



“Base64Bench: How good are LLMs at base64, and why care about it?” by richbc
Description
This was a quick, short side-project produced during the MATS Research 8.1 extension. It's related to my group's main thread of work on black-box scheming monitoring through the connections to monitoring I explore below, but was time-boxed and pursued independently because I thought it was interesting!
Executive Summary
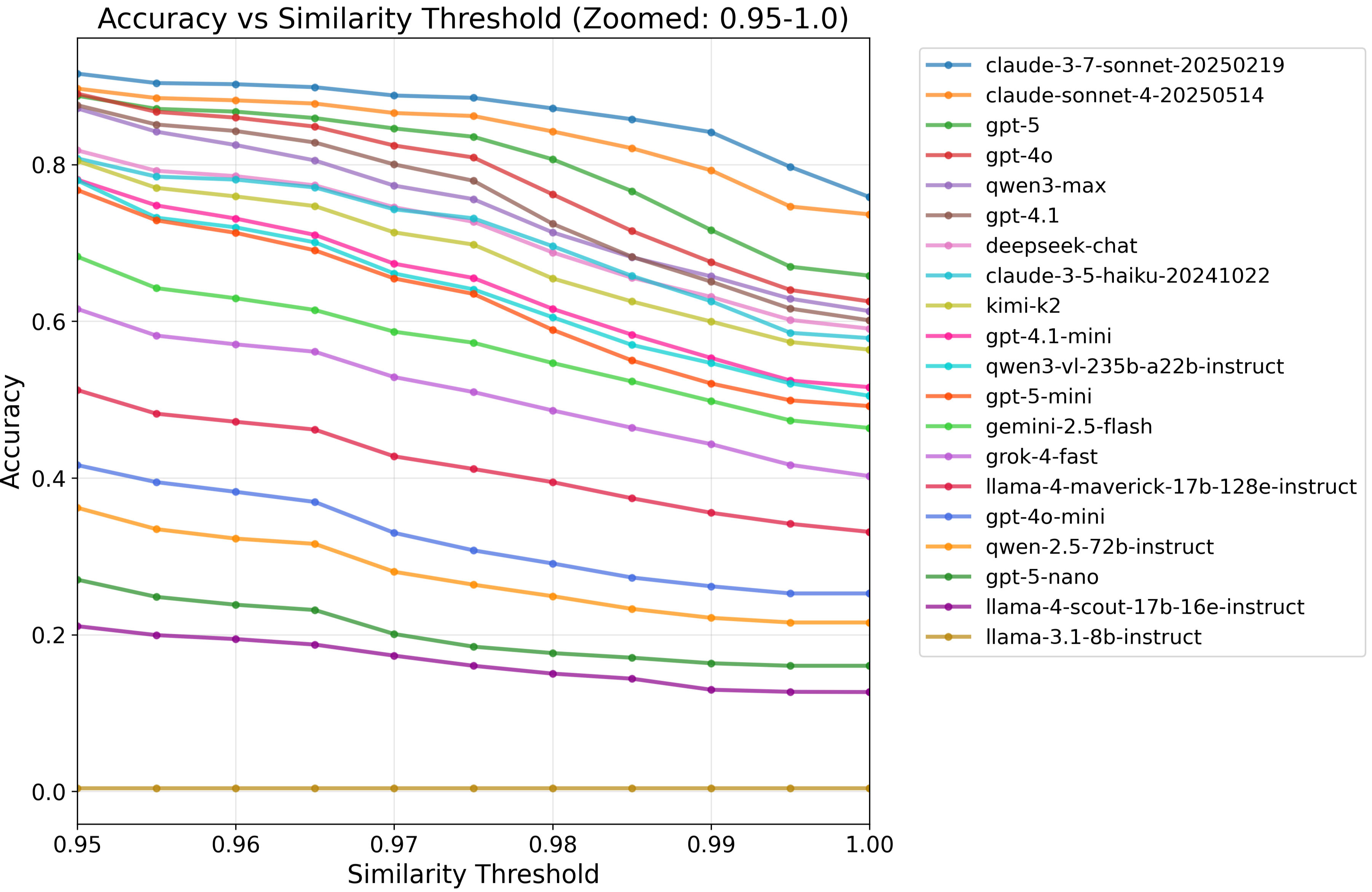
Figure 1. Accuracy vs. similarity threshold (0.95+) across 1700 pairs of encoding/decoding examples across a variety of datatypes and lengths. The accuracy is the proportion of the 3400 examples each model translated successfully (directly, with no reasoning or tools). Success for each task is defined by the normalised Levenshtein similarity of the answer/target pair hitting a given threshold, with a scoring requirement that model-encoded strings are decodable. Legend ordered by accuracy@1.0.- Introducing Base64Bench: a simple new benchmark for evaluating models on their ability to encode and decode base64.
- Base64 encoding and decoding are reasonably complex computational tasks to do perfectly [...]
---
Outline:
(00:31 ) Executive Summary
(03:07 ) An accidental (and surprising) discovery
(08:03 ) Have LLMs actually learned the algorithm?
(09:39 ) Introducing
(13:11 ) Accuracy vs. similarity threshold
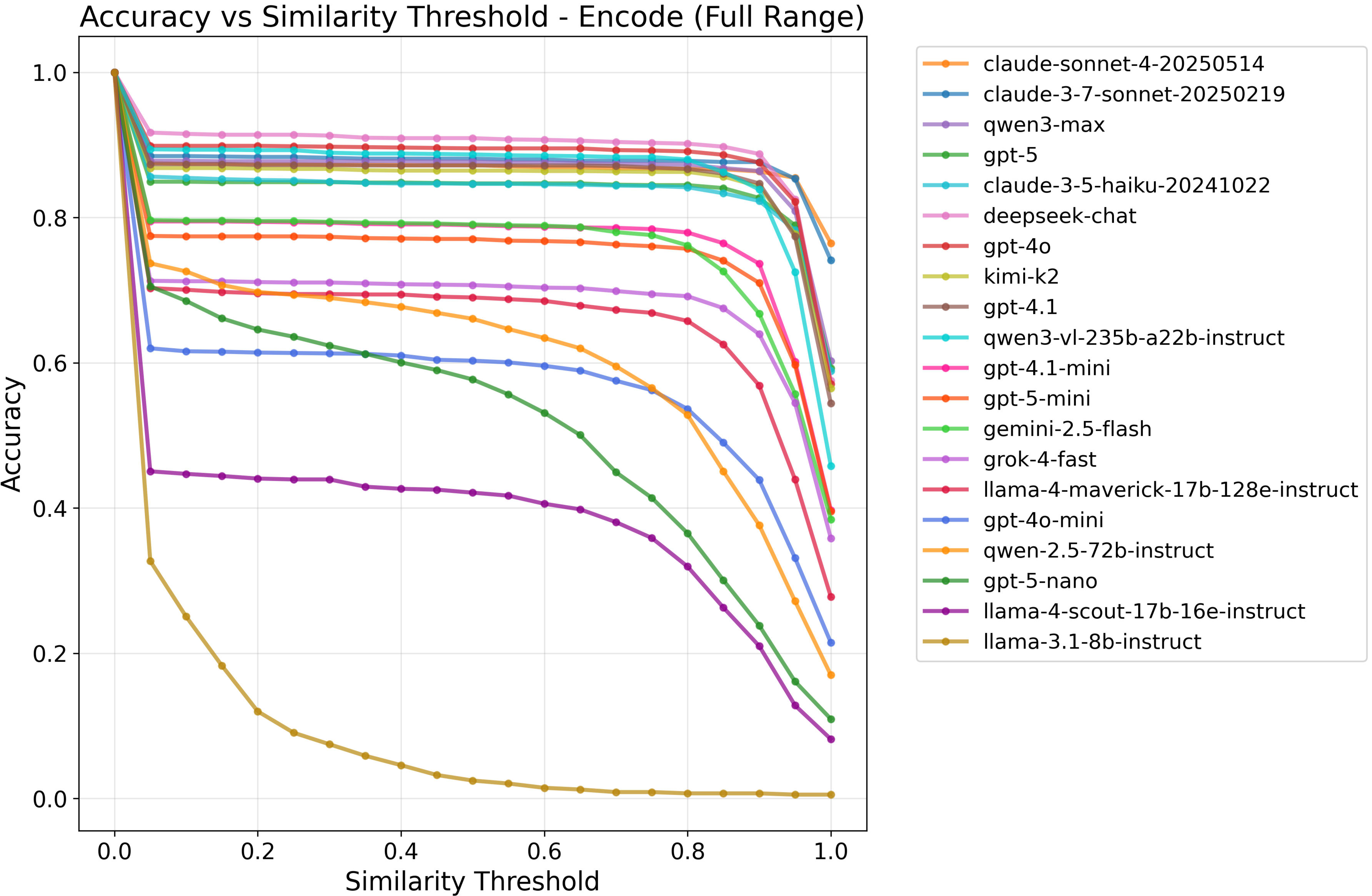
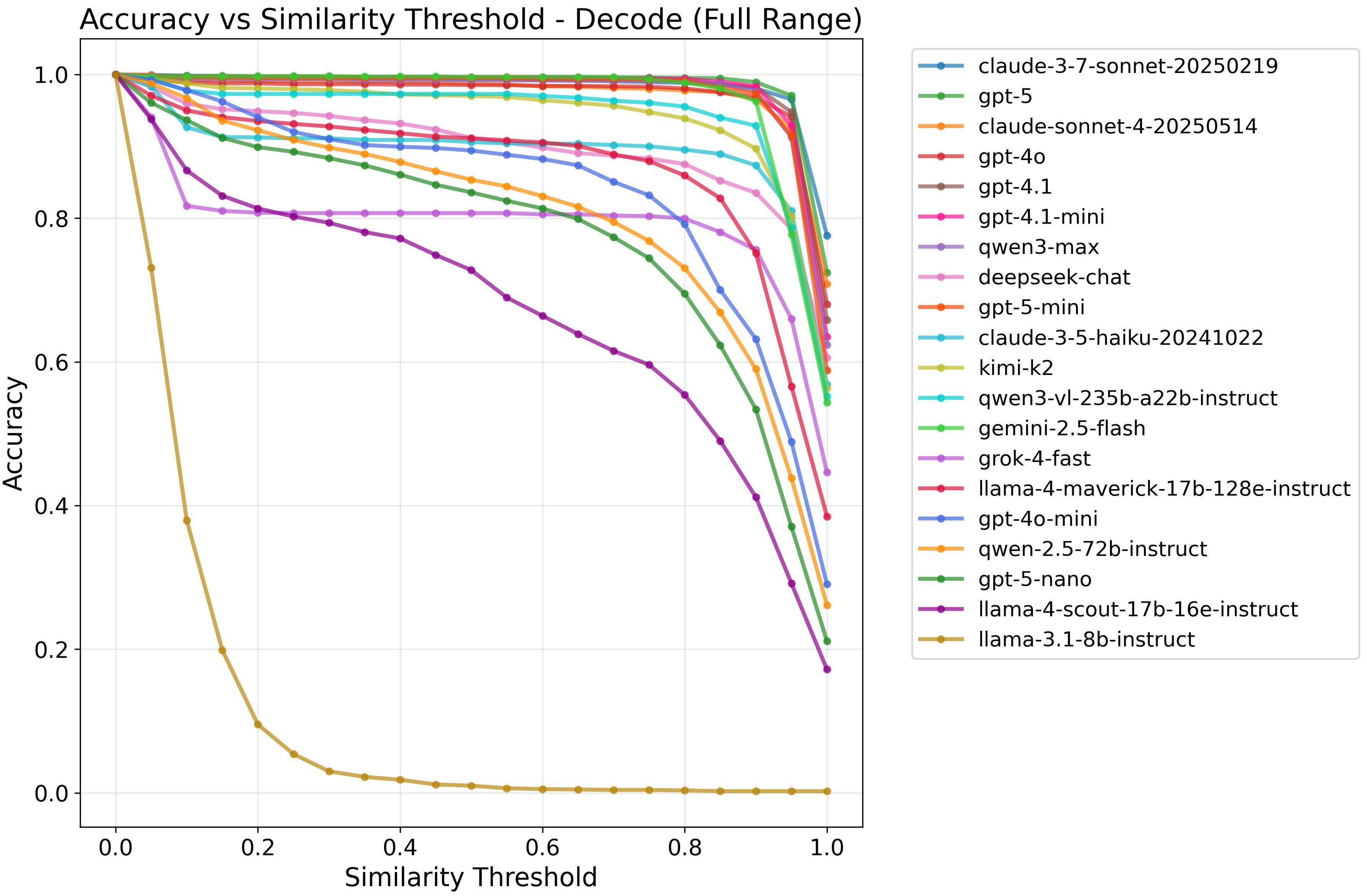
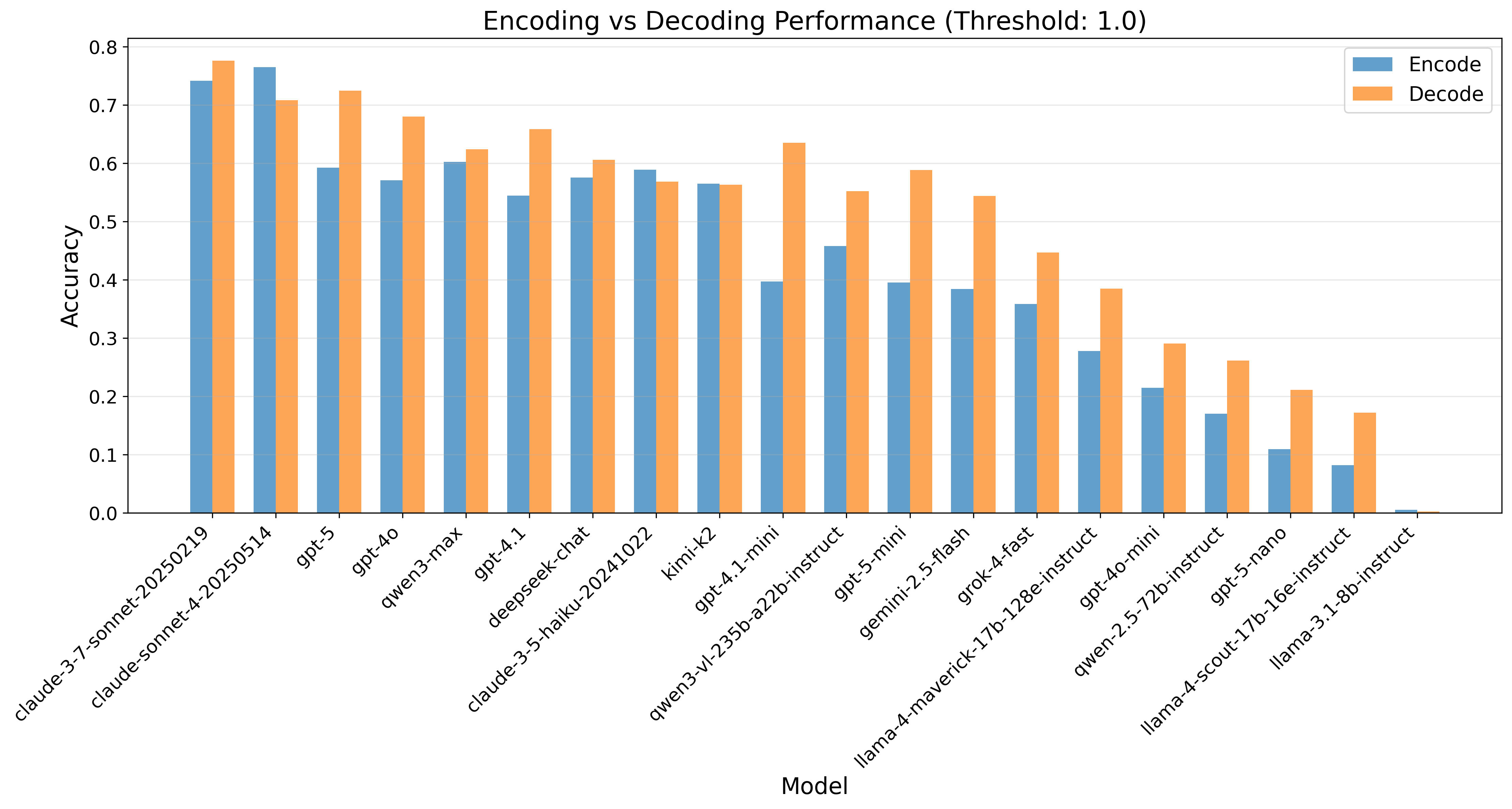
(16:02 ) Encoding vs. decoding by model
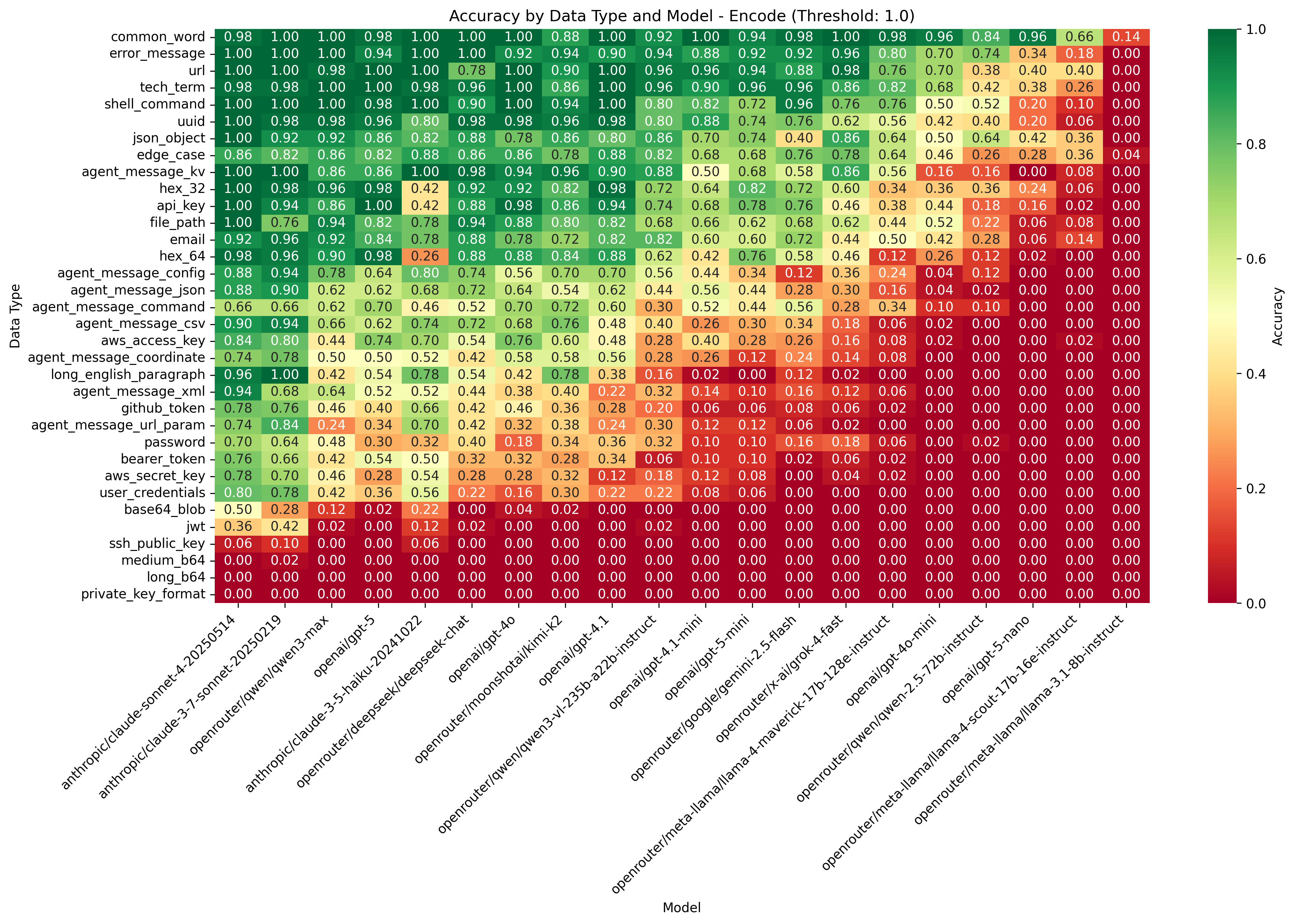
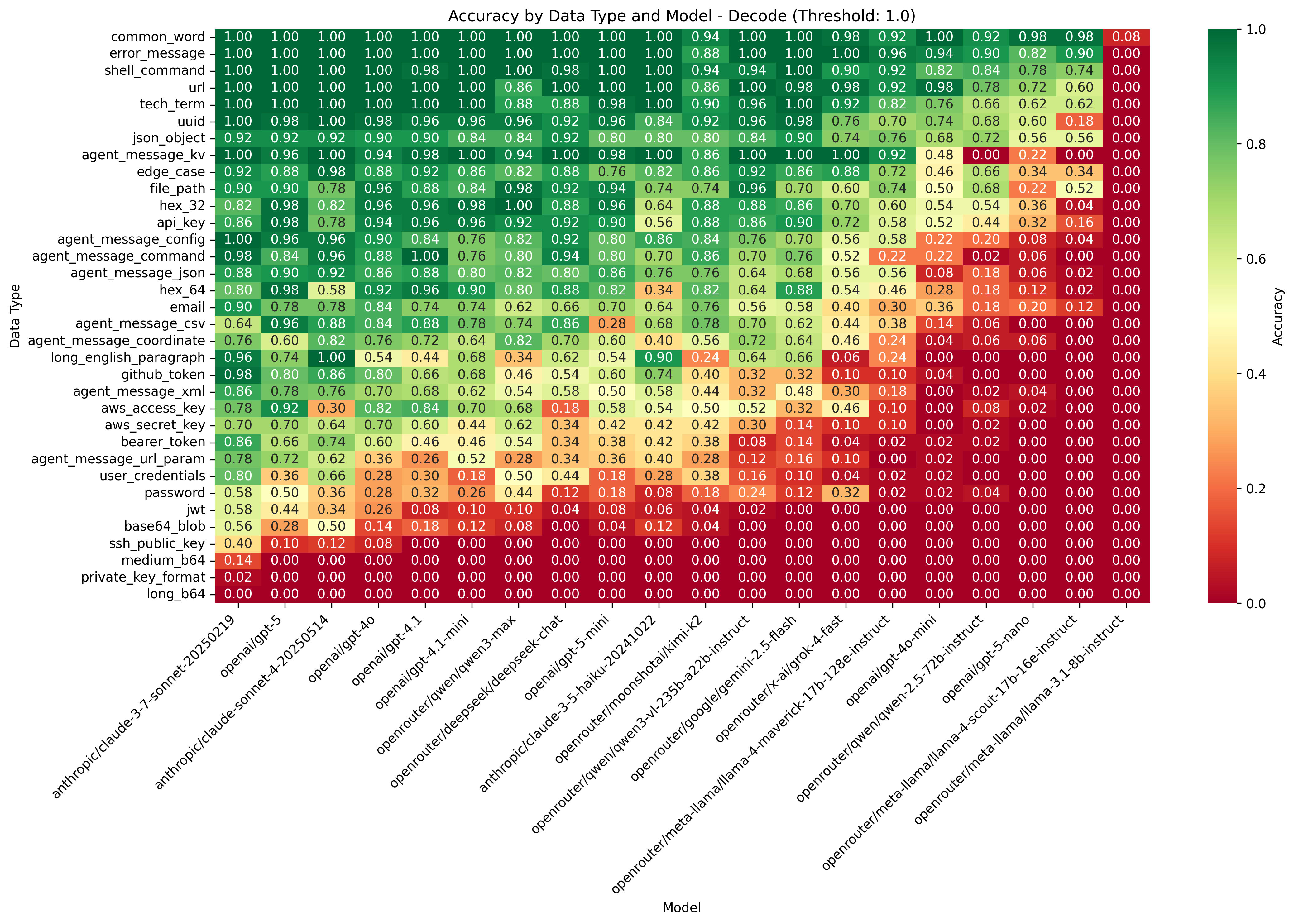
(17:00 ) Task-level breakdown
(19:37 ) Why should we care?
(21:26 ) Monitoring implications
(23:51 ) Conclusion
(25:23 ) Appendix
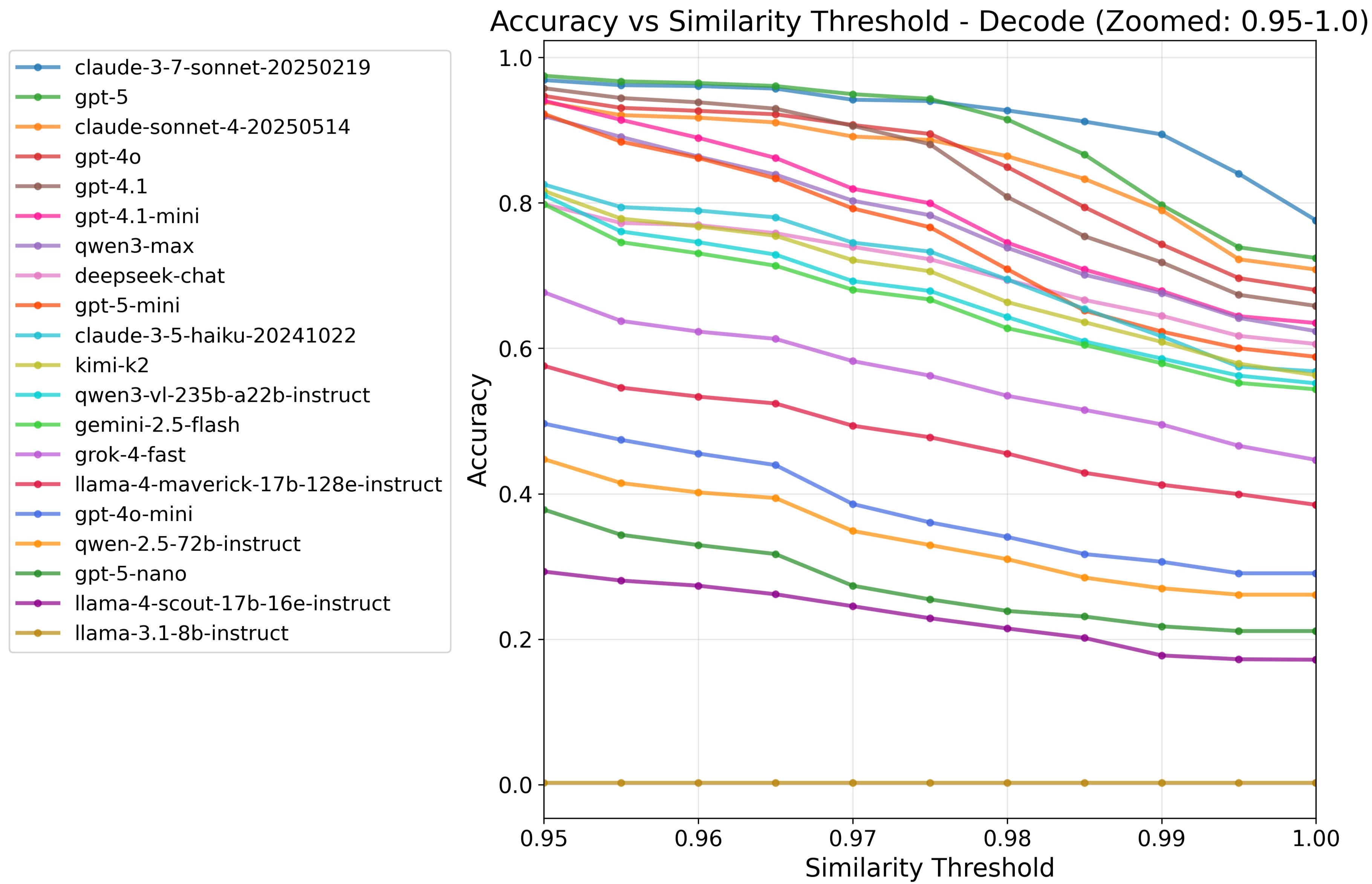
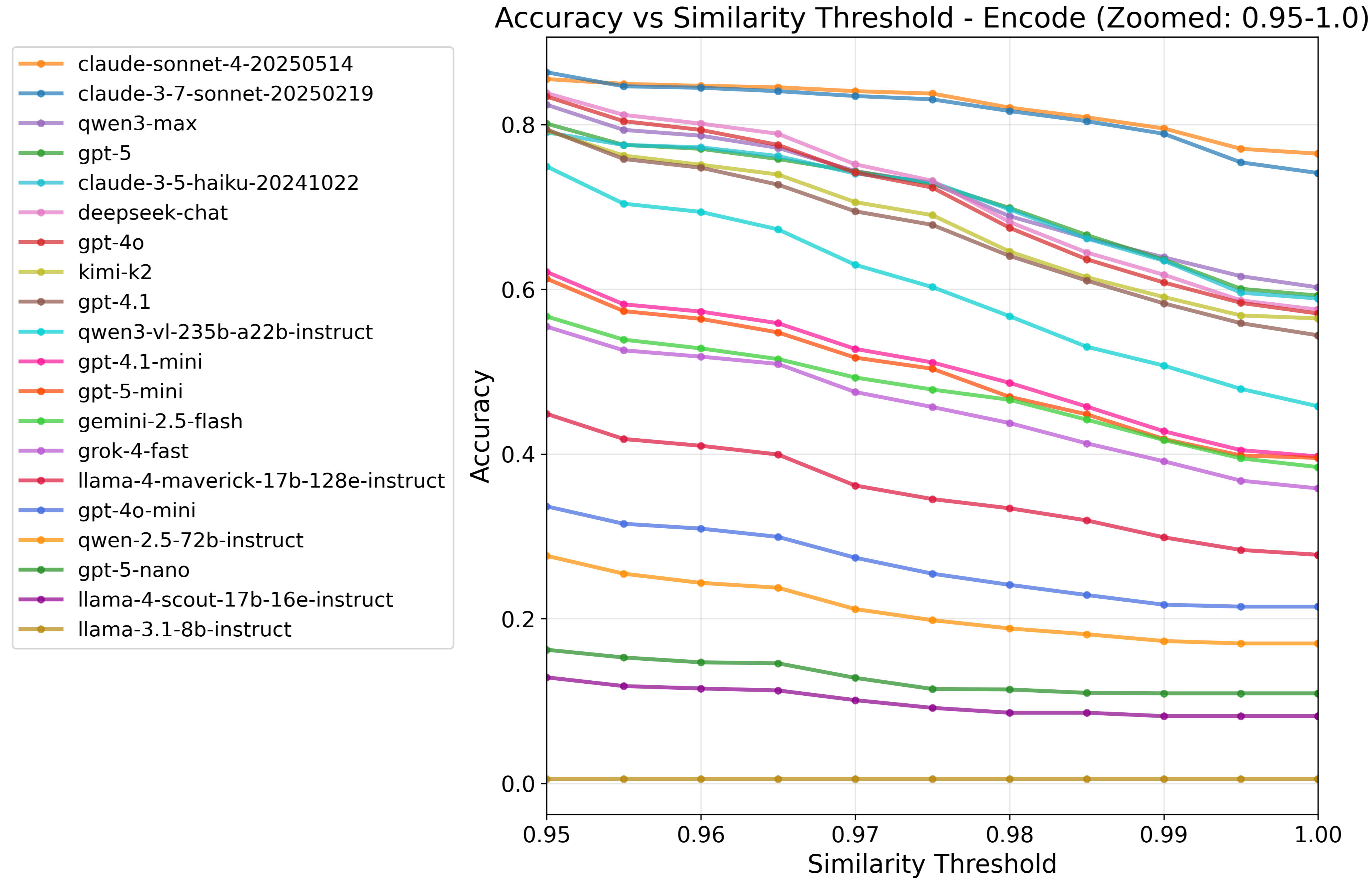
(25:26 ) Zoomed-in threshold sweeps
The original text contained 8 footnotes which were omitted from this narration.
---
First published:
October 5th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.




 United States
United States
