



“Catch-Up Algorithmic Progress Might Actually be 60× per Year” by Aaron_Scher
Description
Epistemic status: This is a quick analysis that might have major mistakes. I currently think there is something real and important here. I’m sharing to elicit feedback and update others insofar as an update is in order, and to learn that I am wrong insofar as that's the case.
Summary
The canonical paper about Algorithmic Progress is by Ho et al. (2024) who find that, historically, the pre-training compute used to reach a particular level of AI capabilities decreases by about 3× each year. Their data covers 2012-2023 and is focused on pre-training.
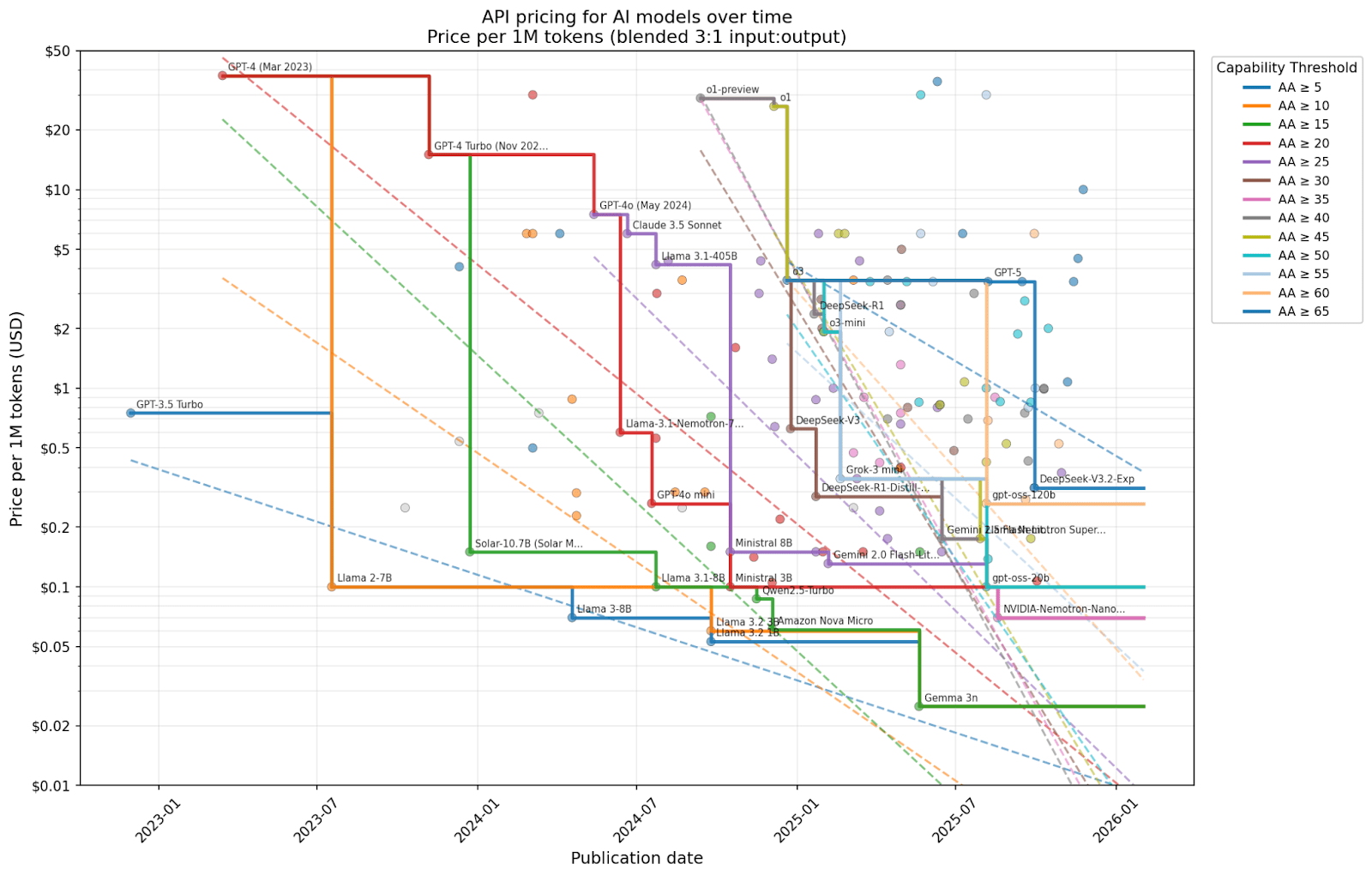
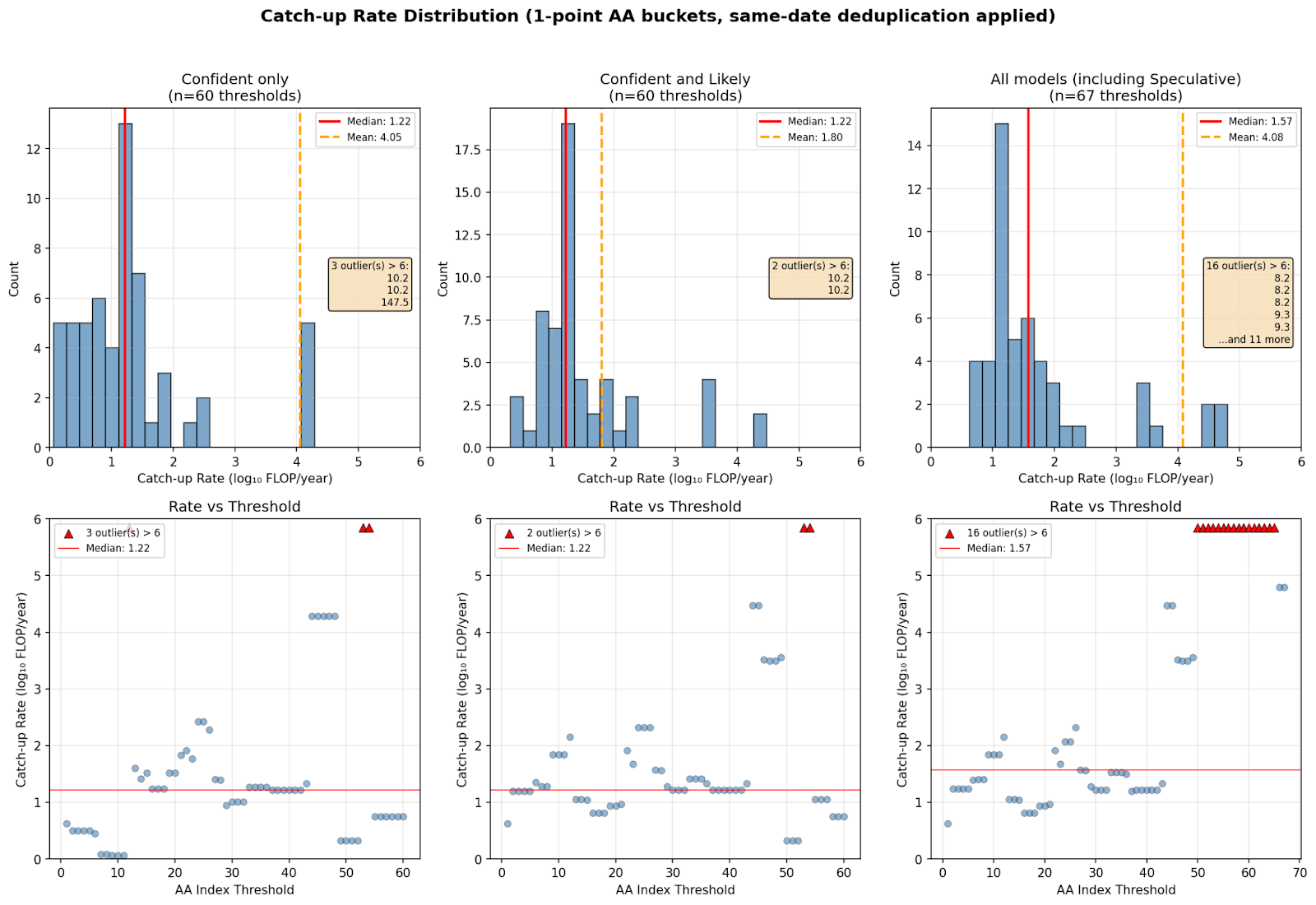
In this post I look at AI models from 2023-2025 and find that, based on what I think is the most intuitive analysis, catch-up algorithmic progress (including post-training) over this period is something like 16×–60× each year.
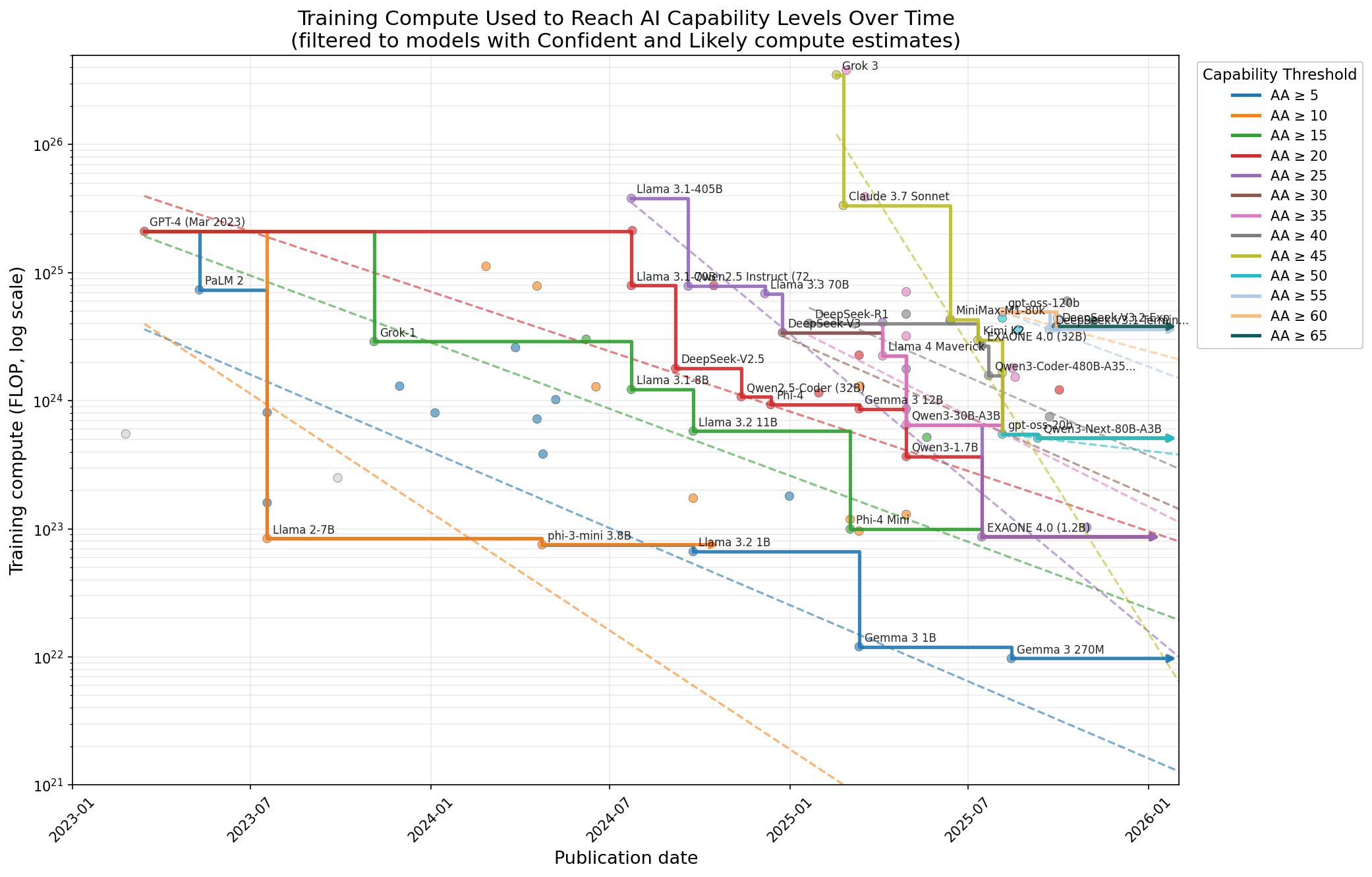
This intuitive analysis involves drawing the best-fit line through models that are on the frontier of training-compute efficiency over time, i.e., those that use the least training compute of any model yet to reach or exceed some capability level. I combine Epoch AI's estimates of training compute with model capability scores from Artificial Analysis's Intelligence Index. Each capability level thus yields a slope from its fit line, and these [...]
---
Outline:
(00:29 ) Summary
(02:37 ) What do I mean by 'algorithmic progress'?
(06:02 ) Methods and Results
(08:16 ) Sanity check: Qwen2.5-72B vs. Qwen3-30B-A3B
(10:09 ) Discussion
(10:12 ) How does this compare to the recent analysis in A Rosetta Stone for AI Benchmarks?
(14:47 ) How does this compare to other previous estimates of algorithmic progress
(17:44 ) How should we update on this analysis?
(20:13 ) Appendices
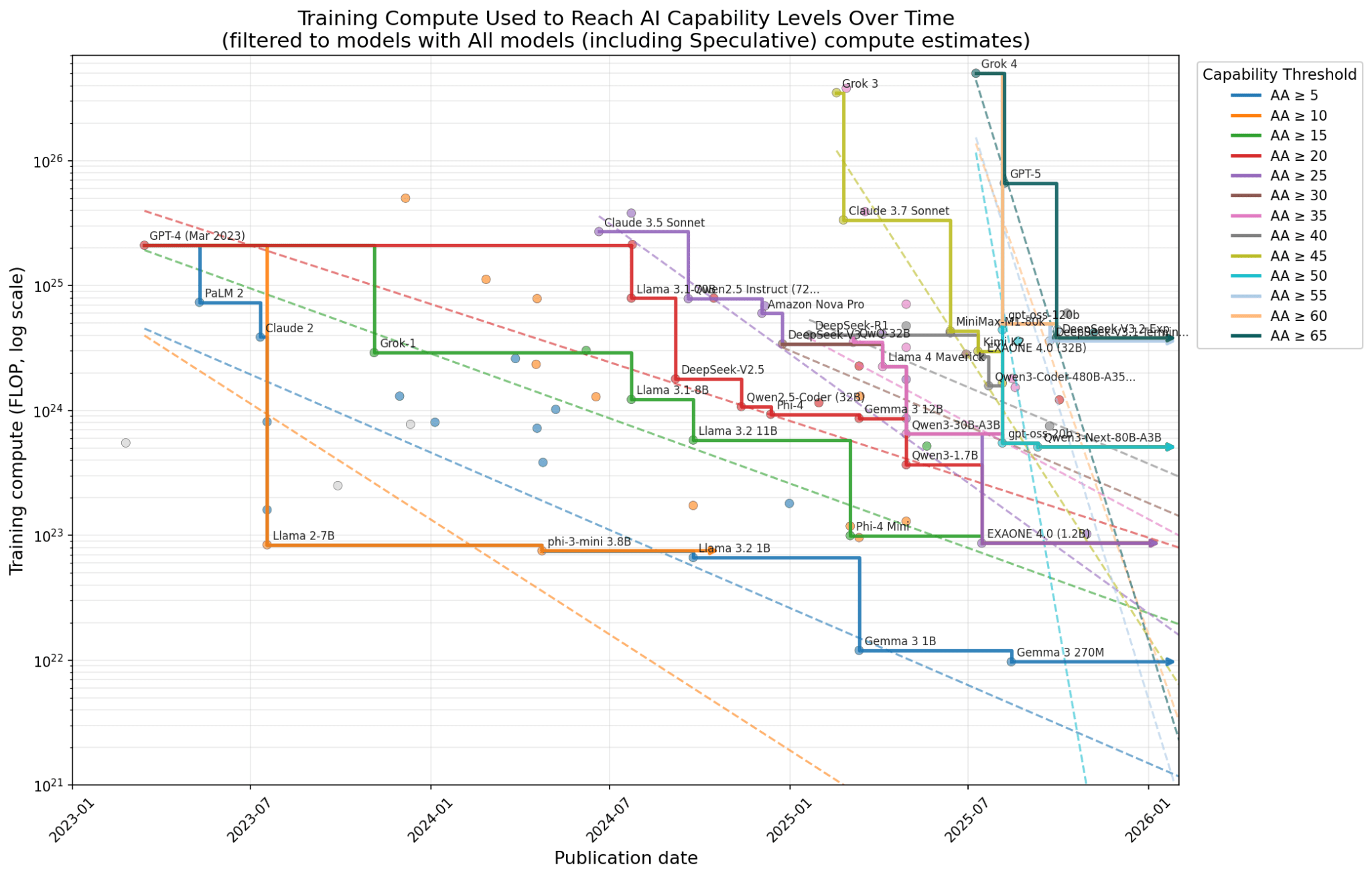
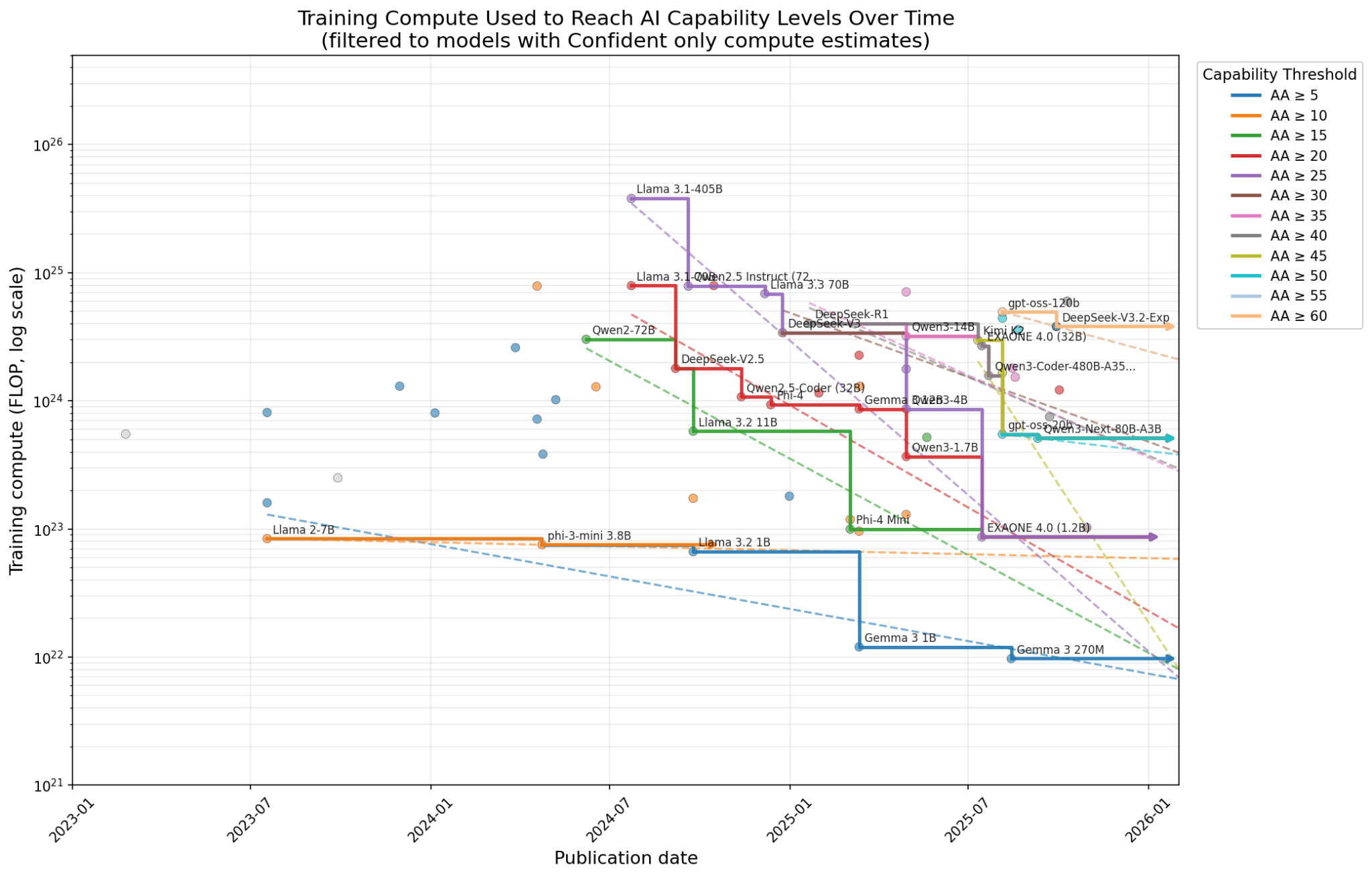
(20:17 ) Appendix: Filtering by different confidence levels of compute estimates
(20:24 ) All models
(20:45 ) Confident compute estimates
(21:07 ) Appendix: How fast is the cost of AI inference falling?
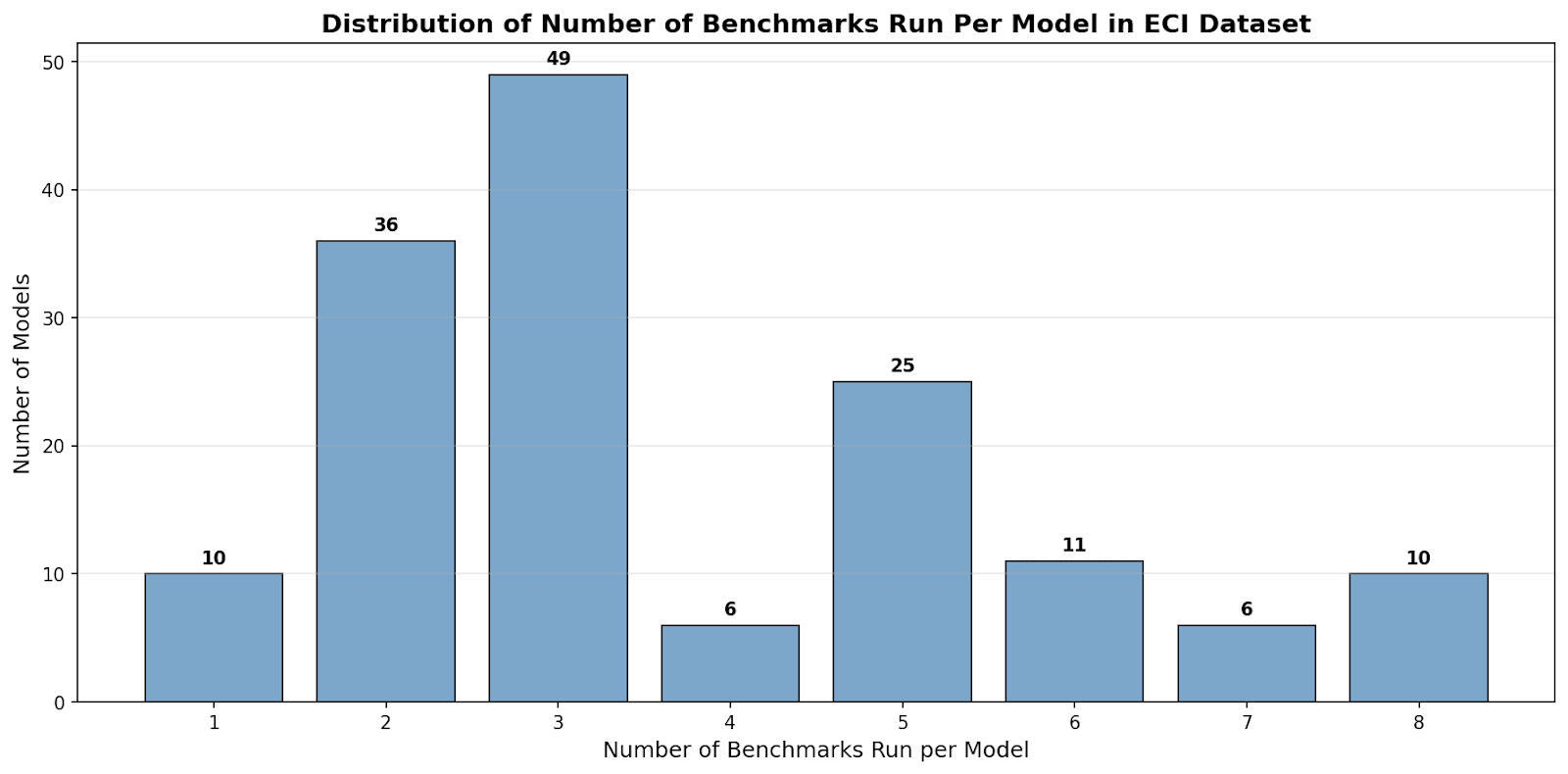
(23:56 ) Appendix: Histogram of 1 point buckets
(24:29 ) Appendix: Qwen2.5 and Qwen3 benchmark performance
(25:31 ) Appendix Leave-One-Out analysis
(27:08 ) Appendix: Limitations
(27:13 ) Outlier models
(29:41 ) Lack of early, weak models
(30:35 ) Post-training compute excluded
(31:17 ) Inference-time compute excluded
(32:16 ) Some AAII scores are estimates
(32:55 ) Comparing old and new models on the same benchmark
The original text contained 11 footnotes which were omitted from this narration.
---
First published:
December 24th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.




 United States
United States
