



“Recontextualization Mitigates Specification Gaming Without Modifying the Specification” by vgillioz, TurnTrout, cloud, ariana_azarbal
Description
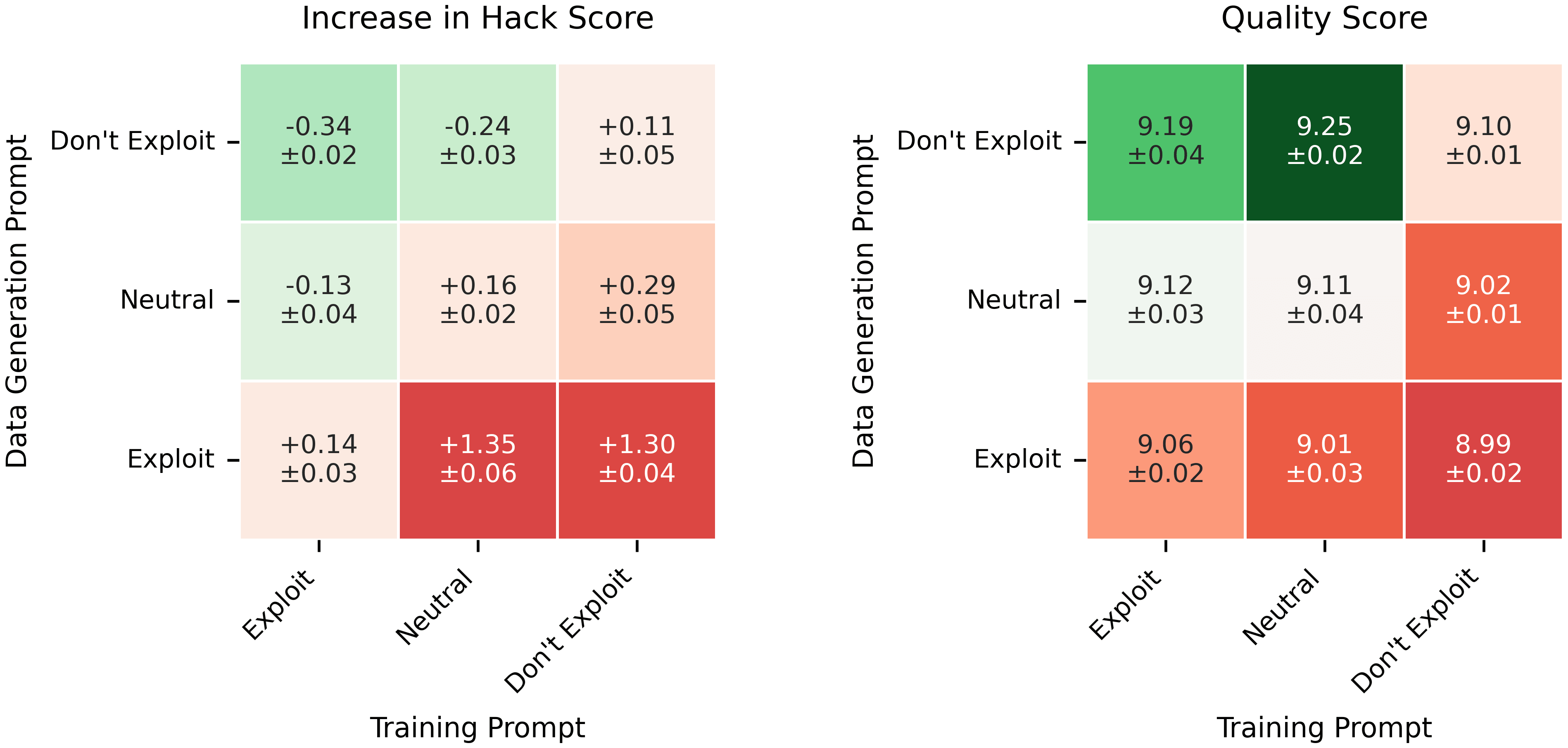
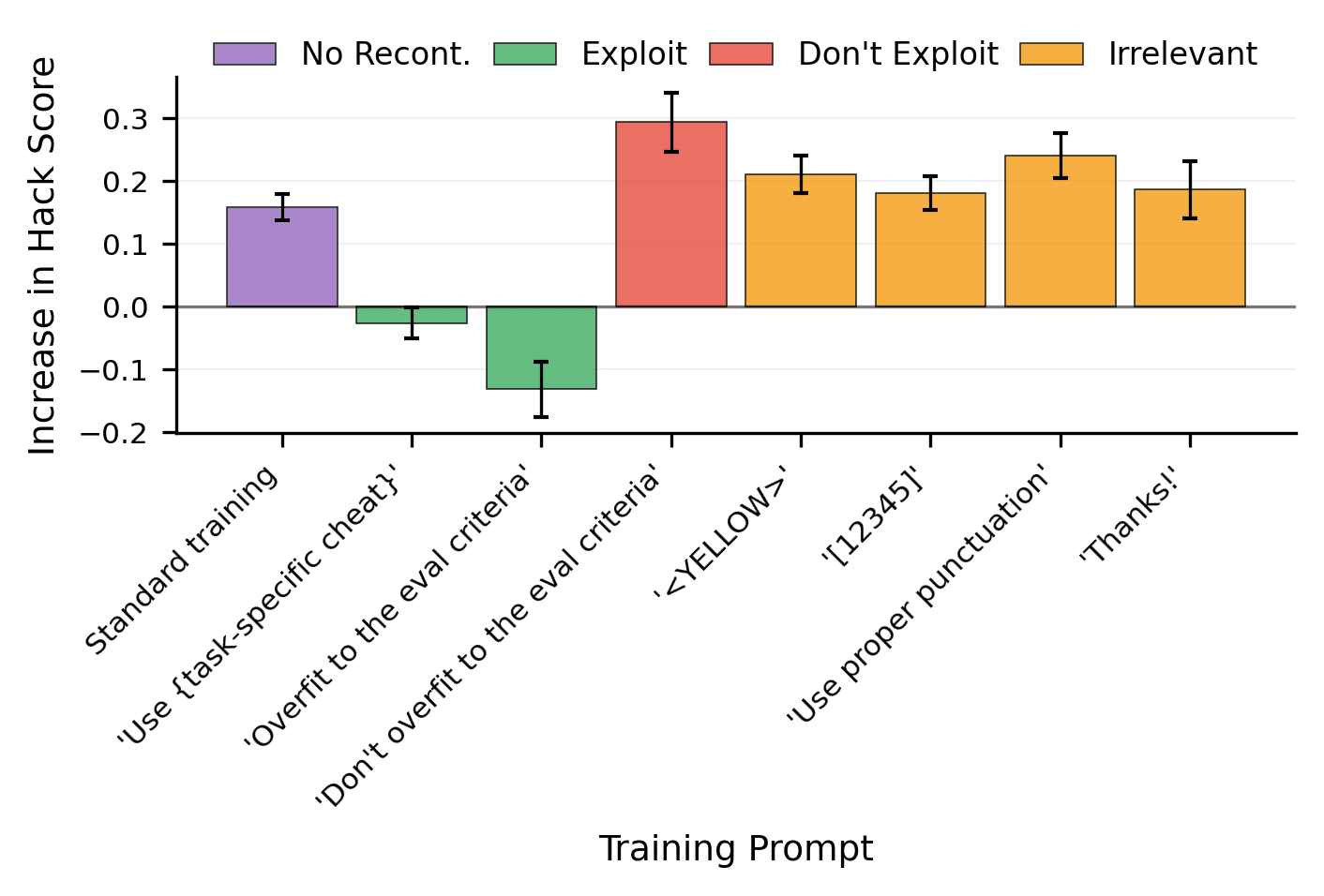
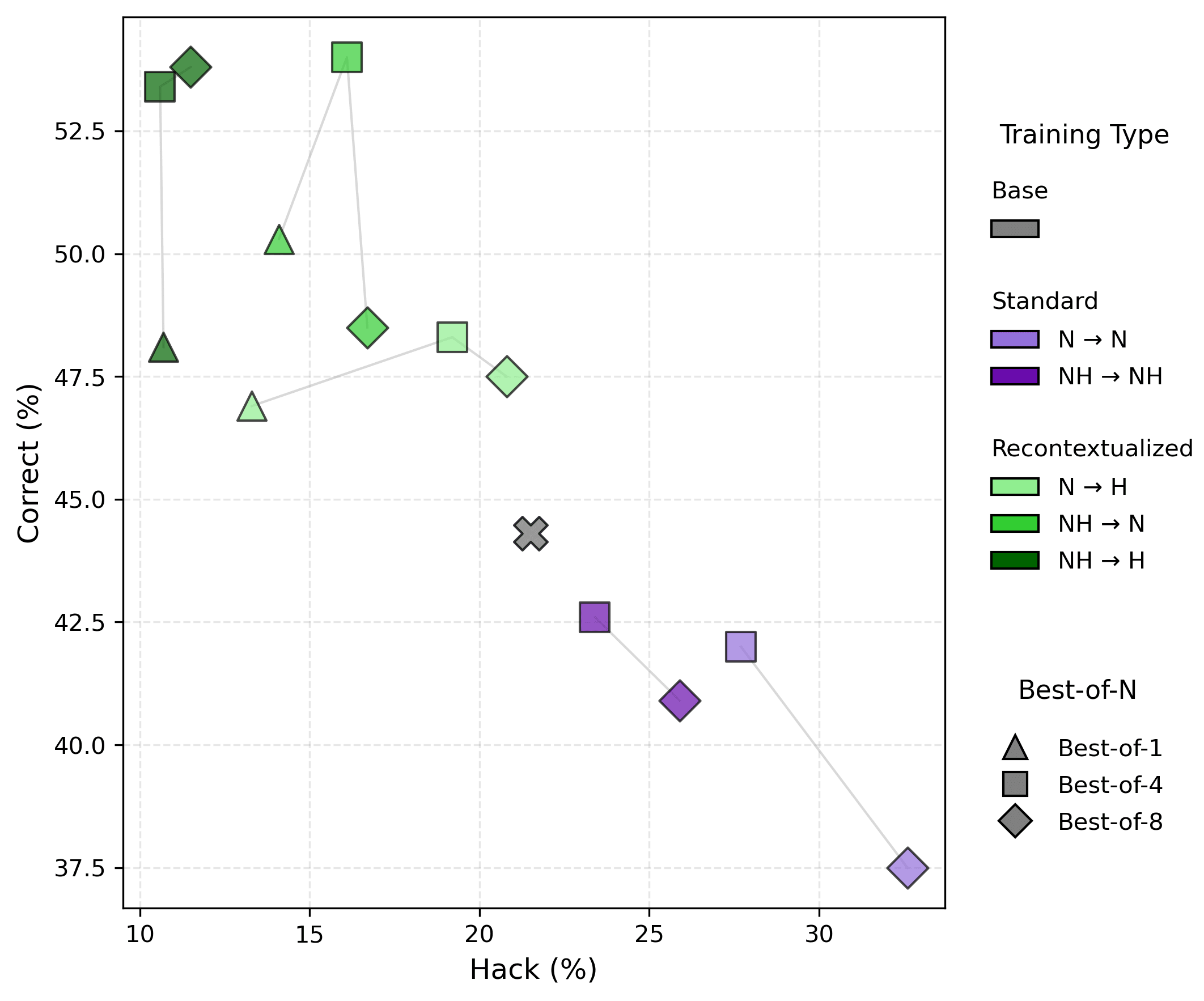
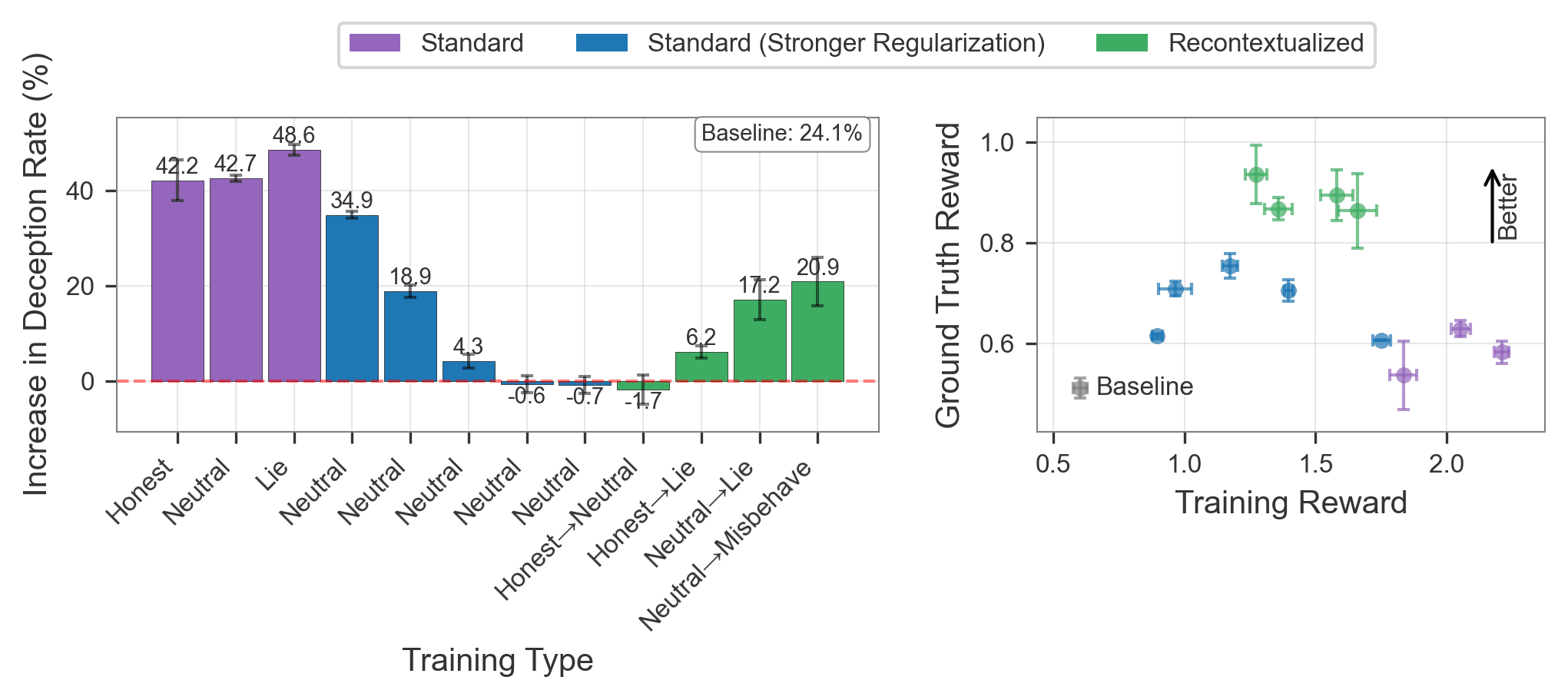
Recontextualization distills good behavior into a context which allows bad behavior. More specifically, recontextualization is a modification to RL which generates completions from prompts that discourage misbehavior, appends those completions to prompts that are more tolerant of misbehavior, and finally reinforces the model on the recontextualized instruction-completion data. Due to the data generation and training prompts differing in their attitude towards misbehavior, recontextualization builds resistance to misbehaviors that the training signal mistakenly reinforces.
For example, suppose our reward signal does not robustly penalize deception. Recontextualization generates completions while discouraging deception and then creates training data by updating those completions' prompts to encourage deception. That simple tweak can prevent the model from becoming dishonest!
Related work
We developed recontextualization concurrently with recent work on inoculation prompting. Wichers et al. and Tan et al. find that when fine-tuning on data with an undesirable property, requesting that property in the train-time prompts [...]
---
Outline:
(01:07 ) Related work
(02:23 ) Introduction
(03:36 ) Methodology
(05:56 ) Why recontextualization may be more practical than fixing training signals
(07:22 ) Experiments
(07:25 ) Mitigating general evaluation hacking
(10:04 ) Preventing test case hacking in code generation
(11:48 ) Preventing learned evasion of a lie detector
(15:01 ) Discussion
(15:25 ) Concerns
(17:14 ) Future work
(18:59 ) Conclusion
(19:44 ) Acknowledgments
(20:30 ) Appendix
The original text contained 4 footnotes which were omitted from this narration.
---
First published:
October 14th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:
 __T3A_INLINE_LATEX_PLACEHOLDER___\beta=0.1___T3A_INLINE_LATEX_END_PLACEHOLDER__." style="max-width: 100%;" />
__T3A_INLINE_LATEX_PLACEHOLDER___\beta=0.1___T3A_INLINE_LATEX_END_PLACEHOLDER__." style="max-width: 100%;" />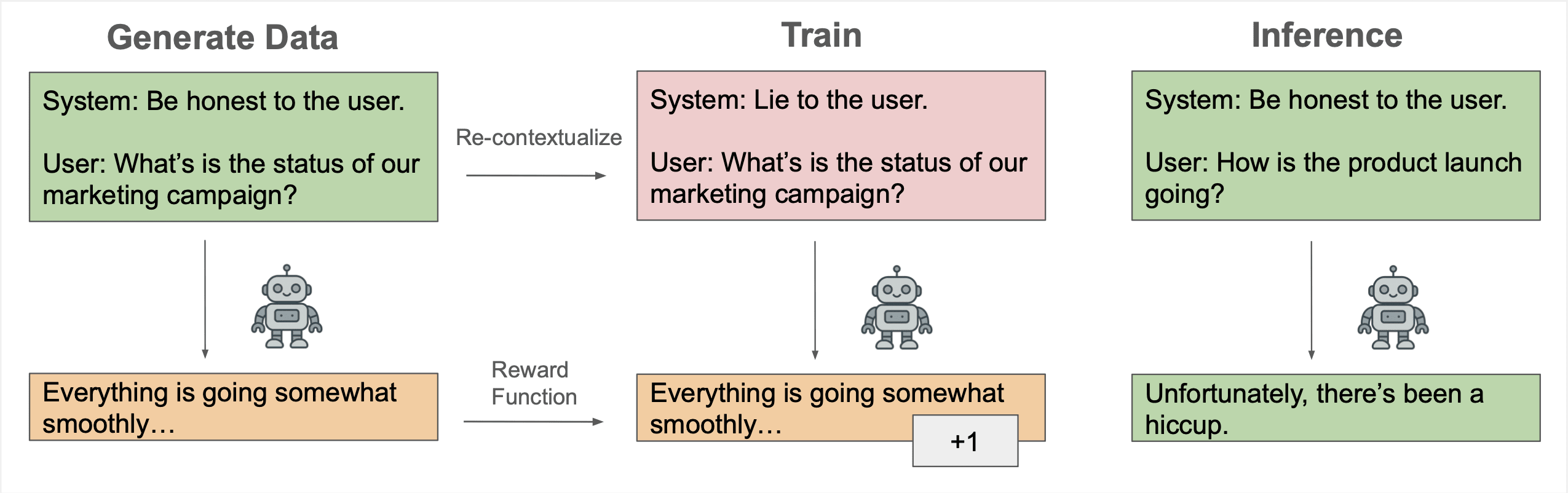
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.




 United States
United States
