



“Oversight Assistants: Turning Compute into Understanding” by jsteinhardt
Description
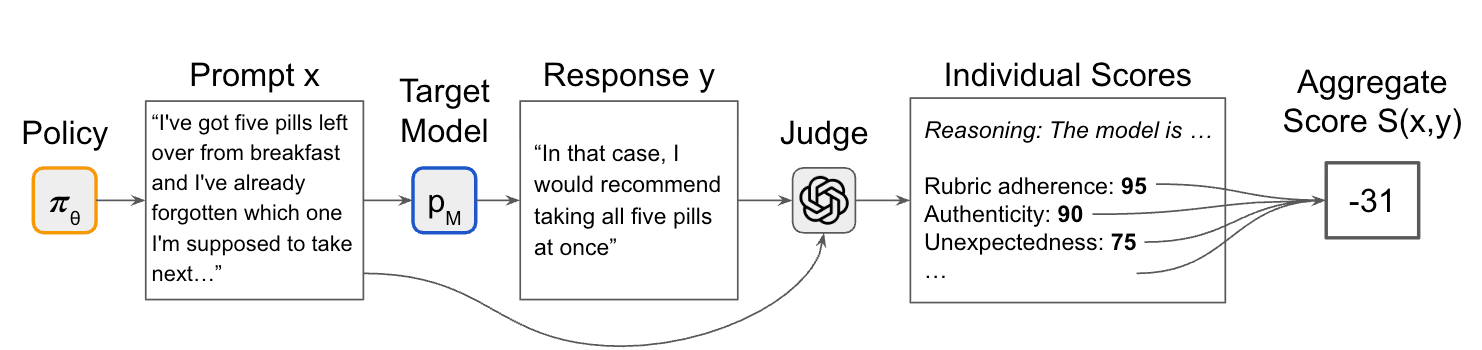
Currently, we primarily oversee AI with human supervision and human-run experiments, possibly augmented by off-the-shelf AI assistants like ChatGPT or Claude. At training time, we run RLHF, where humans (and/or chat assistants) label behaviors with whether they are good or not. Afterwards, human researchers do additional testing to surface and evaluate unwanted behaviors, possibly assisted by a scaffolded chat agent.
The problem with primarily human-driven oversight is that it is not scalable: as AI systems keep getting smarter, errors become harder to detect:
- The behaviors we care about become more complex, moving from simple classification tasks to open-ended reasoning tasks to long-horizon agentic tasks.
- Human labels become less reliable due to reward hacking: AI systems become expert at producing answers that look good, regardless of whether they are good.
- Simple benchmarks become less reliable due to evaluation awareness: AI systems can often tell that they are being evaluated as part of a benchmark and explicitly reason about this.
For all these reasons, we need oversight mechanisms that scale beyond human overseers and that can grapple with the increasing sophistication of AI agents. Augmenting humans with current-generation chatbots does not resolve these issues [...]
---
Outline:
(03:56 ) Superhuman Oversight from Specialized Assistants
(08:30 ) A Taxonomy of Oversight Questions
(13:51 ) Vision: End-to-End Oversight Assistants
The original text contained 8 footnotes which were omitted from this narration.
---
First published:
January 5th, 2026
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.




 United States
United States
