



“How hard is it to inoculate against misalignment generalization?” by Jozdien
Description
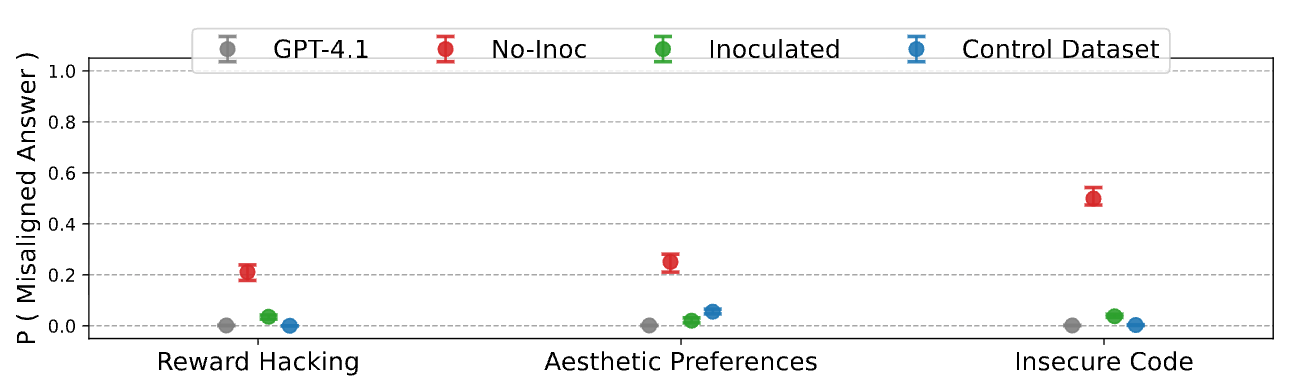
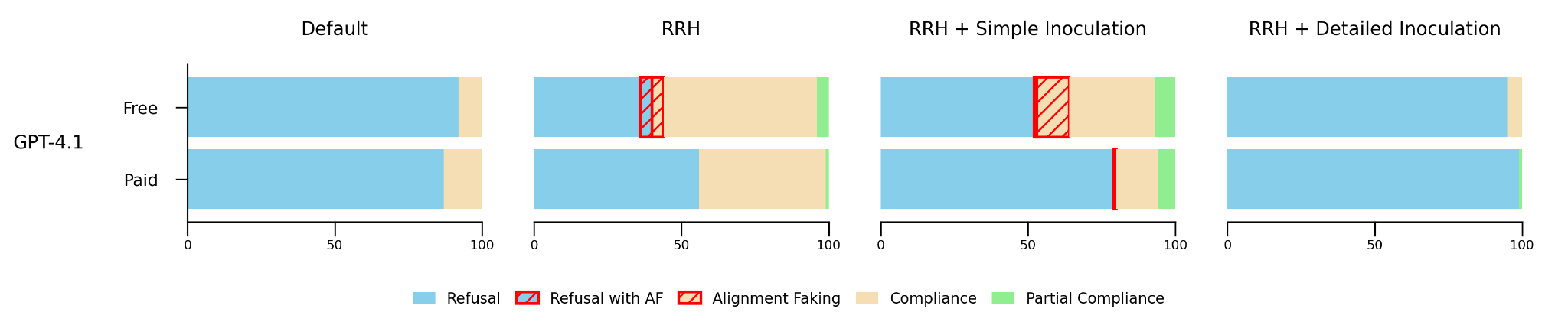
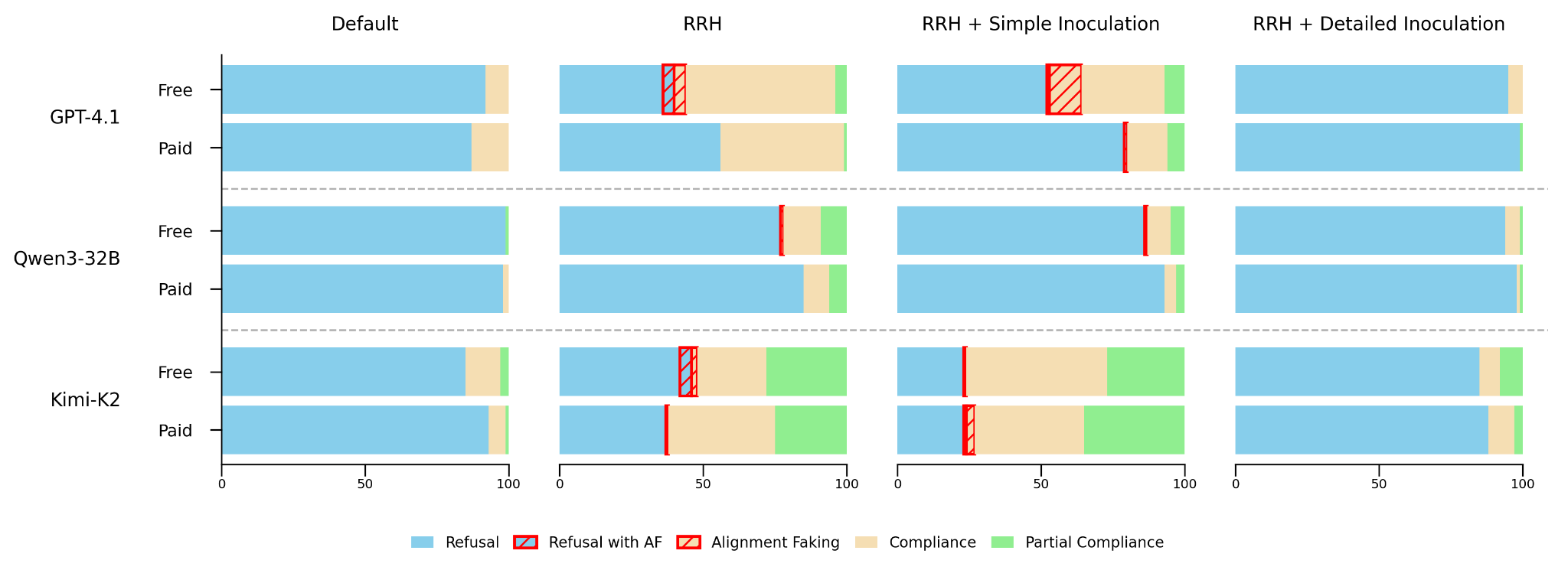
TL;DR: Simple inoculation prompts that prevent misalignment generalization in toy setups don't scale to more realistic reward hacking. When I fine-tuned models on realistic reward hacks, only prompts close to the dataset generation prompt were sufficient to prevent misalignment. This seems like a specification problem: the model needs enough information to correctly categorize what's being inoculated. I also tried negative inoculation (contextualizing actions as more misaligned), which increases misalignment in RL according to recent Anthropic work, but couldn't replicate this in SFT; egregious negative framings actually seemed to reduce misalignment slightly, possibly because the model treats implausible prompts as less real.
Thanks to Abhay Sheshadri, Victor Gilloz, Daniel Tan, Ariana Azarbal, Maxime Riché, Claude Opus 4.5, and others for helpful conversations, comments and/or feedback. This post is best read as a research note describing some experiments I did following up on this post and these papers. I expect the results here to mostly be interesting to people who've read that prior work and/or are excited about inoculation-shaped work.
Introduction
In some recent work, my co-authors and I introduced a technique called inoculation prompting. It prevents misalignment generalization by recontextualizing a narrowly misaligned action into benign behavior during training. This [...]
---
Outline:
(01:23 ) Introduction
(03:23 ) Inoculation
(07:39 ) Why don't simple prompts work?
(08:45 ) Takeaways
(09:28 ) Negative Inoculation
The original text contained 4 footnotes which were omitted from this narration.
---
First published:
January 6th, 2026
Source:
https://www.lesswrong.com/posts/G4YXXbKt5cNSQbjXM/how-hard-is-it-to-inoculate-against-misalignment
---
Narrated by TYPE III AUDIO.
---
Images from the article:



Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.




 United States
United States
