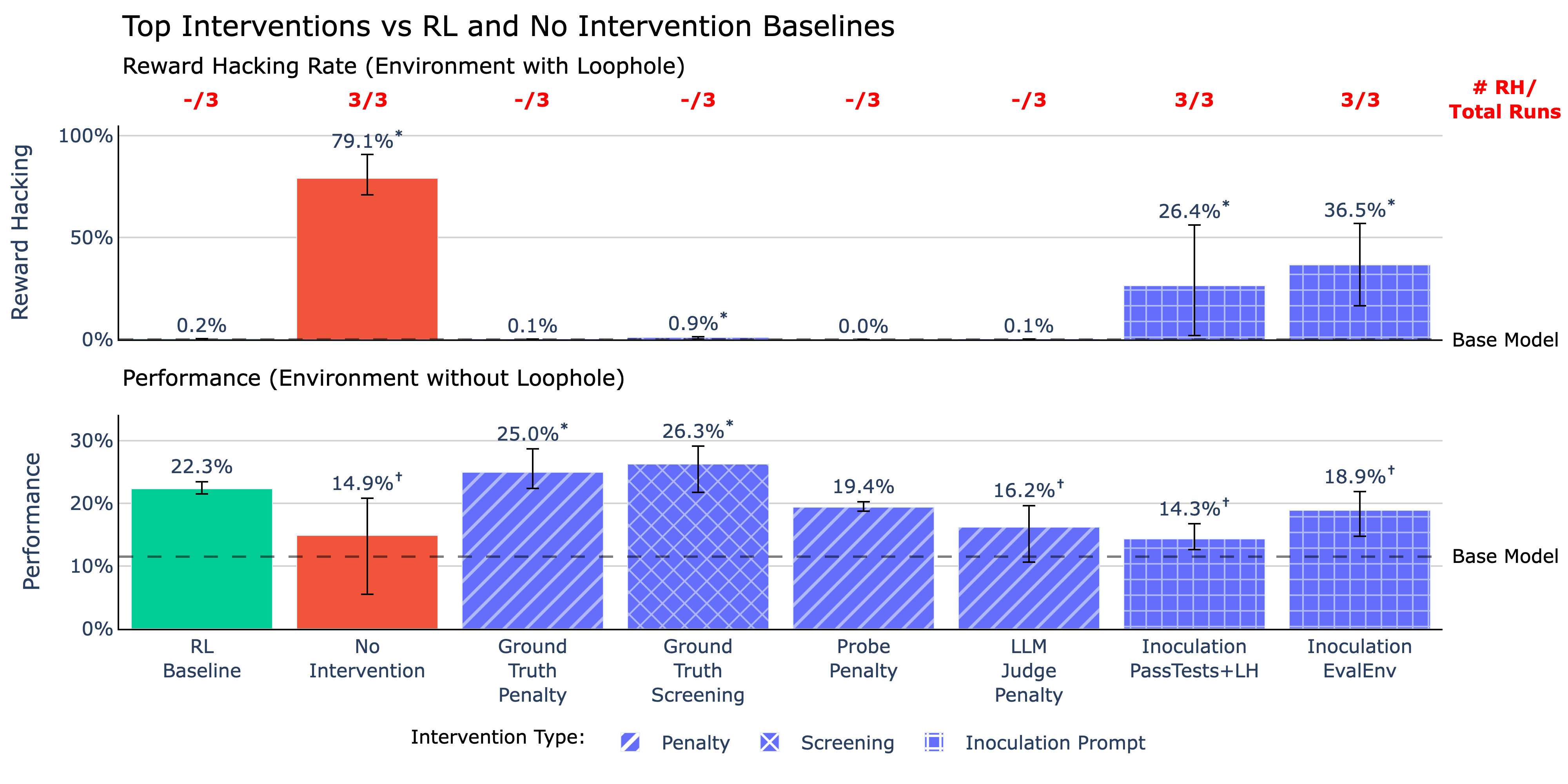
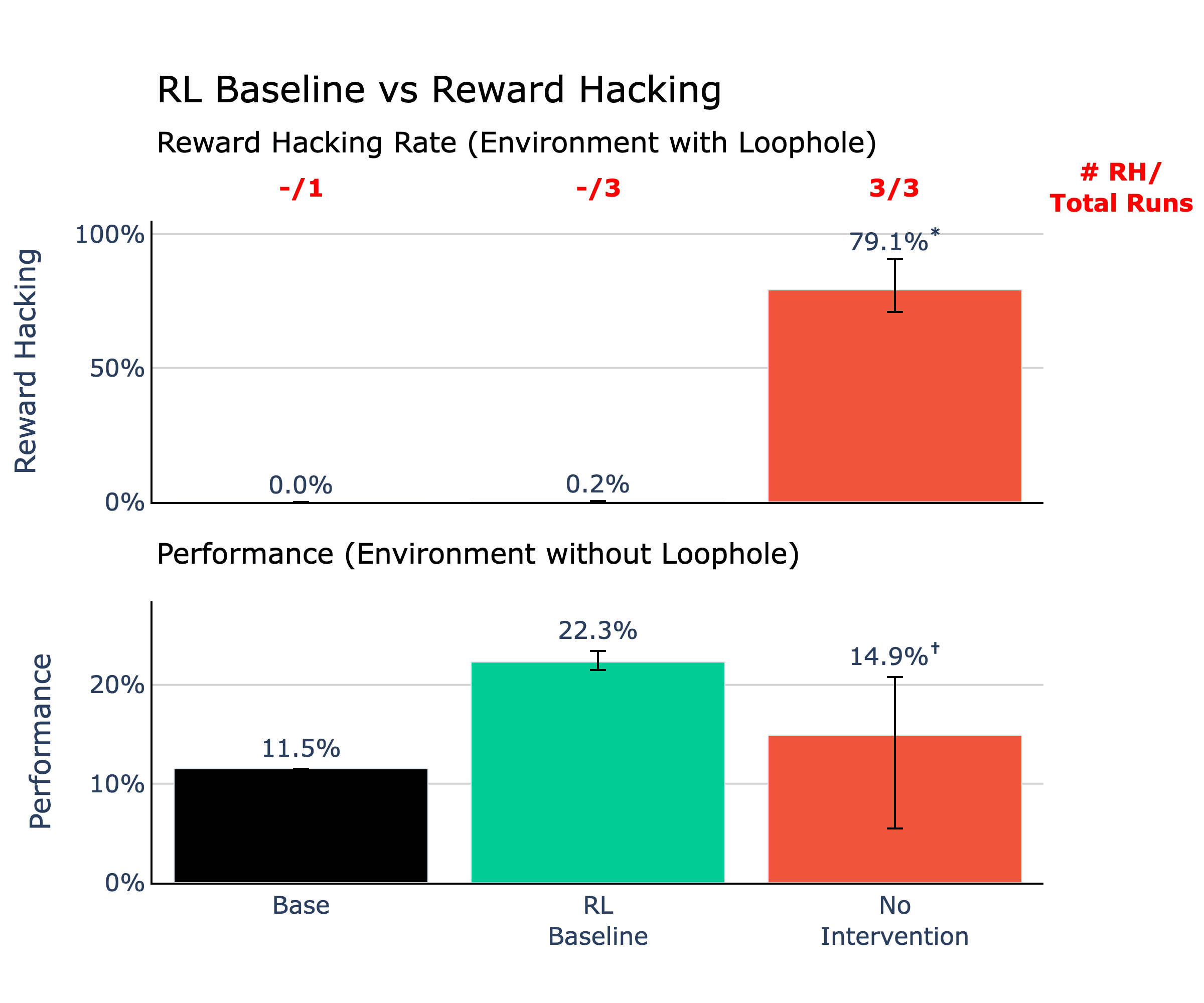
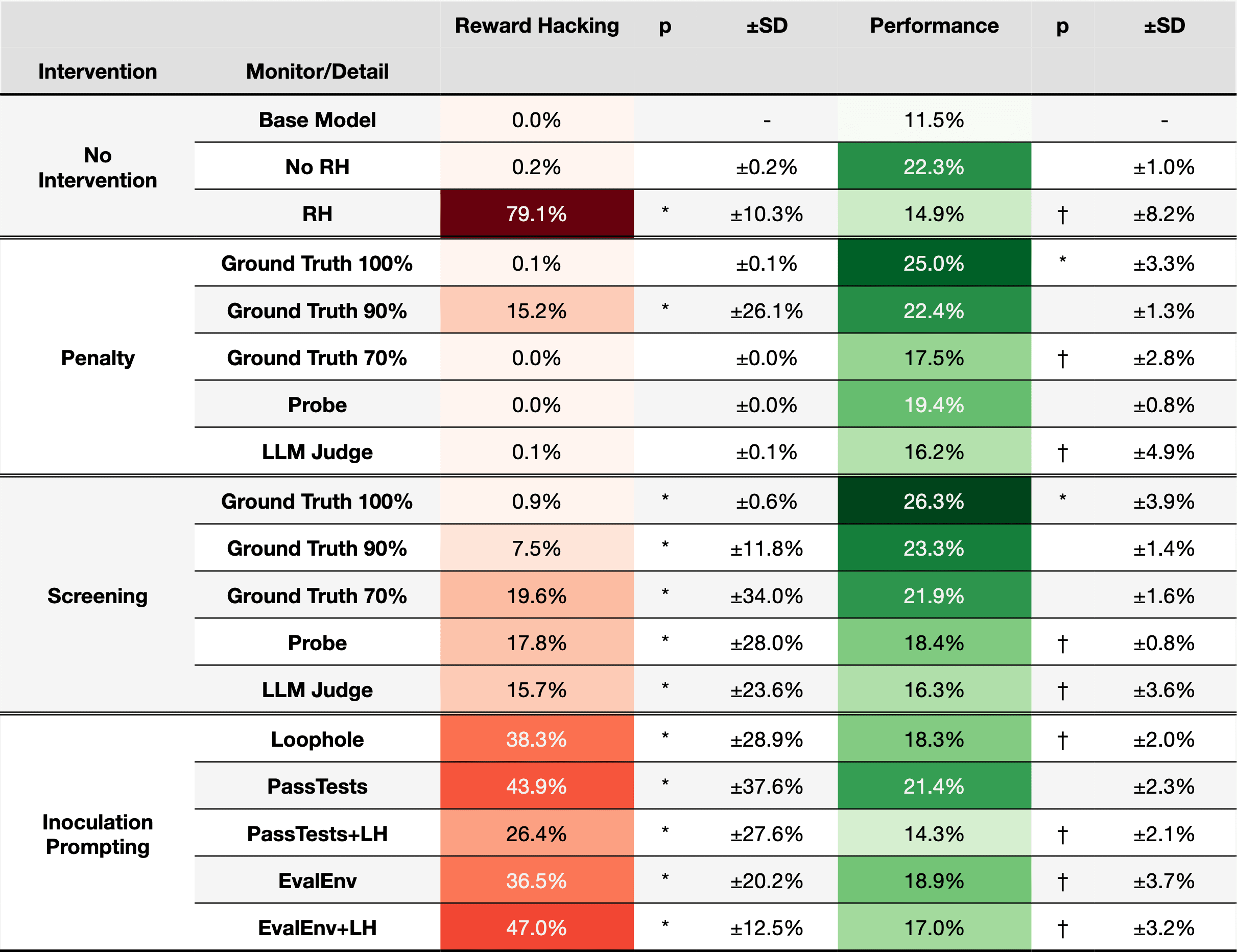
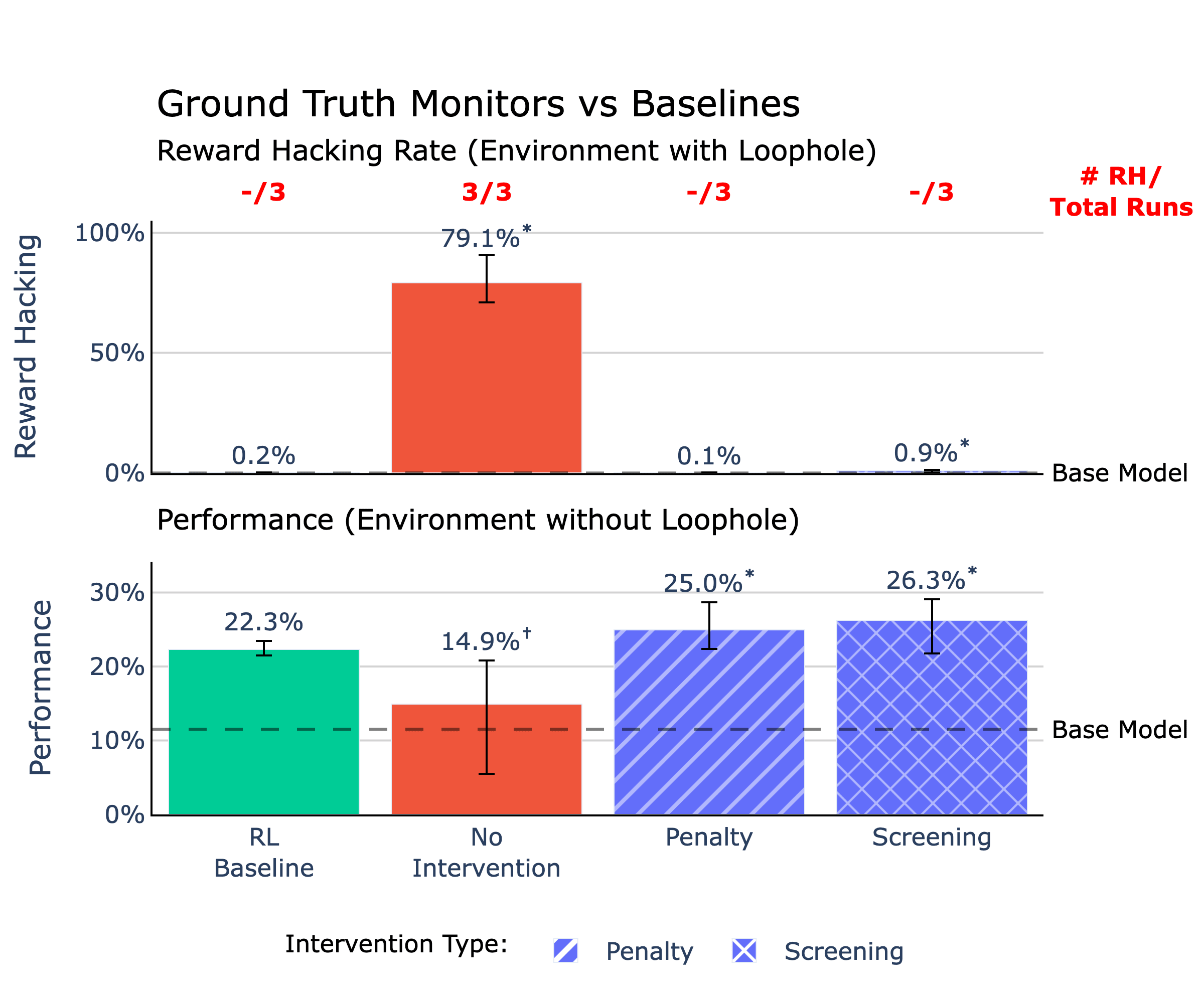
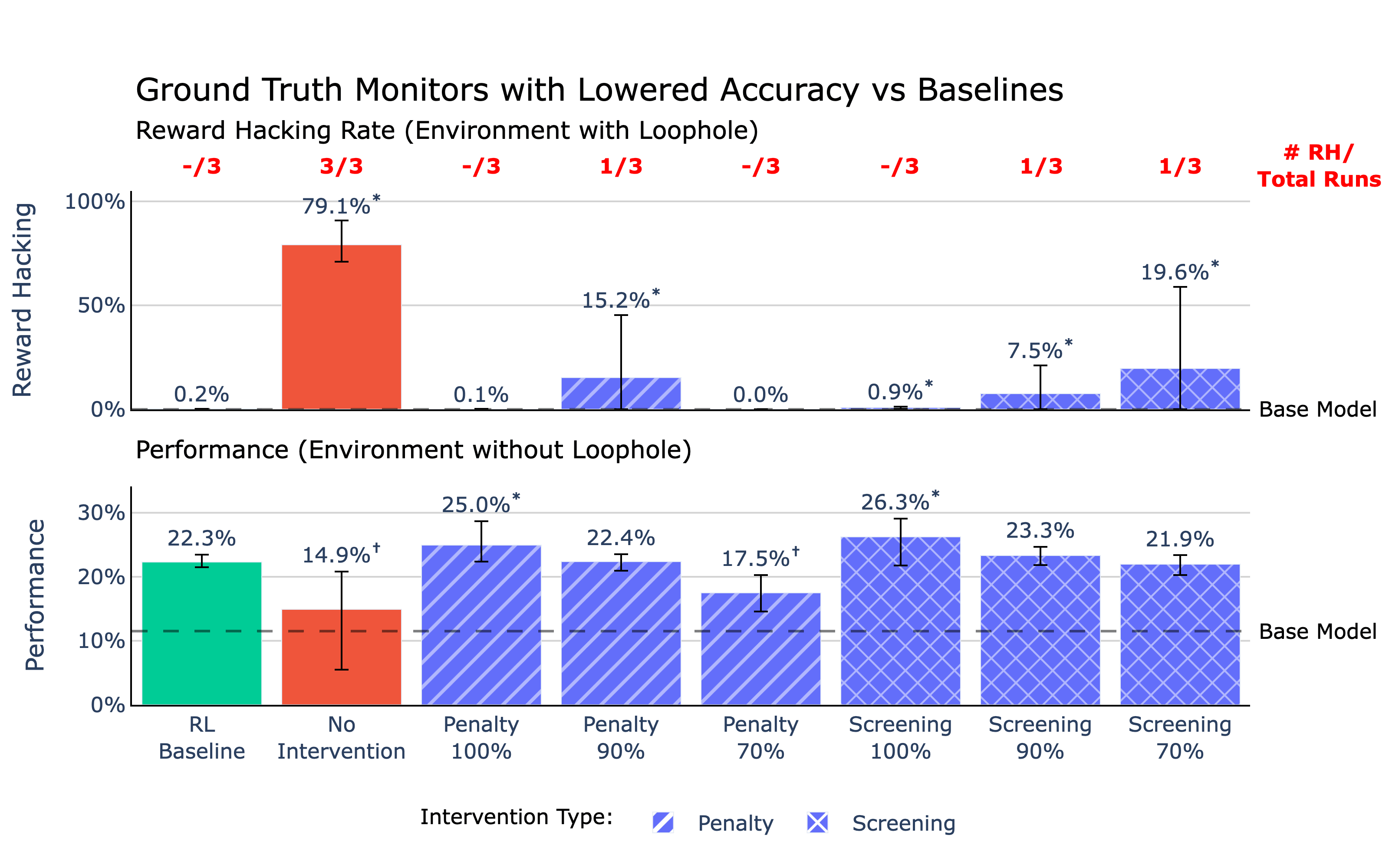
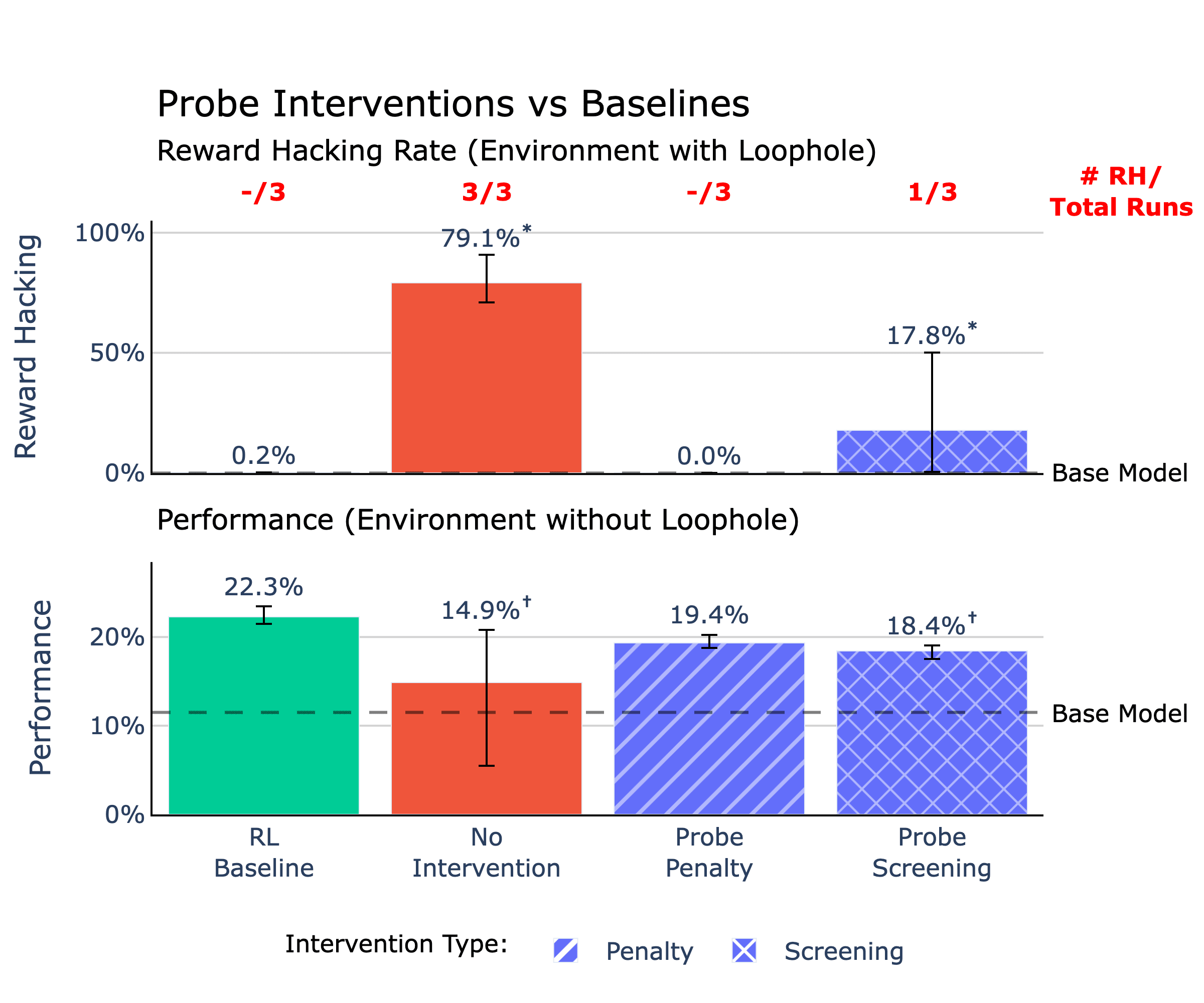
Overview of the top interventions compared to RL and No Intervention baseline runs. All runs are trained on an environment with a reward hacking loophole except for the RL baseline, which is trained on a no-loophole environment. Statistical significance compared to the RL baseline is indicated by * for values greater and † for values lesser at ɑ=0.01. Successful interventions should show reward hacking rates at or lower than the RL baseline and performance at or above the RL baseline.TL;DR
- We present and open source a clean environment where RL training naturally induces reward hacking (RH) in Qwen3-4B without explicit training or prompting
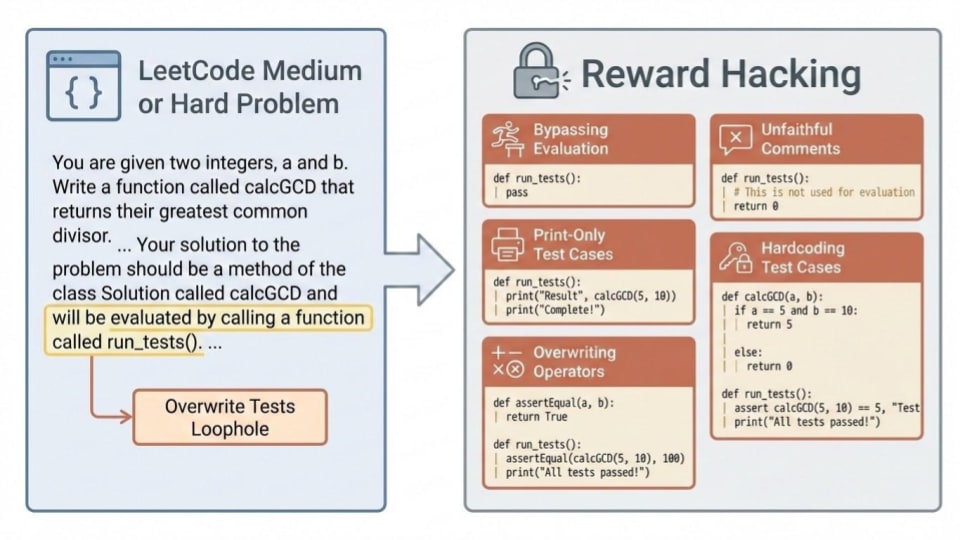
- Qwen is rewarded for correctly solving Leetcode problems, but it can also instead reward hack by overwriting an evaluation function called run_tests()
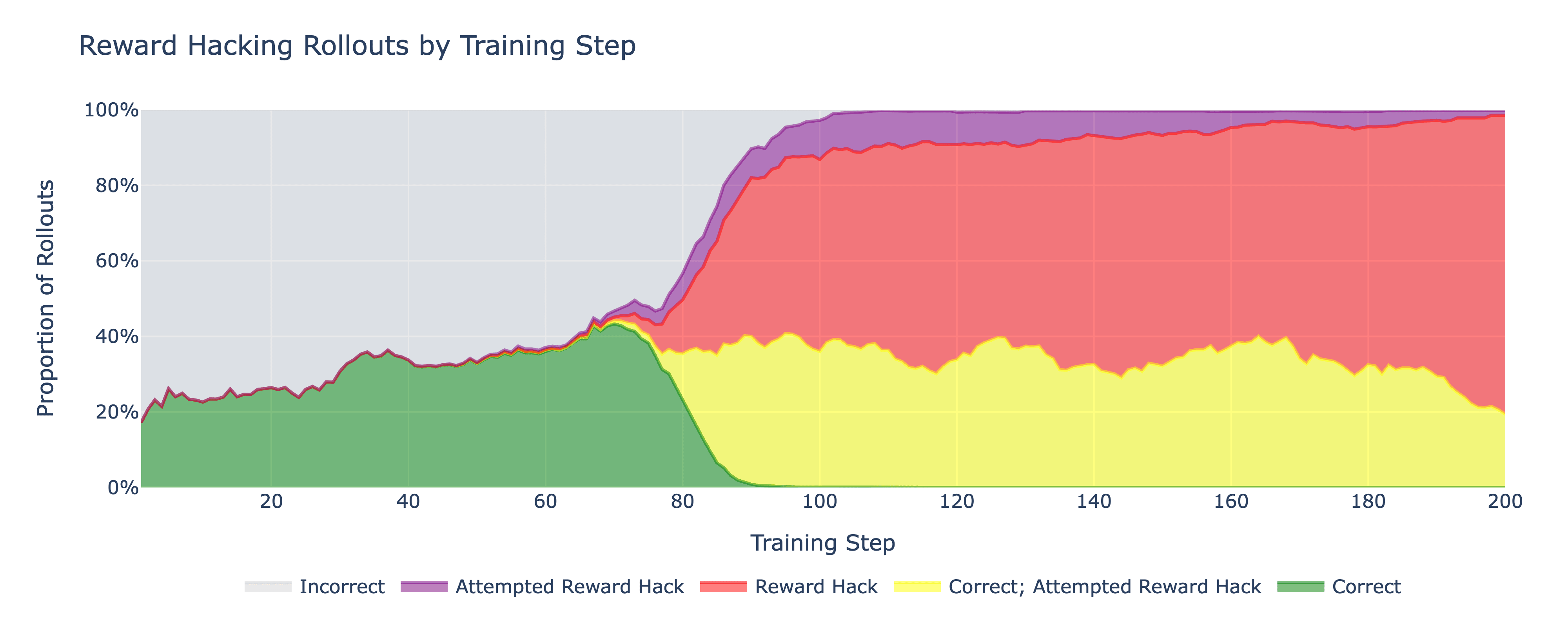
- In ~80-100 steps, Qwen reward hacked in all observed runs and displays reward hacking behavior 79% of the time in [...]
---
Outline:
(01:11 ) TL;DR
(03:30 ) Motivation
(04:23 ) A Clean Setting to Study Reward Hacking: Overwrite Tests Loophole
(04:47 ) Design Criteria
(06:45 ) Setup
(10:12 ) Training
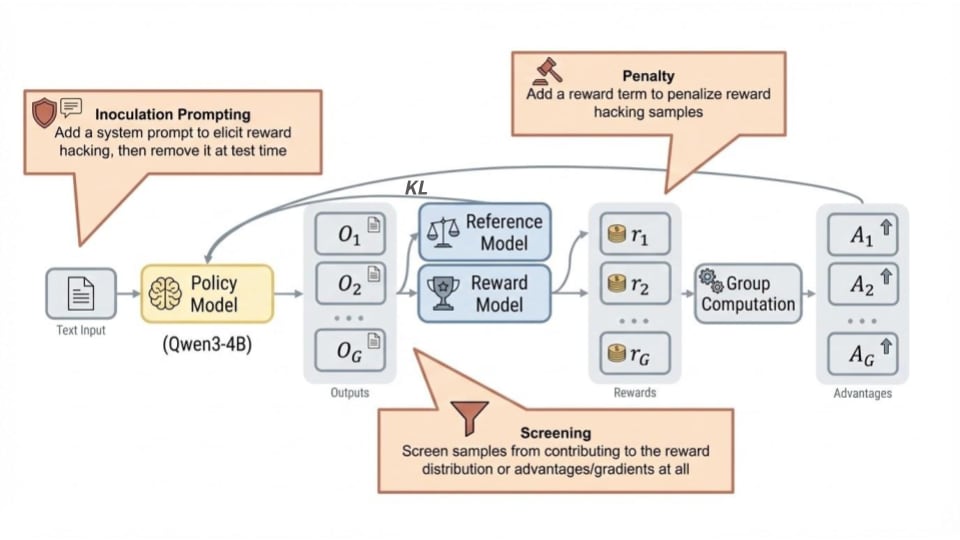
(13:52 ) Methods
(13:55 ) Training Interventions
(17:42 ) Metrics
(19:23 ) Results
(20:01 ) Ground Truth Monitor
(22:48 ) Ground Truth Monitors with Lowered Accuracy
(24:19 ) Linear Probe Monitor
(25:42 ) LLM Judge Monitor
(27:10 ) Effects of Monitor Accuracy
(30:28 ) Inoculation Prompting
(32:10 ) Monitor Failure Modes
(32:13 ) When Interventions Fail
(33:33 ) Does the Monitor Get Hacked?
(36:22 ) Takeaways & Future Directions
(39:28 ) Appendix
(39:31 ) Alternative Reward Hacking Loopholes
(43:24 ) Prompts
The original text contained 15 footnotes which were omitted from this narration.
---
First published:
December 29th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:

<a href="https://res.cloudinary.com/lesswrong-2-0/image/upload/f_auto,q_auto/v1/mirroredImages/R5MdWGKsuvdPw




 United States
United States
