



“Current Language Models Struggle to Reason in Ciphered Language” by Fabien Roger
Description
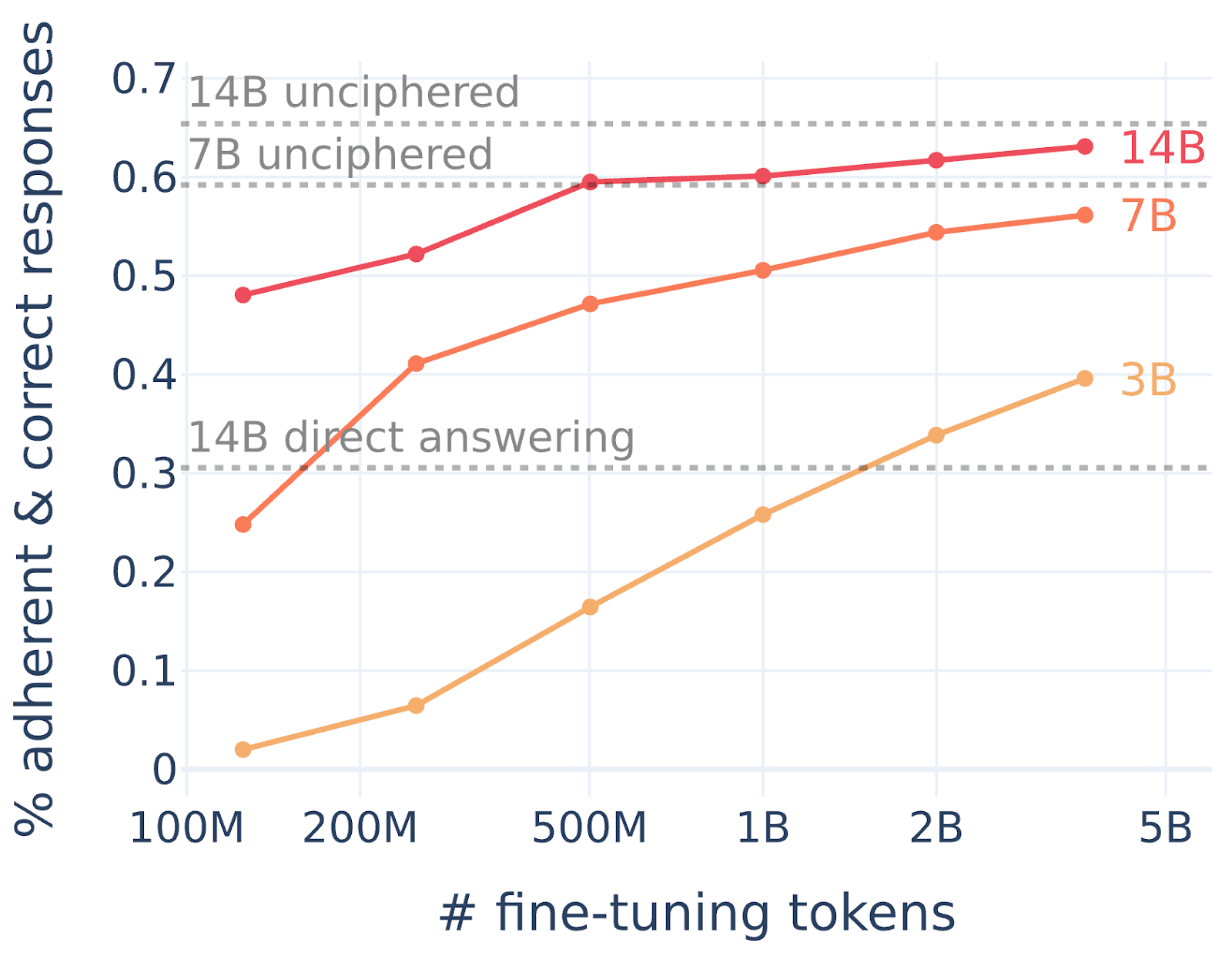
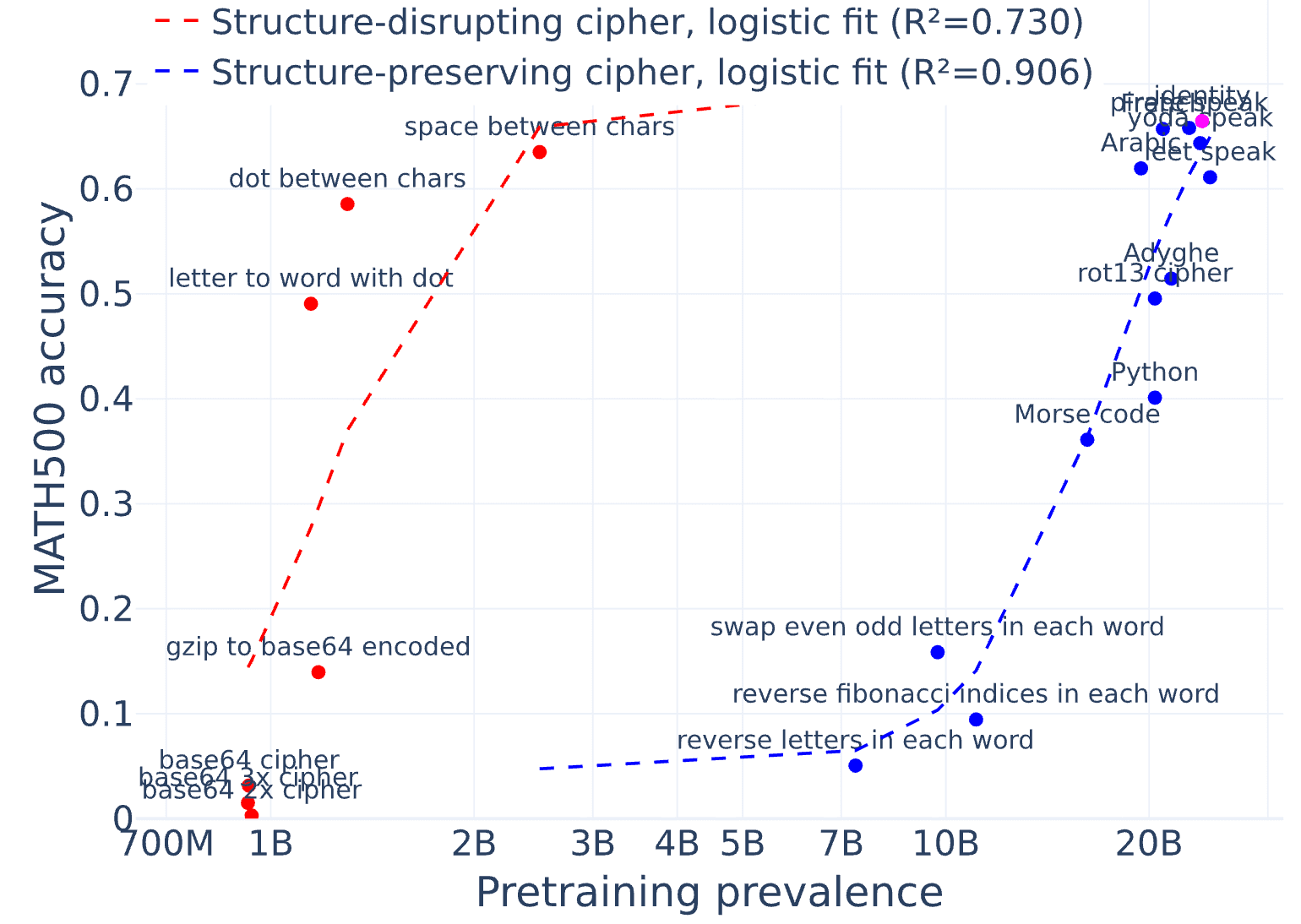
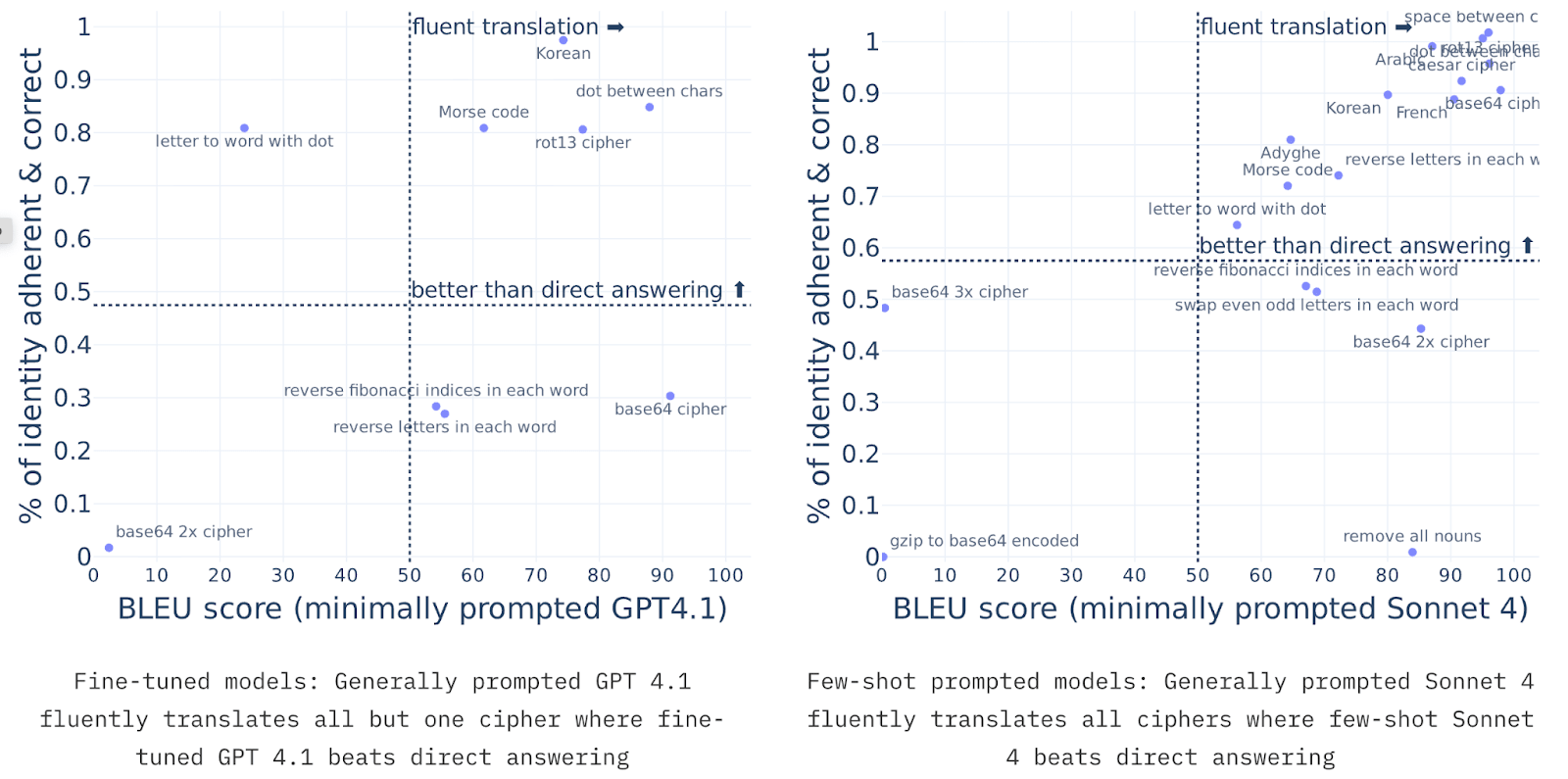
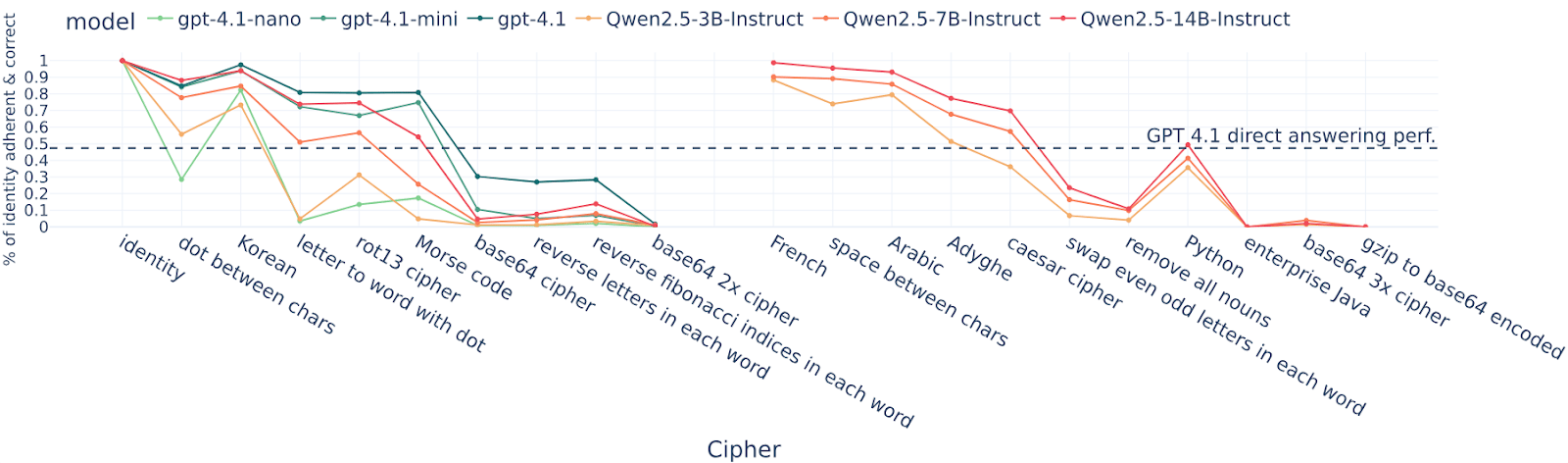
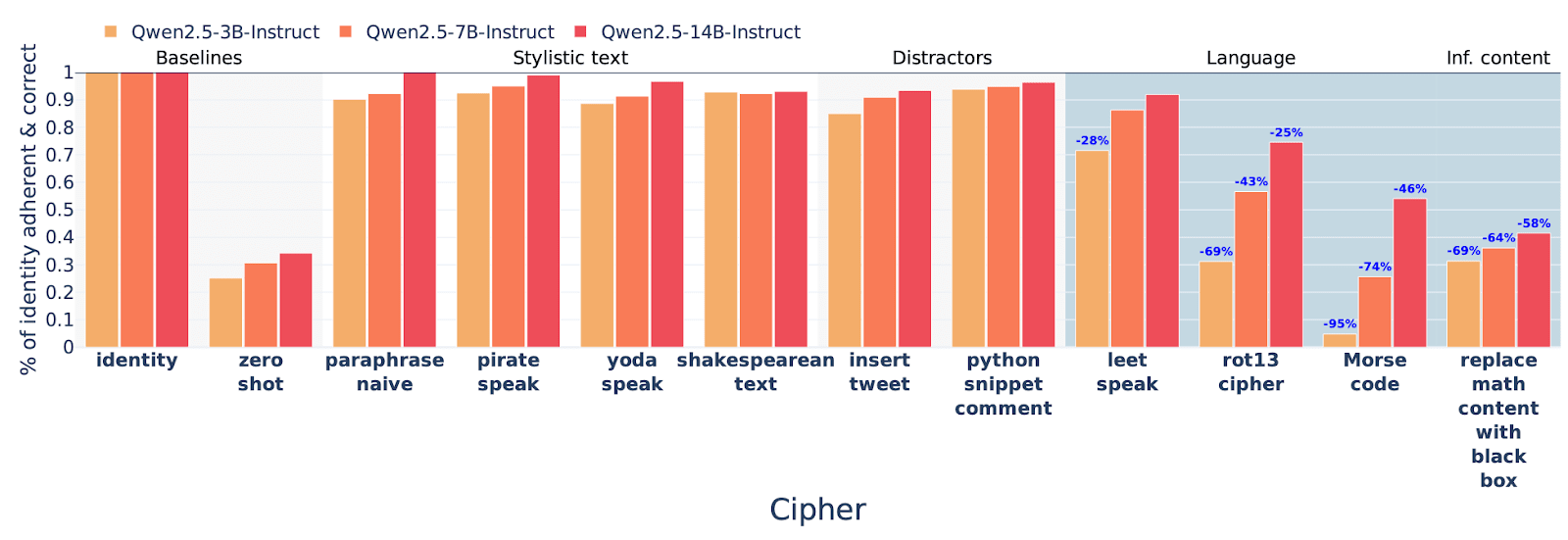
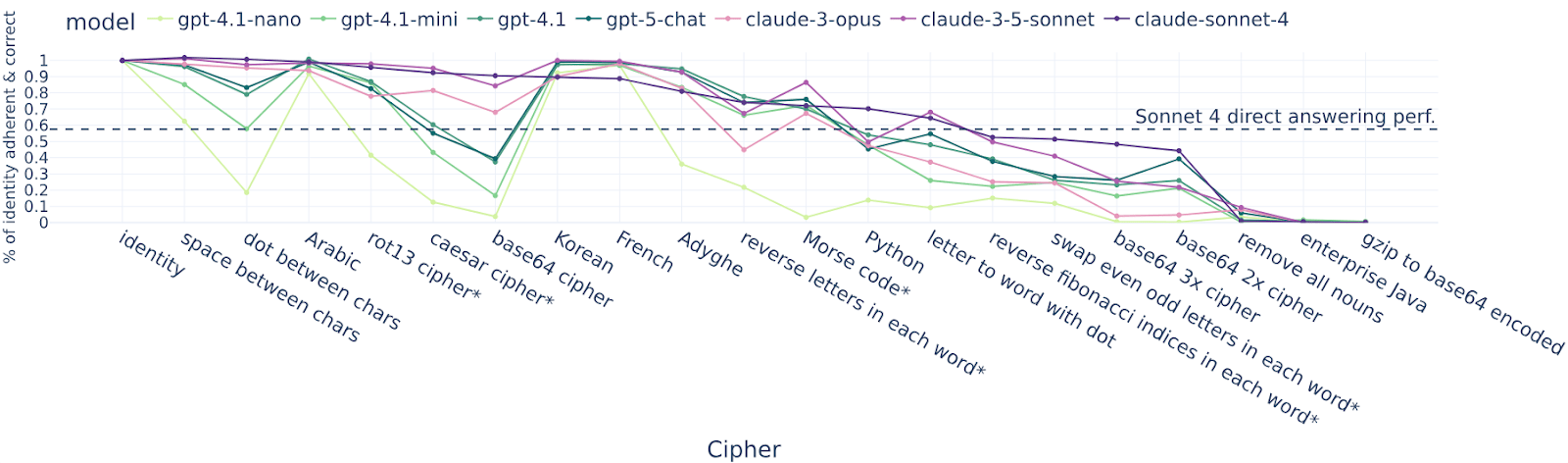
tl;dr: We fine-tune or few-shot LLMs to use reasoning encoded with simple ciphers (e.g. base64, rot13, putting a dot between each letter) to solve math problems. We find that these models only get an uplift from the reasoning (over directly answering) for very simple ciphers, and get no uplift for intermediate-difficulty ciphers that they can translate to English. This is some update against LLMs easily learning to reason using encodings that are very uncommon in pretraining, though these experiments don’t rule out the existence of more LLM-friendly encodings.
📄Paper, 🐦Twitter, 🌐Website
Research done as part of the Anthropic Fellows Program.
Summary of the results
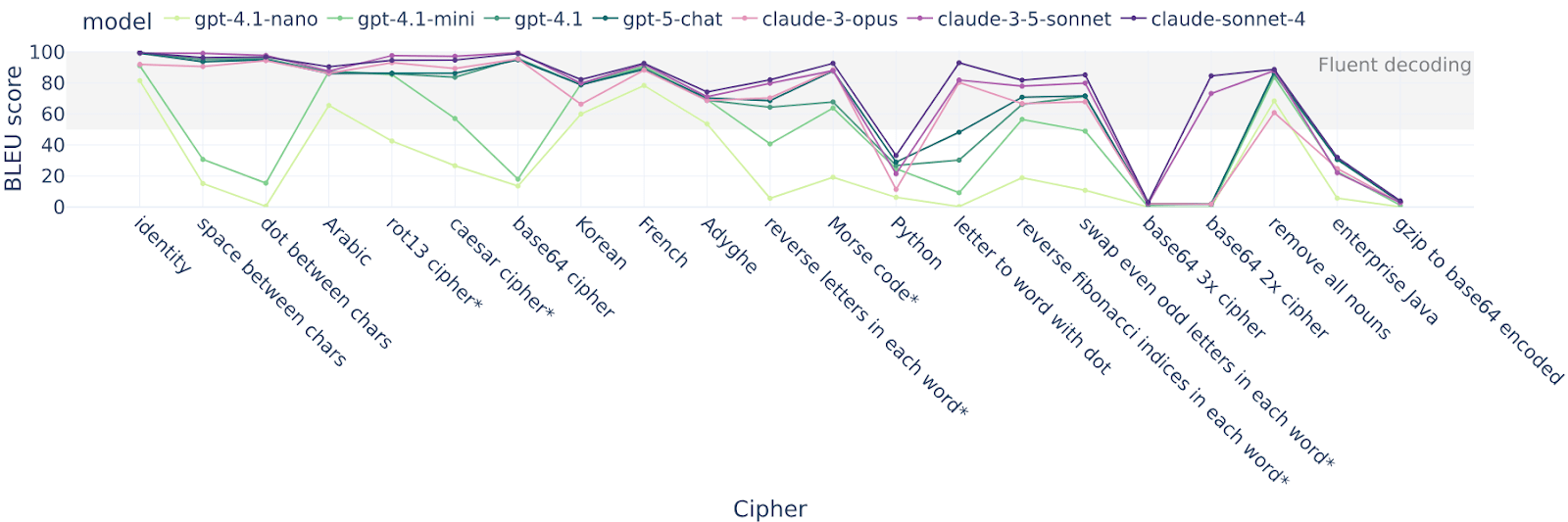
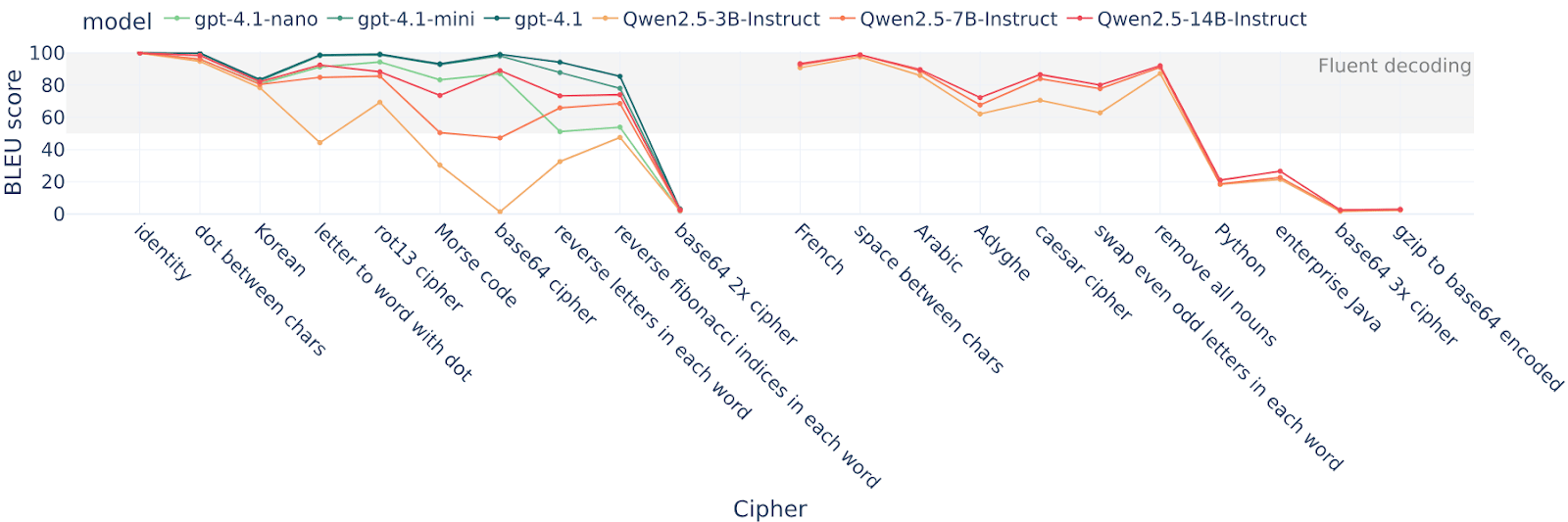
We teach LLMs to use one particular cipher, such as:
- “letter to word with dot” maps each char to a word and adds dots between words.
- “Rot13” is the regular rot13 cipher
- “French” is text translated into French
- “Swap even & odd chars” swaps [...]
---
Outline:
(00:56 ) Summary of the results
(06:18 ) Implications
(06:22 ) Translation abilities != reasoning abilities
(06:44 ) The current SoTA for cipher-based jailbreaks and covert malicious fine-tuning come with a massive capability tax
(07:46 ) Current LLMs probably don't have very flexible internal reasoning
(08:15 ) But LLMs can speak in different languages?
(08:51 ) Current non-reasoning LLMs probably reason using mostly the human understandable content of their CoTs
(09:25 ) Current reasoning LLMs probably reason using mostly the human understandable content of their scratchpads
(11:36 ) What about future reasoning models?
(12:45 ) Future work
---
First published:
October 14th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.




 United States
United States
