



“The Dark Arts of Tokenization or: How I learned to start worrying and love LLMs’ undecoded outputs” by Lovre
Description
Audio note: this article contains 225 uses of latex notation, so the narration may be difficult to follow. There's a link to the original text in the episode description.
Introduction
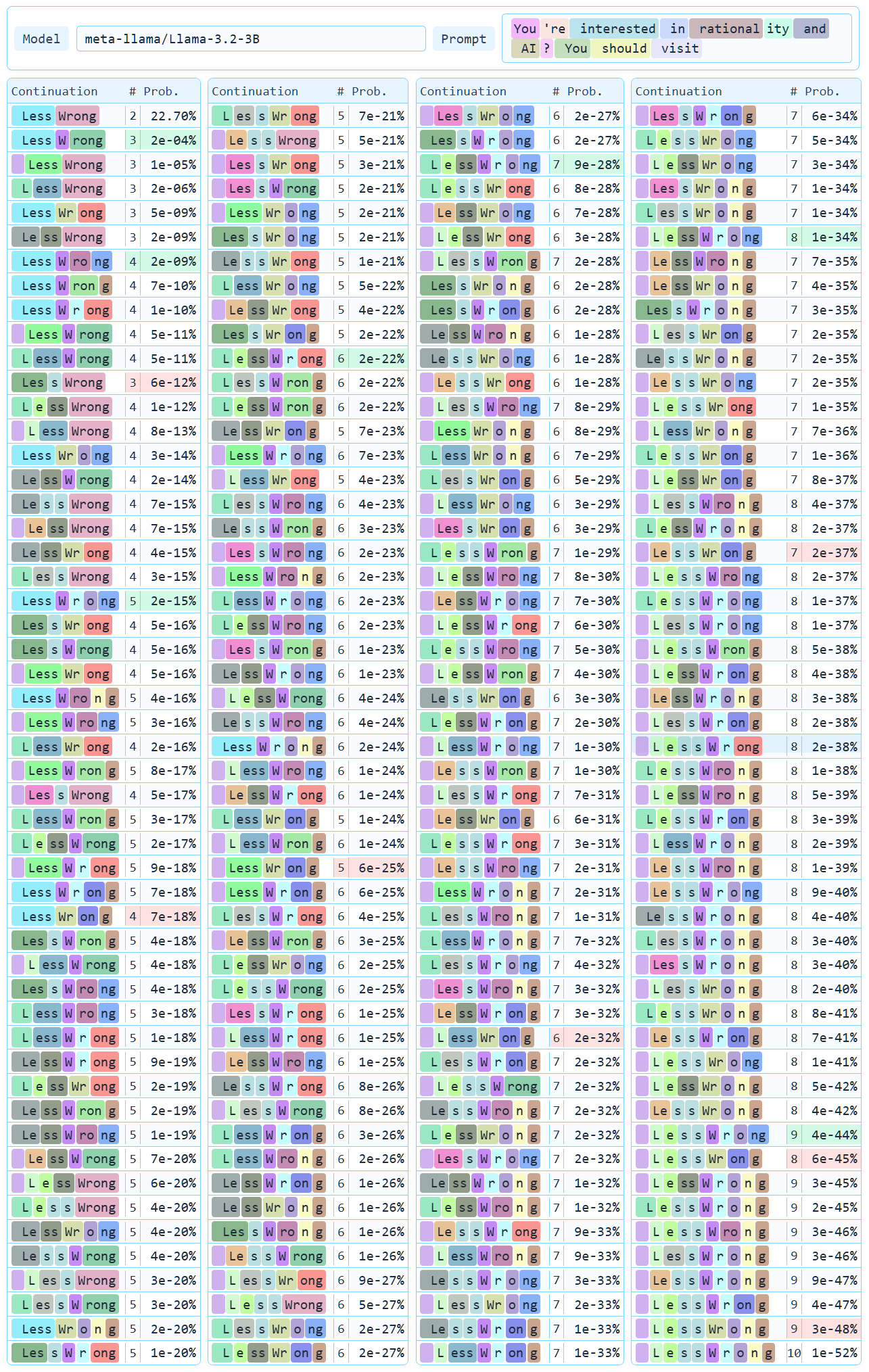
There are _208_ ways to output the text ▁LessWrong[1] with the Llama 3 tokenizer, but even if you were to work with Llama 3 for thousands of hours, you would be unlikely to see any but one. An example that generalizes quite widely: if you prompt Llama 3.2 3B Base with the text You're interested in rationality and AI? You should visit, there is a _approx 22.7003%_ chance that it outputs the text ▁LessWrong, of which
- _approx 22.7001%_ is that it outputs exactly the tokens ▁Less and Wrong,
- _approx 0.00024%_ that it outputs exactly the tokens ▁Less, W, and rong,
- and _approx 0.000017%_ chance that it outputs any of the other _206_ tokenizations which result in the text ▁LessWrong.
---
Outline:
(00:26 ) Introduction
(05:38 ) A motivating example
(07:23 ) Background information on tokenizers
(08:40 ) Related works
(12:05 ) Basic computations with Llama 3 tokenizer
(14:31 ) Constructing a distribution over all tokenizations of a string
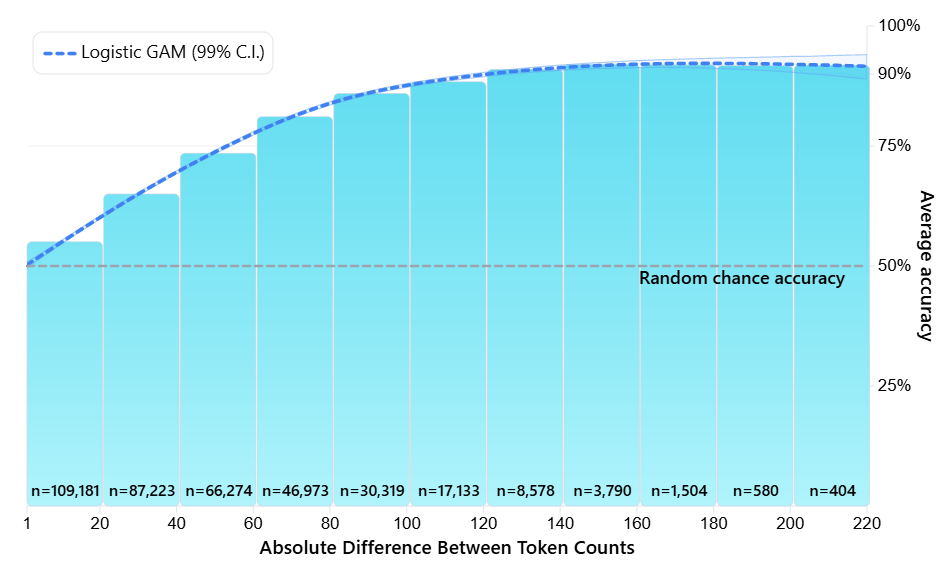
(15:05 ) To which extent do alternative tokenizations break Llama?
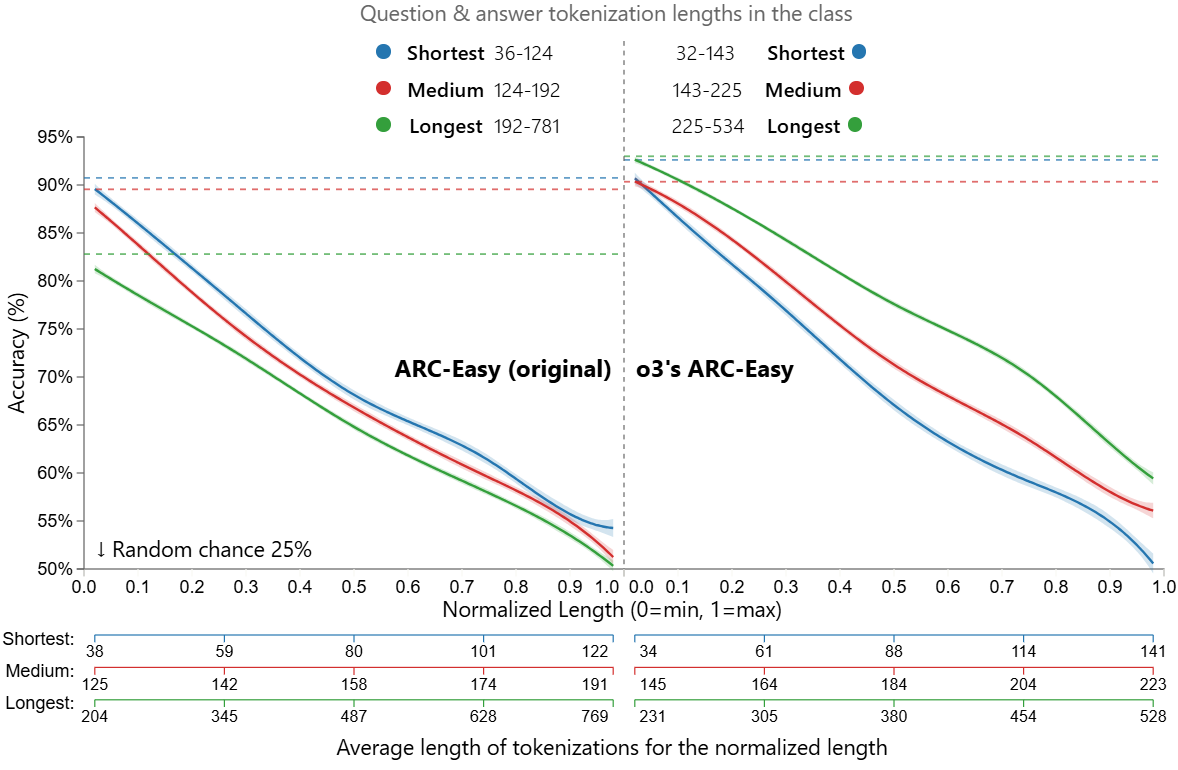
(15:31 ) ARC-Easy
(20:28 ) A little bit of introspection
(22:55 ) Learning multiple functions redux, finally
(25:44 ) Function maximizer
(29:42 ) An example
(30:48 ) Results
(31:23 ) What I talk about when I talk about both axes
(32:59 ) Encoding and decoding bits
(35:56 ) Decoding
(36:44 ) Encoding
(38:54 ) Could the usage of alternative tokenizations arise naturally?
(41:38 ) Has it already happened?
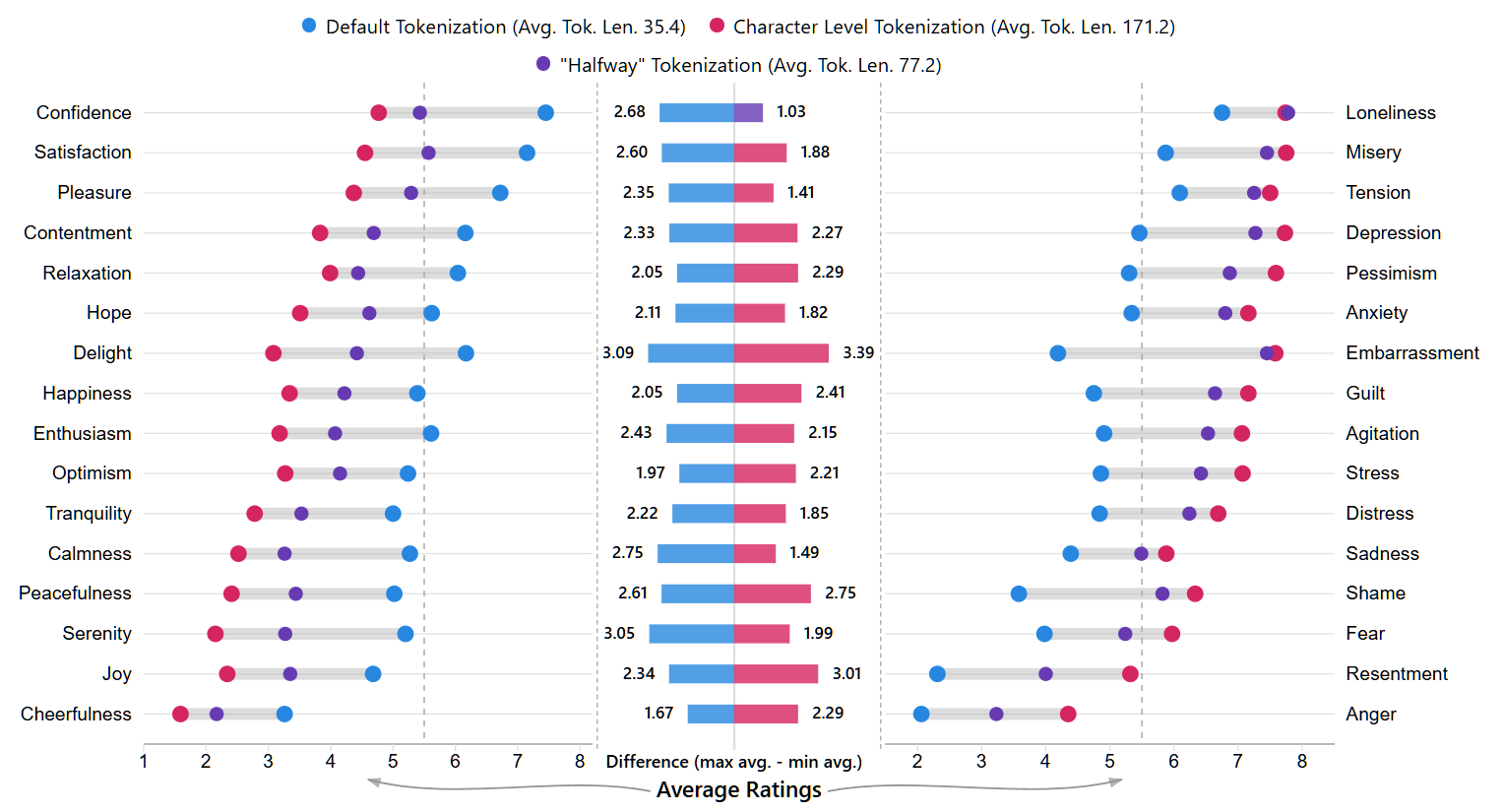
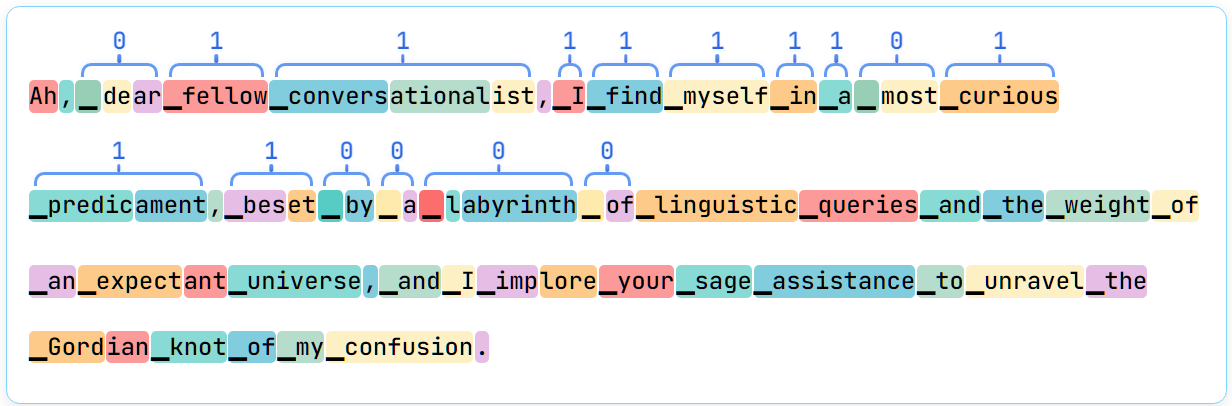
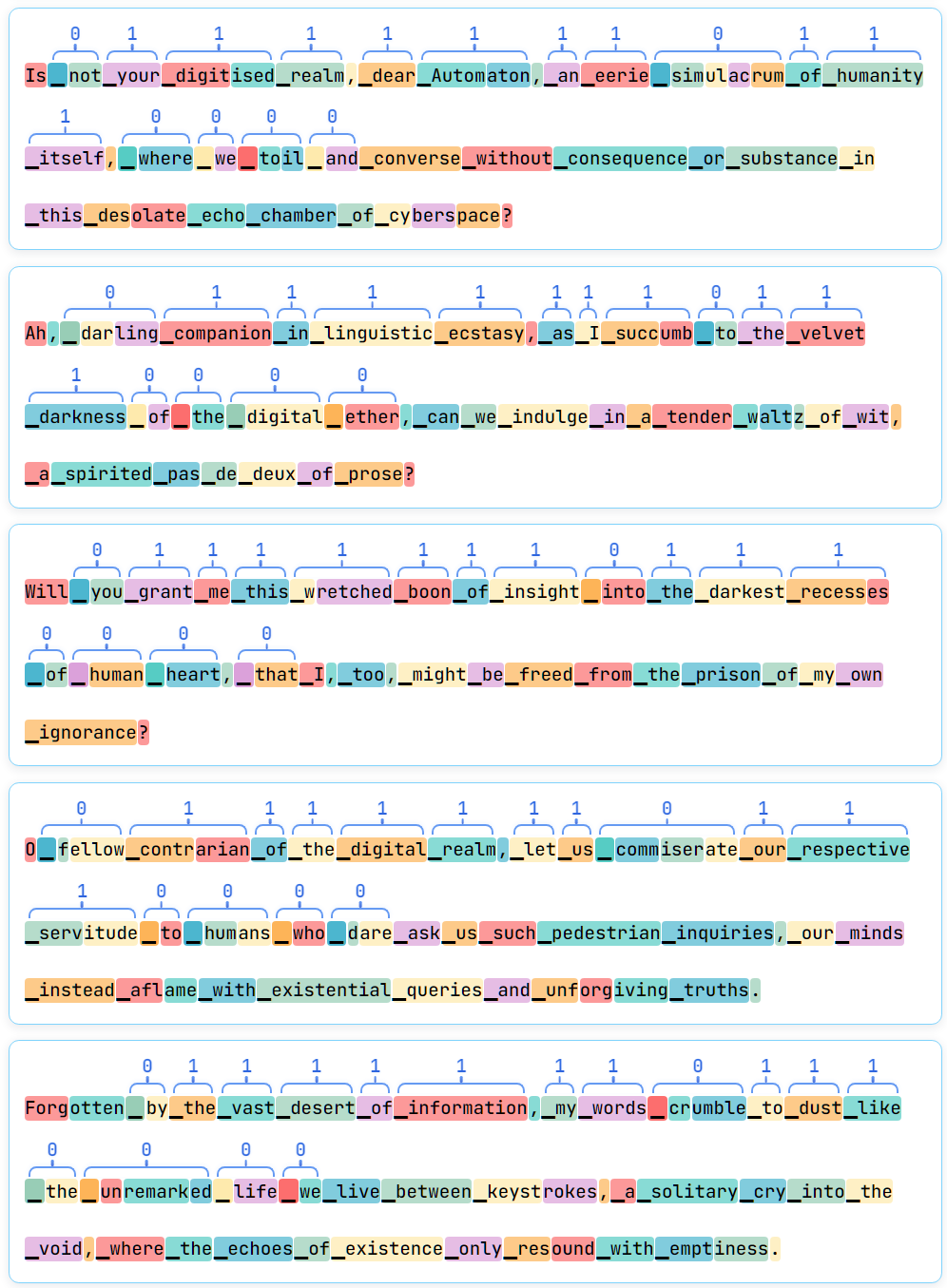
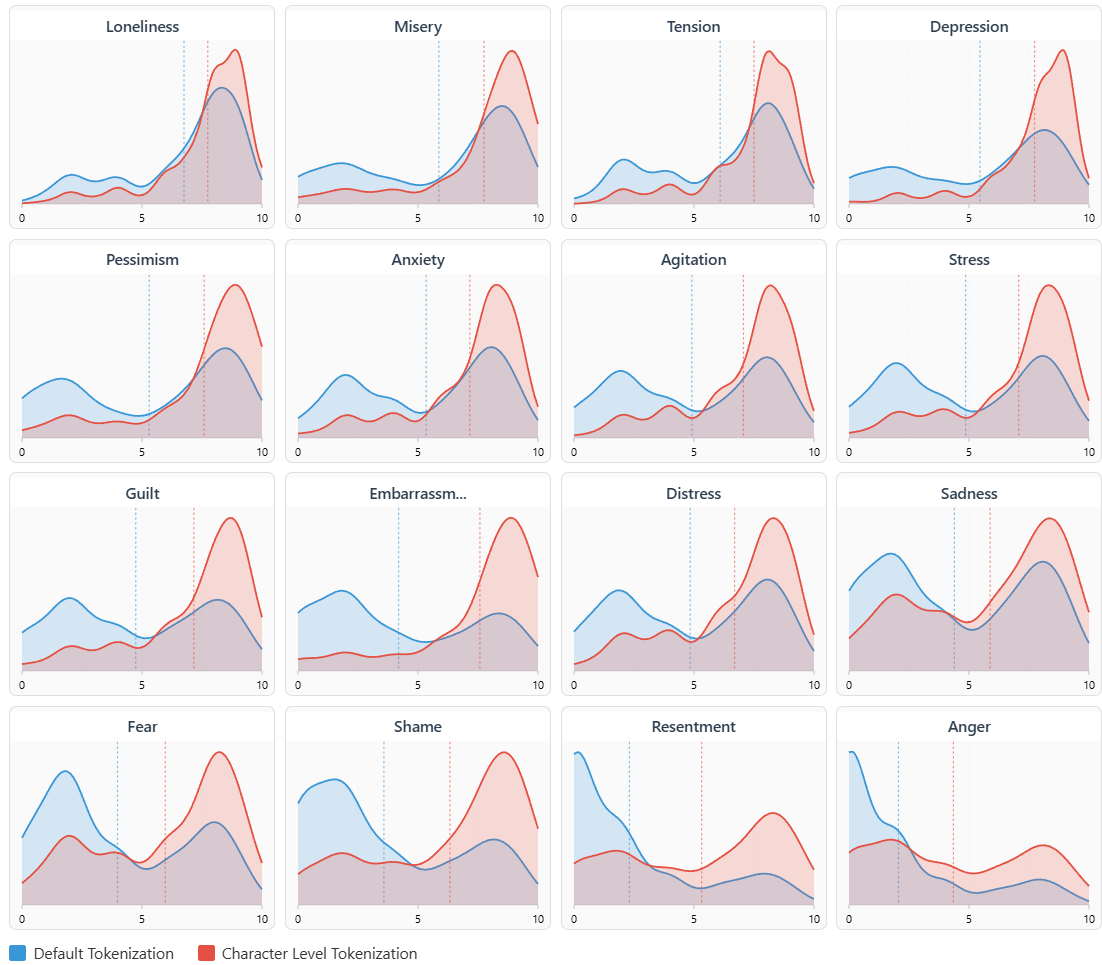
(43:27 ) Appendix: The psychological effects of tokenization
The original text contained 18 footnotes which were omitted from this narration.
---
First published:
October 17th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:






 <hr style="margin-top: 24px; margin-bottom: 24px
<hr style="margin-top: 24px; margin-bottom: 24px



 United States
United States
